
 数据结构
数据结构 网络
网络 关系数据库管理系统
关系数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用 Python 正则表达式从文本中提取日期?
首先,我们需要了解一些正则表达式的基础知识,因为我们会用到它们。在正则表达式中声明模式的方法有很多种,这可能会让它们看起来很复杂,但实际上很简单。正则表达式 是可以用来匹配符合该模式的字符串的模式。您需要阅读以下文章来了解正则表达式是如何工作的。
在学习编码时,您可能会经常需要从给定的文本中提取日期。如果您正在自动化一个Python脚本,并且需要从 CSV 文件中提取特定的数字,如果您是一位数据科学家,并且需要从给定的模式中分离复杂的日期,或者如果您是一位 Python 爱好者,并且想要了解更多关于字符串和数值数据类型的知识,那么您一定会发现这篇文章很有帮助。
预计您已经熟悉正则表达式的基础知识。
示例 1
我们将只使用基本符号来创建日期的正则表达式模式。我们的目标是匹配具有日期、月份、年份或日期、月份和年份的元素的日期,其中日期和月份具有两位数字,年份具有四位数字。现在让我们分步构建模式。
正如您可能猜到的那样,d 将匹配数字。我们需要在其中提供数字 2 来匹配恰好包含 2 位数字的字符串。因此,“d2”将匹配任何仅包含 2 位数字的字符串。日期、月份和年份的模式分别为 d2、d2 和 d4。这三个必须用“/”或“-”连接在一起。
最新的正则表达式模式是“d2”后跟“d2”和“d4”。
现在问题部分已经完成,剩下的任务就容易了。
输入 1
import re #Open the file that you want to search f = open("doc.txt", "r") #Will contain the entire content of the file as a string content = f.read() #The regex pattern that we created pattern = "\d{2}[/-]\d{2}[/-]\d{4}" #Will return all the strings that are matched dates = re.findall(pattern, content)
需要注意的是,我们的正则表达式模式也将提取并非合法的日期,例如 40/32/2019。最终代码必须修改为如下所示
输入 2
import re #Open the file that you want to search f = open("doc.txt", "r") #Will contain the entire content of the file as a string content = f.read() #The regex pattern that we created pattern = "\d{2}[/-]\d{2}[/-]\d{4}" #Will return all the strings that are matched dates = re.findall(pattern, content) for date in dates: if "-" in date: day, month, year = map(int, date.split("-")) else: day, month, year = map(int, date.split("/")) if 1 <= day <= 31 and 1 <= month <= 12: print(date) f.close()
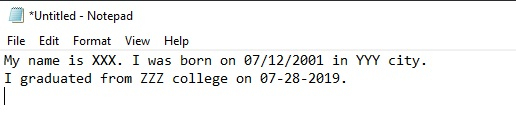
输入文本
例如,如果文本文件的内容如下所示
My name is XXX. I was born on 07/12/2001 in YYY city. I graduated from ZZZ college on 07-28-2019.
输出
07/04/1998 09-05-2019
示例 2
import datetime from datetime import date import re s = "Jason's birthday is on 2002-07-28" match = re.search(r'\d{4}-\d{2}-\d{2}', s) date = datetime.datetime.strptime(match.group(), '%Y-%m-%d').date() print (date)
输出
2002-07-28
结论
通过以上讨论,我们发现了各种Python 函数,用于从给定的文本中提取日期。毫无疑问,正则表达式模块是我们个人最喜欢的。您可能会反驳说,其他方法,例如split() 函数,可以带来更快的执行速度和更简单、更易于理解的代码。但是,如前所述,它不会产生负值(关于方法 2),也不会对没有空格与其和其他字符分隔的浮点数起作用,例如“25.50k”(关于方法 2)。此外,在日志解析方面,速度基本上是一个无用的统计数据。现在您可以理解为什么在所有这些选项中,正则表达式是我的个人首选。

10K+ 次浏览
