
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPJavaScript中的深度优先搜索遍历
DFS 首先访问子节点,然后再访问兄弟节点;也就是说,它在探索广度之前会遍历任何特定路径的深度。在实现该算法时,通常使用堆栈(通常是程序的调用堆栈,通过递归)。
以下是 DFS 的工作方式:
- 访问相邻的未访问顶点。将其标记为已访问。显示它。将其压入堆栈。
- 如果没有找到相邻顶点,则从堆栈中弹出顶点。(它将弹出堆栈中所有没有相邻顶点的顶点。)
- 重复规则 1 和规则 2,直到堆栈为空。
让我们来看一个 DFS 遍历如何工作的示例。
| 步骤 | 遍历 | 描述 |
|---|---|---|
| 1 | 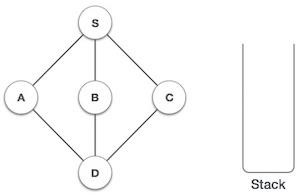 | 初始化堆栈。 |
| 2 | 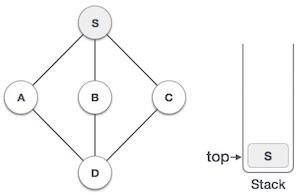 | 将S标记为已访问,并将其放入堆栈中。从S探索任何未访问的相邻节点。我们有三个节点,我们可以选择任何一个。在本例中,我们将按字母顺序选择节点。 |
| 3 | 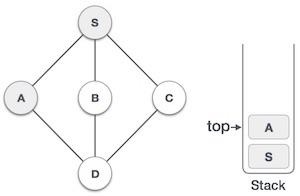 | 将A标记为已访问,并将其放入堆栈中。从A探索任何未访问的相邻节点。S和D都与A相邻,但我们只关注未访问的节点。 |
| 4 | 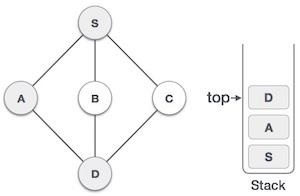 | 访问D,将其标记为已访问,并将其放入堆栈中。这里,我们有B和C节点,它们与D相邻,并且都未访问。但是,我们将再次按字母顺序选择。 |
| 5 | 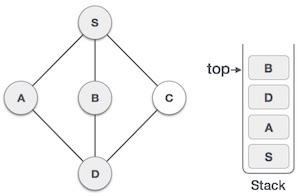 | 我们选择B,将其标记为已访问,并将其放入堆栈中。这里B没有任何未访问的相邻节点。因此,我们将B从堆栈中弹出。 |
| 6 | 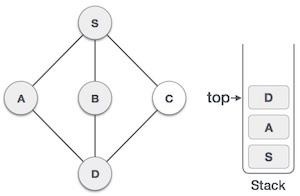 | 我们检查堆栈顶部是否返回到上一个节点,并检查它是否有任何未访问的节点。在这里,我们发现D位于堆栈顶部。 |
| 7 | 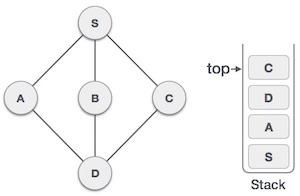 | 现在,D唯一未访问的相邻节点是C。因此,我们访问C,将其标记为已访问,并将其放入堆栈中。 |
由于C没有任何未访问的相邻节点,因此我们继续弹出堆栈,直到找到一个具有未访问相邻节点的节点。在本例中,没有这样的节点,我们继续弹出堆栈直到堆栈为空。让我们看看如何在 JavaScript 中实现它。
示例
DFS(node) {
// Create a Stack and add our initial node in it
let s = new Stack(this.nodes.length);
let explored = new Set();
s.push(node);
// Mark the first node as explored
explored.add(node);
// We'll continue till our Stack gets empty
while (!s.isEmpty()) {
let t = s.pop();
// Log every element that comes out of the Stack
console.log(t);
// 1. In the edges object, we search for nodes this node is directly connected to.
// 2. We filter out the nodes that have already been explored.
// 3. Then we mark each unexplored node as explored and push it to the Stack.
this.edges[t]
.filter(n => !explored.has(n))
.forEach(n => {
explored.add(n);
s.push(n);
});
}
}好吧,这很容易。我们实际上只是将队列换成了堆栈,瞧,我们有了 DFS。这确实是两者之间唯一的区别。DFS 也可以使用递归来实现。但在这种情况下最好避免,因为更大的图意味着我们需要额外的内存来跟踪调用堆栈。
您可以使用以下方法进行测试:
let g = new Graph();
g.addNode("A");
g.addNode("B");
g.addNode("C");
g.addNode("D");
g.addNode("E");
g.addNode("F");
g.addNode("G");
g.addEdge("A", "C");
g.addEdge("A", "B");
g.addEdge("A", "D");
g.addEdge("D", "E");
g.addEdge("E", "F");
g.addEdge("B", "G");
g.DFS("A");输出
这将给出输出。
A D E F B G C

更新于:2020年6月15日
4K+ 次浏览

广告