
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP阅读中的眼动控制
眼睛连接大脑的高级处理(语言)和身体的感知运动系统,视觉-眼动系统。平均每人每天眨眼约25万次。我们应该寻找什么目的?这似乎很少涉及任何深思熟虑?眼动追踪设备监测人在阅读时的眼动,这些测量数据通常被用来推断大脑的语言处理过程。这种阅读方法基于语言处理与调节眼动直接相关的假设。

解释阅读时的眼动控制
研究人员在读者阅读一段文字(通常是一句话)时监测他们的眼动。这比其他心理语言学活动更容易,因为它类似于我们每天所做的阅读。在阅读研究中采用最频繁的阅读任务是自然阅读。为了构建眼动语料库,研究人员观察几个人阅读一本长书,并记录他们在阅读时的眼动。眼动追踪也被用来探索如何识别单个单词。在这个练习中,参与者被要求在他们的视野范围内随意地看,同时一个单词在任何地方出现。这个练习使研究人员能够引导参与者的第一次注视,这与正常的阅读不同,在正常的阅读中环境可能会产生影响。
基于逻辑的阅读模型
在理性模型中,阅读行为被概念化为一个过程,用户在这个过程中转移他们的注视点以寻找信息,从而提高他们快速准确地识别单词的能力。特别是,读者使用视觉和语言线索来对文本的身份做出有根据的假设。眼睛会移动到预测单词熵最低的位置。关于阅读过程中眼动调节主要有两种观点。
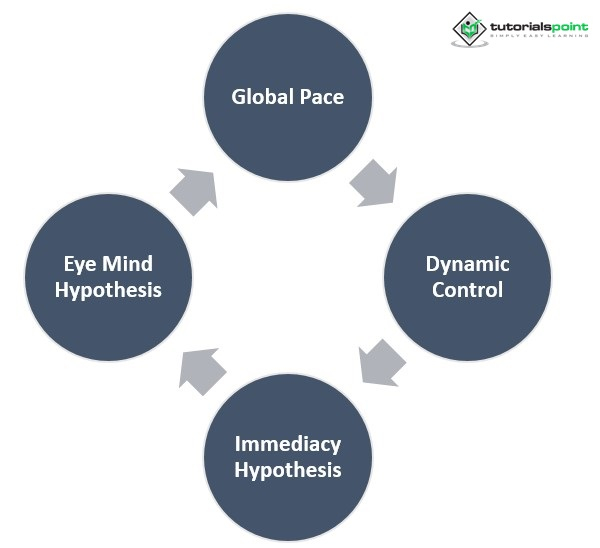
全局速度
在阅读时,我们的眼睛以一种全局“速度”移动,这种速度适应文本的复杂性,而不是反映我们认知系统的即时需求。
动态控制
一个人眼睛的自主移动反映了阅读时任何给定时刻大脑所面临的动态需求。
直接假设
根据直接假设,一个人的注视点将保持在一个给定的单词上,直到所有必要的处理完成。
眼-脑假设
根据“眼-脑”假设,只有当前正在查看的单词才会被大脑解释。这两个“群体”代表了一个假设梯度的两极。有证据支持一种折中理论,即眼动的时机主要由语言处理决定,而位置则由视觉处理和眼动系统特征决定。
测量和方法学基础
眼动追踪系统以毫秒级的精度捕捉用户眼睛注视的位置和时间,然后将这些信息传送到计算机和阴极射线管屏幕上。从读者的角度来看,阅读是一个流畅的过程,眼睛和思想从一个地方到另一个地方移动,不会停顿,除非读者在出声思考或难以理解文本。
大多数人在阅读单词时,注视点主要集中在单词的开头和中心。眼动误差导致注视点的正态分布。
扫视持续时间(以字符为单位)与文本和读者之间的距离以及字体大小无关。因此,字符间隙是正确的度量标准,而不是视角。这是视网膜中央窝和周边视觉之间自然权衡的结果。在进一步阅读时,视野内处理更多的光学信息,但随着视网膜图像变小,这种信息的质量会下降。倒退或跳跃返回到之前阅读的材料,并占所有扫视的10-15%。
倒退表明更高级的语言处理挑战。
在注视期间从视网膜获取的数据会“掩盖”扫视期间视网膜上的数据(模糊)。
根据“幻灯片放映”阅读隐喻,每张“幻灯片”大约会被观看四分之一秒,然后眼睛才会移动到下一张幻灯片。
阅读时注视时间
注视持续时间是在第一次阅读阶段盯着单个单词的总时间。在第一次通读中只注视一次的单词,其第一次注视持续时间较短。

眨眼间隔
跳过单词的几率以百分比表示。随着文本难度的增加,平均注视时间、平均扫视时间和倒退次数普遍呈增加趋势。通常情况下,学生每分钟可以阅读300个单词。由于上下文原因,具有高度可预测性的单词。需要更多关注功能词,并且跳过功能词的频率要高于内容词。
阅读假设
由于“总结”,阅读速度在句子和分句结尾处下降。略读(一种快速阅读)是无效的,因为它会使读者错过重要的细节。由于眼睛注视次数减少,“阅读”速度加快,但所获取信息的质量显著下降。
扫描者具有高视觉密度
研究发现,快速阅读者和“扫描者”的眼睛视觉上是可比的,并且与普通读者相比,“密度”较低。当被问及需要深入理解文本的理解问题时,快速阅读者和“略读者”的表现非常糟糕。
结论
几种与阅读相关的眼动现象具有自然的解释。它们可以通过使用单词识别的典型解释的眼动模型来描述,尽管通过更复杂的方式。这很有帮助,因为它降低了探索不同的视觉和语言知识表示以及不同的眼动策略的计算成本,使理性模型能够更清晰地从主要的眼动模型中脱颖而出,这些模型涉及单词识别的以下信息。我们可以从后验分布中提取度量,或者定量评估理性模型预测眼动现象的能力,并确定其预测是否比主要模型的预测准确得多,或者我们可以直接获得理性模型的眼动策略,并将其行为与人类的行为进行比较。

76 次浏览
