
 数据结构
数据结构 网络
网络 关系型数据库管理系统 (RDBMS)
关系型数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 Seaborn Clustermap 在 Python 中创建分层聚类热图
在数据分析和可视化中,分层聚类热图提供了一个强大的工具来揭示复杂数据集中的模式和关系。本文探讨了如何使用 Python 中的 Seaborn Clustermap 创建分层聚类热图。
为了帮助您理解这个过程,我们将使用代码示例逐步引导您完成该过程。我们将指导您如何对数据进行聚类和可视化,这将为您提供有关每个变量之间关系的重要信息。
什么是使用 Seaborn Clustermap 在 Python 中创建的分层聚类热图?
分层聚类热图是一种可视化技术,用于以热图格式显示数据矩阵,同时还结合了分层聚类。在 Python 中,Seaborn 库提供了一个名为 Clustermap 的实用工具,可以创建分层聚类热图。
您是否曾经处理过大型复杂数据集,并发现难以识别数据中的模式或连接?如果是这样,您并不孤单。这可能是一项艰巨的任务,需要花费大量时间和精力。这就是分层聚类发挥作用的地方。此方法有助于根据其相似性组织热图的行和列,从而使我们能够更好地理解数据不同部分之间的关系。
结果是一个不仅外观吸引人,而且对数据的底层结构具有重要影响的热图。通过将行和列组合在一起,我们可以推断它们如何聚类成相似对象的组或族。这有助于识别从原始数据中无法立即看到的趋势和连接。
使用 Seaborn Clustermap 在 Python 中绘制分层聚类热图
以下是我们将遵循的步骤,以便使用 Seaborn Clustermap 在 Python 中绘制分层聚类热图:
导入必要的库:
使用 `import seaborn as sns` 导入 Seaborn 库。
可选地,使用 `import matplotlib.pyplot as plt` 导入 Matplotlib 库以进行其他自定义。
加载或准备数据集:
使用 `sns.load_dataset()` 加载要可视化的数据集,或以合适的格式准备您自己的数据集。
预处理数据(如果需要):
执行任何必要的数据预处理步骤,例如重塑或聚合数据,以创建适合热图可视化的矩阵。
创建聚类热图:
使用 `sns.clustermap()` 函数,将预处理的数据矩阵作为输入传递。
指定任何其他参数以自定义外观,例如颜色映射(`cmap` 参数)或聚类方法(`method` 参数)。
显示热图:
如果您在步骤 1 中导入了 Matplotlib 库,则使用 `plt.show()` 显示热图。
示例
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# Load the inbuilt dataset
data = sns.load_dataset("flights")
# Data preprocessing
data_pivot = data.pivot("month", "year", "passengers")
# Data analysis
monthly_totals = data.groupby("month")["passengers"].sum()
yearly_totals = data.groupby("year")["passengers"].sum()
# Data processing
processed_data = data_pivot.div(monthly_totals, axis=0)
# Create the clustered heatmap using seaborn clustermap
sns.clustermap(processed_data, cmap="YlGnBu")
# Display the heatmap
plt.show()
输出
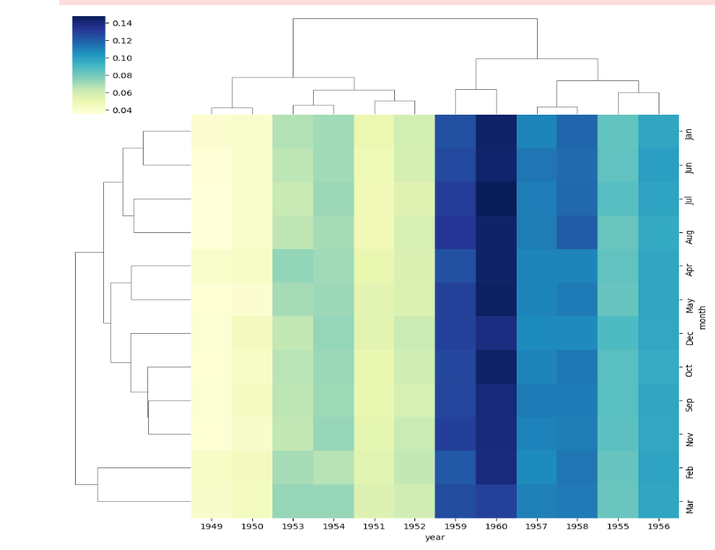
使用 Seaborn Clustermap 在 Python 中自定义分层聚类热图
我们使用 Seaborn 的 clustermap() 函数创建分层聚类热图,并将 pivot_data 矩阵作为输入传递。
我们使用 cmap 参数将颜色映射指定为“YlGnBu”。
提供了其他自定义选项
linewidths=0.5:设置树状图中线条的宽度。
figsize=(8, 6):设置生成的热图图形的大小。
dendrogram_ratio=(0.1, 0.2):调整树状图高度的比例。
自定义热图
我们使用标准的 Matplotlib 函数进一步自定义热图。在此示例中,我们使用 plt.title() 设置标题,并分别使用 plt.xlabel() 和 plt.ylabel() 为 x 轴和 y 轴添加标签。
示例
import seaborn as sns
# Load the inbuilt dataset
data = sns.load_dataset("flights")
# Pivot the data to create a matrix for the heatmap
pivot_data = data.pivot("month", "year", "passengers")
# Create the clustered heatmap using seaborn clustermap
sns.clustermap(pivot_data, cmap="YlGnBu", linewidths=0.5, figsize=(8, 6), dendrogram_ratio=(0.1, 0.2))
# Customize the heatmap
plt.title("Hierarchically-clustered Heatmap - Flights Data")
plt.xlabel("Year")
plt.ylabel("Month")
# Display the heatmap
plt.show()
输出

结论
总之,本文探讨了使用 Seaborn Clustermap 在 Python 中创建分层聚类热图。通过遵循概述的步骤,可以轻松地可视化复杂数据集并发现数据中的模式和关系。
Seaborn 库的 clustermap 函数提供了灵活性和自定义选项,允许用户根据自己的喜好调整颜色方案、线宽、图形大小和树状图比例。

979 次浏览
