
 数据结构
数据结构 网络
网络 RDBMS
RDBMS 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言
C语言 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL JavaScript
JavaScript PHP
PHP如何在Python中使用Selenium和Beautifulsoup解析网站?
我们可以在Python中使用Selenium和Beautiful Soup解析网站。Web爬取是一个从网页中提取内容的概念,广泛用于数据科学和指标准备。在Python中,它通过BeautifulSoup软件包实现。
要获得BeautifulSoup和Selenium,我们应该运行命令−
pip install bs4 selenium

让我们抓取页面上出现的以下链接 −

然后调查上述元素的html结构 −
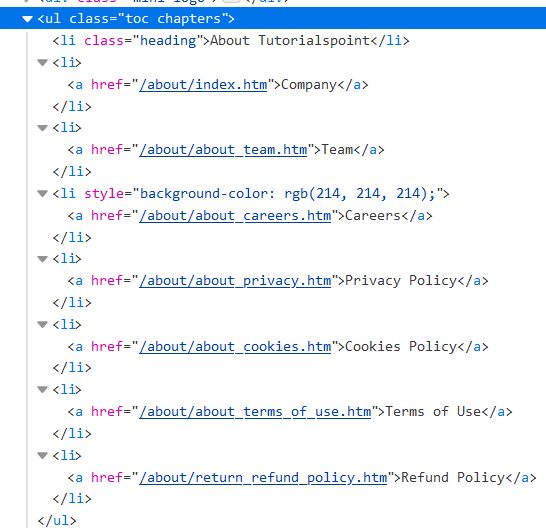
示例
from selenium import webdriver
from bs4 import BeautifulSoup
#path of chromedriver.exe
driver = webdriver.Chrome (executable_path="C:\chromedriver.exe")
#launch browser
driver.get ("https://tutorialspoint.com/about/about_careers.htm")
#content whole page in html format
s = BeautifulSoup(driver.page_source, 'html.parser')
#access to specific ul element with BeautifulSoup methods
l = s.find('ul', {'class':'toc chapters'})
#get all li elements under ul
rs = l.findAll('li')
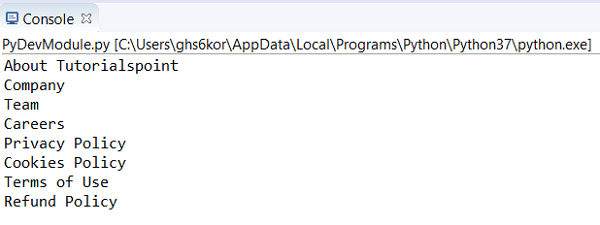
for r in rs:
#get text of li elements
print(r.text)输出

更新于:2021年1月30日
2K+ 次浏览

广告