
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP数据挖掘中的关联分类
数据挖掘是一个有效的过程,包括从大量数据中得出有见地的结论和模式。它的重要性在于能够挖掘出隐藏的信息,发现趋势,并根据恢复的信息做出明智的判断。
一种称为关联分类的关键数据挖掘方法侧重于识别数据集内不同变量之间的联系和相互作用。其目标是在属性之间找到关系和模式,以便预测未来的事件或对新的事件进行分类。关联分类可用于发现有用的模式,帮助企业和组织更好地理解其数据,做出数据驱动的决策,并改进其运营。
此方法提供了一个全面的框架来识别数据中的复杂联系,从而产生有见地的信息和各个行业的潜在进步,包括市场营销、金融、医疗保健等等。在这篇文章中,我们将讨论数据挖掘中的关联分类。让我们开始吧。
理解关联分类
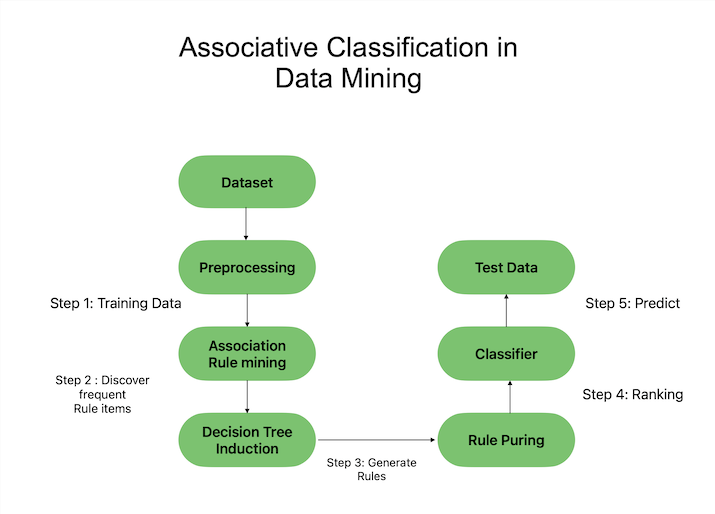
理解关联分类对于实现其在数据挖掘中的全部潜力至关重要。它涉及识别集合中属性之间的相关性和联系,从而简化预测或分类任务。关联分类的基本目标是使用关联规则挖掘技术来识别连接不同变量的模式。
规则创建、规则评估和规则选择通常是该过程的三个主要步骤。创建规则时,它们基于数据集,但是,评估规则时,会评估其质量和重要性。为了提高分类过程的准确性和相关性,规则选择力求剔除不重要或不适用的规则。关联分类的一些好处是其能够处理复杂的数据联系、处理高维数据集以及提供可理解的规则。
其一些缺点包括大型数据集的计算复杂性、对噪声和无关特征的敏感性以及准确性和可解释性之间可能的权衡。然而,了解这些因素使数据分析师能够有效地使用关联分类并根据发现的模式做出决策。
技术和算法
Apriori算法及其在关联分类中的作用
在关联分类中,Apriori算法是一种关键方法,对于识别流行的项目集至关重要。该方法通过迭代技术查找满足最小支持标准的项目集,从而创建属性之间的强相关性。其在关联分类中的主要作用是从中可以派生关联规则的频繁项目集集合。
利用“先验属性”(规定任何非频繁项目集必须具有非频繁子集),该方法有效地修剪搜索空间。
模糊关联规则挖掘及其应用
模糊关联规则挖掘是传统关联规则挖掘的一种发展,它解决了数据中的模糊性和不精确性。在特征包含隶属度而不是二元值的數據集中,它能够发现关系。
在医疗诊断或消费者行为研究等领域,模糊性和模糊性很常见,模糊关联规则挖掘非常有用。此方法使用模糊逻辑来生成规则和识别相关性,从而实现更明智的决策以及识别大型数据集中的模式。
评估和验证
关联规则的度量
为了评估关联分类生成的关联规则的价值和重要性,使用了许多度量标准。提升、支持和趣味性等度量标准经常使用。这些度量标准量化了连接的强度、预测的准确性以及发现的模式的适用性。
用于模型评估的交叉验证和留出方法
交叉验证和留出方法经常用于确认关联分类模型的有效性。通过将数据集分成几个子集,交叉验证允许对不同分区进行重复训练和测试。
相反,留出方法将数据分成训练集和测试集,使用前者构建模型,使用后者评估其性能。
处理不平衡数据集的技术
就类别分布而言,不平衡的数据集可能会使关联分类复杂化。欠采样、过采样和集成程序等方法可用于平衡数据集并减少类别不平衡对模型性能的影响。
结论
在知识发现领域,关联分类至关重要,因为它能够从大型复杂数据集中得出重要的结论和模式。为了更深入地了解潜在的模式和依赖关系,它通过发现特征之间的相关性和相互作用来揭示隐藏的知识。各个领域的应用都说明了其适应性和实用性。在市场营销领域,它对市场购物篮分析至关重要,因为它使公司能够理解消费者的购买模式,推荐相关的商品并改进销售策略。

浏览量:1K+
