
 数据结构
数据结构 网络
网络 关系数据库管理系统(RDBMS)
关系数据库管理系统(RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用TensorFlow确定泰坦尼克号数据集每位乘客所属的类别数据?
TensorFlow可以结合估计器(Estimators),借助“value_counts”方法,确定泰坦尼克号数据集每位乘客所属的类别数据。这些数据以水平条形图的形式可视化。
阅读更多: 什么是TensorFlow以及Keras如何与TensorFlow一起创建神经网络?
我们将使用Keras Sequential API,它有助于构建一个顺序模型,用于处理简单的层堆栈,其中每一层只有一个输入张量和一个输出张量。
包含至少一层卷积层的神经网络被称为卷积神经网络。我们可以使用卷积神经网络来构建学习模型。
我们使用Google Colaboratory运行以下代码。Google Colab或Colaboratory有助于在浏览器上运行Python代码,无需任何配置,并可免费访问GPU(图形处理单元)。Colaboratory构建在Jupyter Notebook之上。
估计器是TensorFlow对完整模型的高级表示。它旨在易于扩展和异步训练。该模型用作其他算法的基线。我们使用泰坦尼克号数据集,目标是根据性别、年龄、阶级等特征预测乘客的生存情况。估计器使用特征列来描述模型如何解释原始输入特征。估计器期望一个数值输入向量,而特征列将有助于描述模型应该如何转换数据集中每个特征。
示例
print("Data about class to which each passenger belong")
dftrain['class'].value_counts().plot(kind='barh')
plt.show()
print("Data about passengers who start their journey from a specific location")
dftrain['embark_town'].value_counts().plot(kind='barh')
plt.show()代码来源 −https://tensorflowcn.cn/tutorials/estimator/boosted_trees
输出

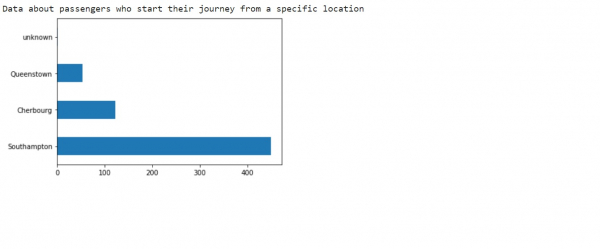
解释
获得了关于每位乘客所属类别的更多信息。
这些信息被绘制在图表上,以便更好地理解数据。

更新于:2021年2月25日
27 次浏览

广告