
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP什么是风格生成对抗网络 (StyleGAN)?
简介
人工智能已成为众多行业不可或缺的一部分,计算机生成的图像领域也不例外。Style Generative Adversarial Networks (StyleGAN) 是该领域的一项显著创新。StyleGAN 推动了以前在生成逼真图像方面所能达到的极限,开辟了一个充满创造力和可能性 的世界。在本文中,我们将探讨 StyleGAN 背后的迷人概念及其对计算机图形学的影响。
风格生成对抗网络 (StyleGAN)
生成器网络旨在创建与给定数据集中的真实数据实例类似的合成数据样本。同时,鉴别器的作用是识别呈现给它的图像属于真实数据集还是由生成器生成的。这种来回的相互作用教会生成器如何持续改进其输出,直到它在感知上与真实的示例无法区分。
StyleGAN——由英伟达的研究人员于 2018 年开发,是对传统 GAN 架构的改进,用于生成高质量的合成图像,并对特定属性(例如姿势、头发颜色和面部特征)进行前所未有的控制。StyleGAN 与早期版本的区别在于它能够混合从训练集中提取的风格,同时保留每个图像实例的细粒度细节,方法是使用自适应实例归一化层。这些层负责修改在风格迁移过程中使用的神经网络内不同级别上的均值和标准差值。
训练过程
在使用大量带标签图像数据点以及编码诸如年龄范围或主要颜色等属性的潜在向量的训练迭代过程中,StyleGAN 逐渐学会将图像的不同方面分离出来。然后它能够通过控制这些学习到的特征来生成逼真的输出。
控制的魔力
StyleGAN 的真正力量在于它能够让用户对合成图像的特征进行有意义的控制。通过操纵一组潜在变量,可以确定各种风格参数,例如年龄、头发长度、微笑强度,甚至是不存在的有机属性(例如人类身上不存在的眼睛颜色)。艺术家和设计师发现此功能非常宝贵,使他们能够以无限的可能性释放他们的创造力。
应用和影响
StyleGAN 的多功能性远远超出了艺术领域——从时尚设计到室内装饰和娱乐行业。时尚品牌可以使用它进行虚拟服装试穿或根据个人喜好进行定制推荐。建筑师可以通过探索设计阶段的各种视觉表示来获得潜在的好处,只需通过像 StyleGAN 这样的生成模型动态调整建筑风格或材料即可。
也存在关于真实性的担忧,因为使用 StyleGAN 生成的合成图像可能会将我们带入一个难以轻松辨别真伪的领域。但是,在使用人工智能技术时,伦理考虑和负责任的使用应始终放在首位。
框图
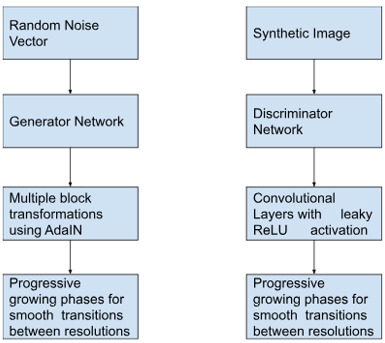
StyleGAN 的核心包含两个关键组件:生成器网络和鉴别器网络。
生成器网络
生成器以随机噪声向量作为输入,根据学习到的模式从头开始生成合成图像。但是,StyleGAN 并非像传统的 GAN 方法那样直接将这些向量映射到整个图像,而是使用自适应实例归一化 (AdaIN) 进行多次块转换。这些块是在每个阶段或分辨率级别上可以独立操纵不同风格的地方。
鉴别器网络
鉴别器试图区分图像是真实的还是由生成器网络生成的伪造的,利用卷积层结合泄漏 ReLU 激活函数来增强识别复杂细节的性能。
这两个网络在多个渐进式增长阶段进行通信,这有助于在训练阶段在分辨率之间平滑过渡。这种独特的技术无疑有助于获得令人印象深刻的结果——在保留微小细节的同时避免了在扩展低分辨率特征时可能出现的潜在伪像。
实时示例——肖像生成
为了更好地理解这项创新技术如何转化为实用性,让我们以使用 StyleGAN 架构作为实时示例来深入探讨肖像生成。
利用面部数据集,StyleGAN 可以生成栩栩如生的肖像,并具有惊人的准确性和多样性,展示了对多个面部属性的显着控制水平。
例如,可以使用固定向量来操纵特定特征,例如年龄增长或性别转换,同时保持逼真的特征。
此外,StyleGAN 的解耦结构可以通过独立更改其潜在空间维度来实现不同级别的修改。这意味着用户可以无缝地修改诸如头发颜色或风格、眼睛形状或颜色之类的方面,而不会影响其他属性——甚至可以精确到雀斑或皱纹等细粒度细节。
结论
随着我们在人工智能驱动的创意应用方面不断进步,风格生成对抗网络彻底改变了人工智能解释艺术表达的方式。从改进计算机图形标准到在多个领域和行业中释放以前无法想象的潜力:在 StyleGAN 支持我们的创意追求的情况下——生动的想象力变成了现实。

94 次浏览
