
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何为监控数据计算百分位数?
介绍
监控在线系统,特别是数据密集型系统,对于持续健康检查、分析和检测停机时间以及提高性能至关重要。基于百分位数的方法是一种非常有效的衡量此类系统行为的技术。让我们看看这种方法。
一般复习
什么是百分位数,为什么它们有用?
在统计学中,表示特定组观察值低于该值的数值称为百分位数或百分点。例如,对于一名学生,如果他/她的分数为 90 百分位,则表示 90% 的学生得分低于他/她。另一个例子可以是,如果 HTTP 请求的响应时间为 90 百分位,则表示 90% 的响应值低于它。
第 25th 百分位数和第 75th 百分位数之间的观察值范围称为四分位距
第 25th 百分位数也称为第 1st 四分位数,第 50th 百分位数称为第 2nd 四分位数,第 75th 百分位数称为第 3rd 四分位数。
当我们想要了解某个值相对于其他观察值的位置时,百分位数非常有用。这可以通过使用值的分布图来实现。与此相关的各种统计术语,如平均值、中位数和众数。
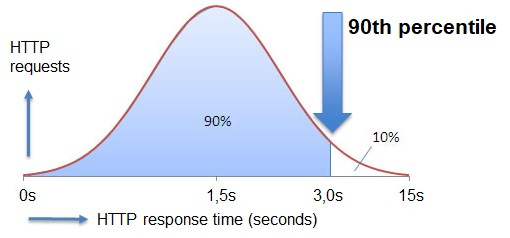
计算百分位数的公式可以表示为
$$\mathrm{n\:=\:\frac{p}{100}\:x\: 𝑁}$$
其中 P = 百分位数,N = 数据集中按升序排序的值的数量,n = 固定序数。
监控数据密集型系统 – 计算百分位数
在监控任务中,我们主要使用百分位数。其他方法,如平均值方法,受异常值的影响很大。在在线系统中,收集器用于收集数据并计算数据的分位数。
一种常见的方法
在 HTTP 请求监控的情况下,请求周期可以划分为分位数。特定分位数,例如 ( φ50 ),可以表示为一个随机值,其概率不能超过 50%。假设 HTTP 请求的数据流包含 n 个元素,那么我们需要找到一个具有 φ 𝑥 𝑛 个元素的元素,其大小可能非常大,例如 1GB。
对此的解决方案是计算数据流的近似分位数。在这种方法中,整个数据流被压缩成一组段。每个段都有固定的宽度 ( 𝑤 ) 和每个段的长度 ( l )
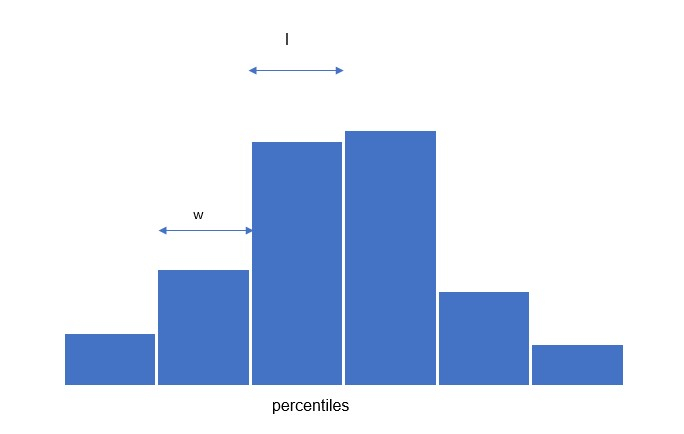
实时捕获数据的百分位数 −
例如,假设我们希望在特定时间点将 1000 个值存储在内存中。
让我们选择大小 k = 100,以及 1 毫秒的最小宽度(分辨率)。
第一个值区间位于 0 到 1 毫秒之间 ( w = 1 毫秒)
并且,
第二个区间 − 1 到 3 毫秒(宽度 = 2 毫秒)
第三个区间 − 3 到 7 毫秒(宽度 = 4 毫秒)
直到第 10th 个区间 − 511 到 1023 毫秒(宽度 = 512 毫秒)
计算
为我们的响应时间创建区间(例如,0 到 100 毫秒、100 毫秒到 200 毫秒、200 毫秒到 400 毫秒...)
计算有多少响应以及每个区间中的响应数量。
将区间计数器相加,直到总和超过总响应的 n%,以计算第 n 个百分位数。
Python 中的伪代码片段
示例
def increment(millis): i = index(millis) if i < len(_limits): _counts[i] += 1 _total+=1; def estimate_percentile(percentile): if percentile < 0.0 or percentile > 100.0 : print("percentile must be between 0.0 and 100.0, was " + percentile) return "Error" if percentile - p.get_percentage() <= 0.0001): return get_limit()
结论
性能监控和健康检查是当今每个数据密集型应用程序的关键。基于百分位数的方法在这一领域取得了丰硕成果,并已被证明是当前场景中的有用工具

712 次查看
