
 数据结构
数据结构 网络
网络 关系型数据库管理系统 (RDBMS)
关系型数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用 Python 将 PDF 文件转换为 Excel 文件?
Python 拥有大量的库来处理不同类型的操作。通过这篇文章,我们将了解如何将 pdf 文件转换为 Excel 文件。Python 中有各种可用的包可以将 pdf 转换为 CSV,但我们将使用 **tabula-py** 模块。**tabula-py** 的大部分是用 Java 编写的,它读取 pdf 文档并将 Python DataFrame 转换为 JSON 对象。
为了使用 **tabula-py**,我们必须在系统中预先安装 Java。现在,要将 pdf 文件转换为 csv,我们将按照以下步骤操作:
首先,在命令行中键入 **pip install tabula-py** 来安装所需的包。
现在使用 read_pdf("文件位置", pages=页码) 函数读取文件。这将返回 DataFrame。
使用 tabula.convert_into(‘pdf文件名’, ‘要保存的文件名.csv’,output_format= "csv", pages= "all") 将 DataFrame 转换为 Excel 文件。它通常将 pdf 文件导出为 excel 文件。
示例
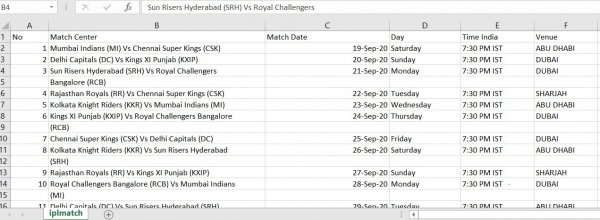
在这个例子中,我们使用了 **IPL 比赛日程文档** 并将其转换为 excel 文件。
# Import the required Module import tabula # Read a PDF File df = tabula.read_pdf("IPLmatch.pdf", pages='all')[0] # convert PDF into CSV tabula.convert_into("IPLmatch.pdf", "iplmatch.csv", output_format="csv", pages='all') print(df)
输出
运行上述代码将把 pdf 文件转换为 excel (csv) 文件。

更新于:2023年8月26日
34K+ 次浏览

广告