
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPPython 中的 Vaex 简介
在数据科学领域,我们需要考虑的一个重要方面是处理大型数据集。当涉及到内存管理和执行速度时,处理如此大量的数据确实是一个挑战。
Vaex 是一个专门为解决此类问题而设计的 Python 库。它对于核心外数据帧(类似于 Pandas)特别有用,因为计算仅在必要时才执行。它在大型数据分析、操作和可视化方面提供了良好的解决方案。在这篇文章中,我们将探讨 Vaex 的概念、其功能以及如何在 Python 中使用它。
它利用现代技术的优势,例如多核 CPU 和 SSD,来实现快速有效的计算。
为什么我们需要 Vaex?
Vaex 的延迟评估、虚拟列、内存映射、可视化以及利用表达式系统来实现高效计算和减少内存使用等功能,使我们能够高效快速地处理海量数据集。Vaex 有可能克服其他库(包括 pandas)中发现的各种限制。
Vaex 入门
我们可以通过两种方式安装 vaex:
使用 Pip:pip install --upgrade vaex
使用 Conda:conda install -c conda-forge vaex
安装完成后,您可以按如下方式导入和使用它:
import vaex
读取数据性能
Vaex 读取大型表格数据的速度比 pandas 快得多。让我们通过将大小相同的数据集加载到这两个库中来进行分析。在这里,我将使用 vaex 提供的数据集。如果您想获得良好的结果并观察 Vaex 和 Pandas 的性能差异,请尝试使用大型数据集。从本质上讲,如果您在 Python 中处理大量数据集,那么 Vaex 可能是您的理想库。
Vaex 的性能
我们将使用 **vaex.example()** 命令直接加载 Vaex 提供的以 HDF5 格式存储的内存映射数据集。
示例
import vaex %time df_v=vaex.example() print(df_v.head(5)) df_v.describe()
输出
CPU times: user 10.7 ms, sys: 0 ns, total: 10.7 ms Wall time: 10.7 ms

Pandas 的性能
我们将加载 Vaex 使用的相同数据集,并比较其读取性能。
示例
import pandas as pd
columns = df_v.get_column_names()
data = {}
for column in columns:
data[column] = df_v[column].values
%time df_p = pd.DataFrame(data)
print(df_p.head(5))
df_p.describe()
输出
CPU times: user 4.17 ms, sys: 5.06 ms, total: 9.23 ms Wall time: 13.7 ms
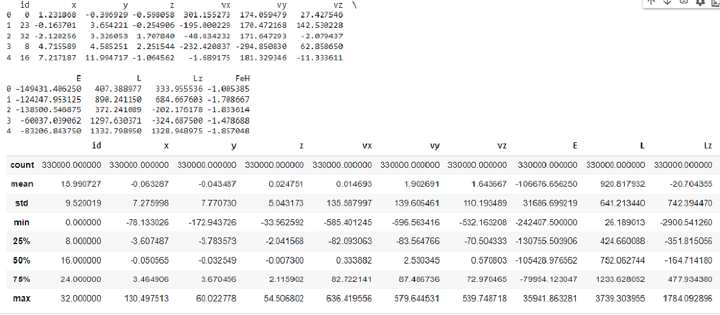
从以上结果可以得出结论,对于相同的数据集,Vaex 的花费时间比 Pandas 少。
示例
print("Size =")
print(df_p.shape)
print(df_v.shape)
输出
Size = (330000,11) (330000,11)
使用 Vaex 进行数据操作/延迟计算
Vaex 使用一种称为“延迟评估”的技术,将操作的评估延迟到需要其结果时。此技术有助于节省计算能力并有效地管理内存。正如我们所知,Vaex 使用表达式系统,这些表达式被延迟评估,这意味着计算仅在必要时才执行。这样可以使计算更快。让我们用一个关于单一计算的示例来测试它:
Pandas DataFrame
示例
%time df_pandas['x'] + df_pandas['y']
输出
CPU times: user 2.15 ms, sys: 10 µs, total: 2.16 ms Wall time: 1.51 ms
Vaex DataFrame
示例
%time df_v.x + df_v.y
输出
CPU times: user 280 µs, sys: 31 µs, total: 311 µs Wall time: 318 µs Expression = (x + y) Length: 330,000 dtype: float32 (expression) ------------------------------------------- 0 0.83494 1 3.49052 2 1.2058 3 9.30084 4 19.2119 ... 329995 2.78315 329996 4.43943 329997 13.3985 329998 1.34032 329999 17.4648
统计性能
Vaex 还可以执行一些操作,例如均值、标准差、计数等。让我们比较 pandas 和 Vaex 在计算统计数据时的性能:
Pandas Dataframe
示例
%time df_p["L"].mean()
输出
Wall time:4.23 ms 920.81793
Vaex DataFrame
示例
%time df_v.mean(df_v.L)
输出
Wall time: 2.49 ms array(920.81803276)
数据过滤
与 Pandas 不同,Vaex 在过滤、选择、清理数据时不会创建内存副本。以数据过滤为例。由于 Vaex 不进行内存复制,因此它使用很少的 RAM 空间即可完成,并且执行速度也会很快。
Pandas Dataframe
示例
%time df_p_filtered = df_p[df_p['x'] > 0]
输出
CPU times: user 13 ms, sys: 1.74 ms, total: 14.7 ms Wall time: 19.7 ms
Vaex Dataframe
示例
%time df_v_filtered = df_v[df_v['x'] > 0]
输出
CPU times: user 1.23 ms, sys: 20 µs, total: 1.25 ms Wall time: 1.27 ms
Vaex 通过在对数据进行单次传递时执行多个计算来展示其效率:
示例
df_v.select(df_v.id < 15,name='less_than') df_v.select(df_v.id >= 15,name='greater_than') %time df_v.mean(df_v.id, selection=['less_than', 'greater_than'])
输出
CPU times: user 19.3 ms, sys: 0 ns, total: 19.3 ms Wall time: 15.5 ms array([ 7.00641717, 23.49799197])
Vaex 中的虚拟列
如果我们希望通过结合表达式在数据帧中创建新列,则虚拟列就会发挥作用。这些列类似于常规列,但不会占用内存空间;相反,它们存储表达式本身。在 Vaex 的世界中,虚拟列和常规列之间没有区别,因为默认的表达式系统平等地对待它们。
示例
%time df_v['new_col'] = df_v['x']**2 print(df_v.head()) df_v.mean(df_v['new_col'])
输出
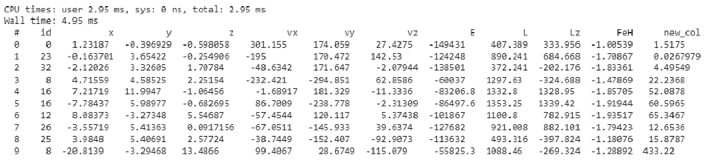
正如您所观察到的,一个新列被添加到表中。
array(52.94398942)
可视化
Vaex 与流行的可视化库(如 Matplotlib 和 Bokeh)无缝集成,使用户能够使用大型数据集创建高度详细且交互式的可视化。
Vaex 是一款功能强大的数据分析库,使用户能够轻松创建令人惊叹的可视化效果,超越了二维表示的界限,深入到 **错综复杂的 3D 景象领域**,即使在 **处理海量** 和 **复杂** 数据集时也是如此。
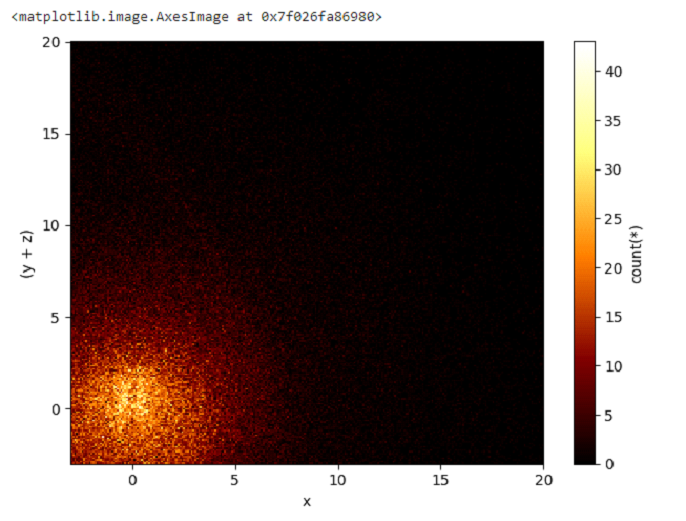
我们将尝试创建一个一维图形:
示例
%time df_v.viz.histogram(df_v.x, limits = [0, 10])
输出

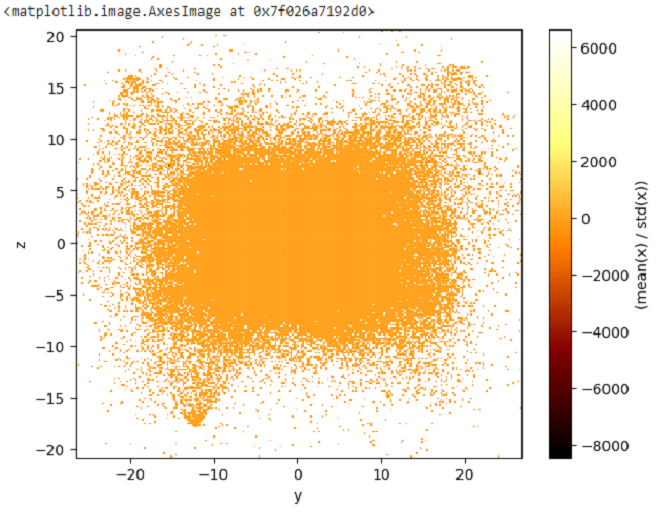
我们将尝试创建一个二维图形:
示例
df_v.viz.heatmap(df_v.x,df_v.y+df_v.z,limits=[-3, 20])
输出
此外,我们还可以添加一些统计表达式来可视化数据。可以使用以下 **语法** 传递表达式:
语法
what=<statistic><Expression> as an argument.
输出
我们还可以将算术运算和 NumPy 函数添加到这些计算中。

190 次查看
