
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPScikit Learn 中的聚类性能评估
聚类是一种基本的无监督学习技术,旨在发现未标记数据中的模式或分组。它在数据挖掘、模式识别和客户细分等各个领域都发挥着至关重要的作用。但是,一旦应用了聚类算法,就必须评估其性能并评估所得聚类的质量。
聚类性能评估是理解聚类算法的有效性和可靠性的关键步骤。它包括量化获得的聚类的质量,并提供对其一致性和可分离性的见解。通过评估聚类结果,从业人员可以就算法选择、参数调整和发现的聚类的可解释性做出明智的决策。
在本文中,我们将探讨使用 Python 中的 Scikit-Learn 库进行聚类性能评估的概念。
为了说明聚类性能评估的概念,让我们考虑一个我们对数据集执行聚类的示例。
考虑以下所示的代码。
示例
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
# Generate random points
features, targets = make_blobs(n_samples=500, centers=5, random_state=42, shuffle=False)
# Create the scatter plot
plt.scatter(features[:, 0], features[:, 1])
# Customize plot appearance
plt.title("Random Points Scatter Plot")
plt.xlabel("X-axis")
plt.ylabel("Y-axis")
# Display the plot
plt.show()
输出

K均值
在下面的示例中,我们将使用 k 均值算法。
考虑以下所示的代码。
示例
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
from sklearn.metrics import silhouette_score, calinski_harabasz_score, davies_bouldin_score
# Generate sample data
X, y_true = make_blobs(n_samples=500, centers=4, random_state=42)
# Perform clustering using k-means algorithm
kmeans = KMeans(n_clusters=4, random_state=42)
y_pred = kmeans.fit_predict(X)
# Evaluate clustering performance using metrics
silhouette = silhouette_score(X, y_pred)
calinski_harabasz = calinski_harabasz_score(X, y_pred)
davies_bouldin = davies_bouldin_score(X, y_pred)
# Plot the clustering results
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], marker='x', c='red', label='Centroids')
plt.title('K-means Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.legend()
plt.show()
# Print the evaluation scores
print(f"Silhouette Score: {silhouette:.3f}")
print(f"Calinski-Harabasz Index: {calinski_harabasz:.3f}")
print(f"Davies-Bouldin Index: {davies_bouldin:.3f}")
输出
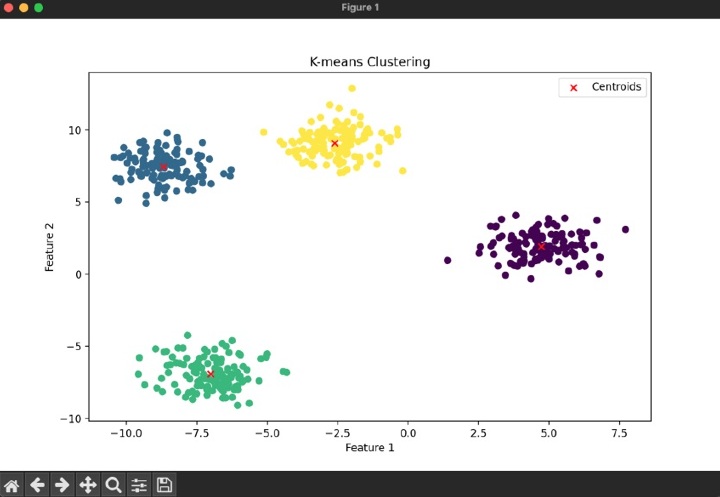
性能评估指标
轮廓系数
轮廓系数是广泛用于评估聚类结果质量的指标。它衡量数据点与其自身集群相比与其他集群的相似程度。该分数范围为 -1 到 1,其中较高的值表示更好的聚类性能。接近 1 的值表明数据点已很好地聚类并被正确分离,而接近 -1 的值表明数据点可能已被分配到错误的集群。在代码中,轮廓系数是使用 silhouette_score() 函数计算的。
考虑以下所示的代码。
示例
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
# Generate sample data
X, _ = make_blobs(n_samples=500, centers=4, random_state=42)
# Perform clustering using K-means algorithm
kmeans = KMeans(n_clusters=4, random_state=42)
y_pred = kmeans.fit_predict(X)
# Calculate the Silhouette Score
silhouette = silhouette_score(X, y_pred)
# Print the Silhouette Score
print("Silhouette Score:", silhouette)
输出
Silhouette Score: 0.7911042588289479
Calinski-Harabasz 指数
Calinski-Harabasz 指数,也称为方差比率准则,是聚类的另一个性能评估指标。它衡量集群间离散度与集群内离散度的比率。较高的 Calinski-Harabasz 指数值表示更好的聚类性能,集群之间具有更高的分离度,而集群内的方差较低。在代码中,Calinski-Harabasz 指数是使用 calinski_harabasz_score() 函数计算的。
考虑以下所示的代码。
示例
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import calinski_harabasz_score
# Generate sample data
X, _ = make_blobs(n_samples=500, centers=4, random_state=42)
# Perform clustering using K-means algorithm
kmeans = KMeans(n_clusters=4, random_state=42)
y_pred = kmeans.fit_predict(X)
# Calculate the Calinski-Harabasz Index
calinski_harabasz = calinski_harabasz_score(X, y_pred)
# Print the Calinski-Harabasz Index
print("Calinski-Harabasz Index:", calinski_harabasz)
输出
Calinski-Harabasz Index: 5742.035759058726
结论
总之,评估聚类算法的性能对于评估其对数据点分组的有效性至关重要。在本文中,我们探讨了两个常用的性能评估指标:轮廓系数和 Calinski-Harabasz 指数。
轮廓系数通过考虑同一集群中样本之间的平均距离以及其他集群中样本的平均距离来衡量集群的质量和分离度。较高的轮廓系数表示更好的聚类性能,具有良好的分离和不同的集群。
Calinski-Harabasz 指数通过考虑集群间离散度与集群内离散度的比率来评估聚类性能。较高的 Calinski-Harabasz 指数表明更好的聚类性能,集群之间具有更高的分离度,而集群内的方差较低。
通过利用这些评估指标,我们可以定量地评估聚类结果的质量,并就聚类算法和参数设置的选择做出明智的决策。

356 次浏览
