
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用TensorFlow和estimators可视化泰坦尼克号数据集?
可以使用“hist”方法可视化泰坦尼克号数据集,该方法会显示直方图。通过将图形类型指定为“barh”,可以生成水平条形图。
阅读更多: 什么是TensorFlow以及Keras如何与TensorFlow一起创建神经网络?
我们将使用Keras Sequential API,它有助于构建顺序模型,用于处理简单的层堆栈,其中每一层只有一个输入张量和一个输出张量。
TensorFlow Text包含一系列与文本相关的类和操作,可用于TensorFlow 2.0。TensorFlow Text可用于预处理序列建模。
我们使用Google Colaboratory运行以下代码。Google Colab或Colaboratory有助于在浏览器上运行Python代码,无需任何配置,并可免费访问GPU(图形处理单元)。Colaboratory是基于Jupyter Notebook构建的。
Estimator是TensorFlow对完整模型的高级表示。它旨在实现轻松扩展和异步训练。我们将使用tf.estimator API训练逻辑回归模型。该模型用作其他算法的基线。我们使用泰坦尼克号数据集,目标是根据性别、年龄、等级等特征预测乘客的生存情况。
示例
print("Visualizing the data")
print(dftrain.age.hist(bins=20))
print(dftrain.sex.value_counts().plot(kind='barh'))
print(dftrain['class'].value_counts().plot(kind='barh'))
pd.concat([dftrain, y_train], axis=1).groupby('sex').survived.mean().plot(kind='barh').set_xlabel('% survive')代码来源 −https://tensorflowcn.cn/tutorials/estimator/linear
输出
Visualizing the data

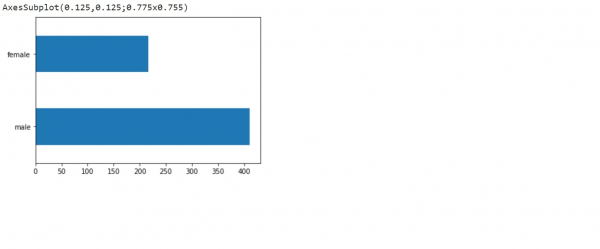
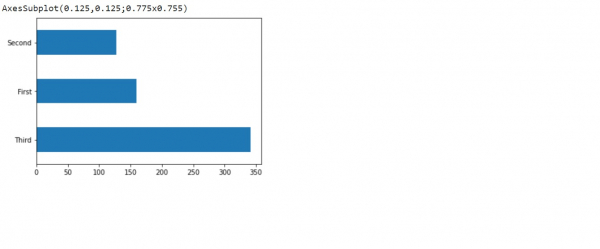
解释
- 可视化泰坦尼克号数据集的各种特征列。
- 它们使用“plot”方法绘制。

更新于:2021年2月22日
63次浏览

广告