
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP数据科学基础
数据科学是一个新兴领域,我们试图从中提取有用的见解和知识数据。数据科学是利用数据来回答问题。如今,数据是每个企业和初创企业最重要的方面,并且随着数据量的指数级增长,数据科学已成为一个越来越重要的领域。数据科学是各种领域的结合,例如统计学和机器学习。
在本文中,我们将讨论数据科学的基础知识以及该领域使用的工具和技术。
数据科学流程
数据科学流程是从数据中获得有意义的见解和知识的一系列步骤。描述该流程的方法有很多种,但最常见的一种是 CRISP-DM,它代表跨行业标准数据挖掘流程。
CRISP-DM(跨行业标准数据挖掘流程)是一种常用的实施数据科学和机器学习项目的策略。它为项目的各个阶段提供了一种结构化的方法,从理解业务问题到部署最终解决方案。
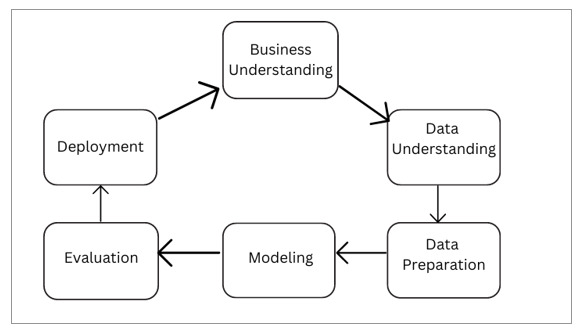
CRISP-DM 包括以下六个步骤:
业务理解 − 第一步也是最重要的一步是理解和识别我们试图解决的问题陈述。这包括诸如识别项目目标、定义范围以及了解我们问题陈述的约束条件等步骤。
数据理解 − CRISP-DM 的第二步是收集问题陈述所需的数据,并探索和分析这些数据。这包括识别数据源、理解数据格式以及探索数据以获取有关数据的见解并识别数据中的任何问题。需要具备有关问题陈述的领域知识,因为领域知识有助于理解结果并获取有关结果的见解。
数据准备 − 第三步是清理、转换和准备数据以进行进一步分析。清理涉及处理数据中的缺失值并用适当的值填充它们。转换涉及将数据转换为适合的格式,以便我们更容易分析数据。
建模 − 第四步是构建一个机器学习模型,该模型可用于进行预测或对数据进行分类。这包括将数据拆分为训练数据和测试数据、在训练数据上训练模型以及评估模型在测试数据上的性能。
评估 − 第五步包括评估模型的性能并在必要时改进模型。这包括在测试数据上测试模型并使用性能指标来评估其性能。
部署 − 最后一步是部署模型并使用它来预测或对新数据进行分类。这包括将模型集成到更大的系统中并在一段时间内监控其性能。
数据科学工具
编程语言 − 数据科学中可以使用多种编程语言,但 Python 和 R 是最流行的语言。Python 是一种通用的编程语言,易于学习,可用于各种领域,如后端开发、桌面应用程序开发和数据科学。Python 拥有大量用于数据科学的内置库。R 是一种专门为数据分析而设计的语言,并具有大量用于统计分析的内置函数。
数据可视化工具 − 数据可视化是将我们的数据分析结果以视觉格式(如图表、图形和地图)表示的过程。它是数据科学中非常重要的工具,因为它可以帮助我们以更直观的方式获取有关数据的见解。一些流行的可视化工具包括 Matplotlib 和 Seaborn。
大数据技术 − 有时我们需要处理大量数据,而使用传统技术无法处理这些数据,因此我们使用大数据技术来进行这些类型的处理。Hadoop、Spark 和 NoSQL 数据库是一些广受欢迎的大数据技术。
机器学习库/框架 − 机器学习库/框架在数据科学和机器学习任务中发挥着至关重要的作用,它们提供了预构建的工具、算法和功能,以简化和加速机器学习模型的开发和部署。这些库/框架(例如 scikit-learn、TensorFlow 和 PyTorch)提供了广泛的算法,用于监督学习和无监督学习,包括回归、分类、聚类和深度学习。
数据科学技术
1. 数据预处理
处理缺失值 − 处理缺失数据的策略,例如插补技术(例如,均值插补、回归插补)或删除不完整样本。
处理缺失值 − 处理缺失数据的策略,例如插补技术(例如,均值插补、回归插补)或删除不完整样本。
数据归一化或标准化 − 将数值特征转换为通用尺度的技术,例如最小-最大缩放或 z 分数标准化。
数据分割 − 将数据集划分为训练集、验证集和测试集,以准确地评估和评估机器学习模型的性能。
2. 监督学习算法
线性回归 − 一种回归技术,用于模拟因变量和一个或多个自变量之间的关系。
逻辑回归 − 一种分类算法,用于模拟二元或分类结果的概率。
支持向量机 (SVM) − 一种功能强大的算法,用于分类和回归任务,它创建超平面以分离类别或预测数值。
随机森林 − 一种集成学习方法,它结合多个决策树来进行预测,常用于分类和回归任务。
3. 无监督学习技术
聚类 − 根据数据点的特征将相似的数据点组合在一起的算法。常见的聚类技术包括k均值聚类、层次聚类和DBSCAN。
降维 − 在保留重要信息的同时减少数据集中的特征或维数的技术。主成分分析(PCA)是一种广泛使用的降维方法。
4. 自然语言处理(NLP)
文本分类 − 将文本文档自动分类到预定义的类别或范畴的任务。
情感分析 − 确定一段文本中表达的情感或情绪基调,常用于分析社交媒体情绪或客户评论。
机器翻译 − 使用机器学习模型和技术将文本从一种语言翻译成另一种语言的过程。
命名实体识别 − 识别和分类文本文档中命名实体(例如,人名、组织名称、地点名称)的任务。
5. 特征工程
缩放 − 将特征重新缩放到标准范围(例如,归一化、标准化),以确保特征的可比性和防止偏差。
编码分类变量 − 将分类数据转换为数值形式,使其适合机器学习算法。
创建衍生特征 − 从现有特征生成新特征,以捕获更多信息或提高模型性能。
处理缺失数据 − 处理数据集中缺失值的技巧,例如插补或删除。
结论
在本文中,我们讨论了数据科学流程以及数据科学工具和技术。在当今世界,公司掌握的最有价值的东西就是数据,因此,公司有必要分析和可视化数据,以找到解决业务问题的方案,帮助他们发展业务。通过掌握数据科学的基础知识,您可以获得可应用于广泛行业和领域的技能。

344 次浏览
