
 数据结构
数据结构 网络
网络 关系数据库管理系统(RDBMS)
关系数据库管理系统(RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用TensorFlow可视化模型结果?
应用增强和dropout方法(避免过拟合)后,可以使用'matplotlib'库可视化花卉数据集。这通过'plot'方法完成。
阅读更多: 什么是TensorFlow以及Keras如何与TensorFlow一起创建神经网络?
我们将使用Keras Sequential API,它有助于构建一个顺序模型,用于处理简单的层堆栈,其中每一层只有一个输入张量和一个输出张量。
包含至少一层卷积层的神经网络称为卷积神经网络。我们可以使用卷积神经网络构建学习模型。
使用keras.Sequential模型创建图像分类器,并使用preprocessing.image_dataset_from_directory加载数据。数据高效地从磁盘加载。识别过拟合并应用技术来减轻它。这些技术包括数据增强和dropout。
共有3700张花卉图像。此数据集包含5个子目录,每个类有一个子目录。
它们是雏菊、蒲公英、玫瑰、向日葵和郁金香。
我们使用Google Colaboratory运行以下代码。Google Colab或Colaboratory帮助在浏览器上运行Python代码,无需任何配置,并且可以免费访问GPU(图形处理单元)。Colaboratory构建在Jupyter Notebook之上。
当训练样本数量较少时,模型会从训练样本中的噪声或不需要的细节中学习。这会对模型在新样本上的性能产生负面影响。
当dropout应用于一层时,在训练过程中会随机丢弃该层中的多个输出单元。这是通过将激活函数设置为0来实现的。Dropout技术采用分数作为输入值(例如0.1、0.2、0.4等)。这个数字0.1或0.2基本上表示应用层的10%或20%的输出单元被随机丢弃。
数据增强通过使用随机变换来增强现有样本,从而从现有样本生成额外的训练数据,这些变换将产生看起来可信的图像。以下是一个示例
print("Visualizing the data after performing data augmentation and dropout")
print("Accuracy is being calculated")
acc = history.history['accuracy']
print("Loss is being calculated")
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
print("The results are being visualized")
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()示例
代码来源 −https://tensorflowcn.cn/tutorials/images/classification
Visualizing the data after performing data augmentation and dropout Accuracy is being calculated Loss is being calculated The results are being visualized
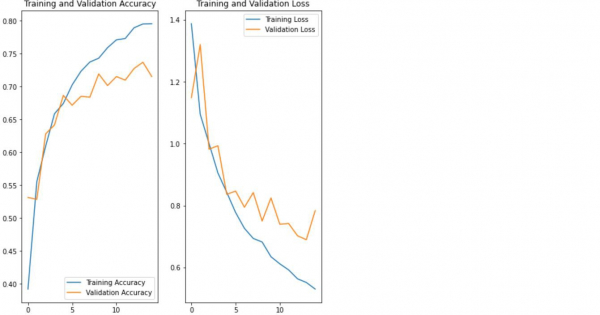
输出
- 解释
- 使用'matplotlib'库可视化数据。
- 计算与模型训练相关的准确性和损失。

AmitDiwan
更新于:2021年2月22日

打印页面