
 数据结构
数据结构 网络
网络 关系数据库管理系统
关系数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 语言编程
C 语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用 Python 和 Selenium 获取表格中特定行的数据?
我们可以使用 Selenium 获取表格中特定行的数据。表格的行在 HTML 代码中由 <tr> 标签表示。每一行中的数据都包含在 HTML 中的 <td> 标签内。因此,<td> 标签的父元素始终是 <tr> 标签。
逻辑是获取所有行,我们将使用定位器 xpath,然后使用 **find_elements_by_xpath** 方法。将返回行列表。接下来,我们需要使用 len 方法计算列表的大小。
表格的第一行通常不包含 <td> 标签。在 <td> 标签的位置,使用 <th> 标签。
语法
driver.find_elements_by_xpath("//table/tbody/tr[2]/td")表格标题的 HTML 代码片段如下所示:
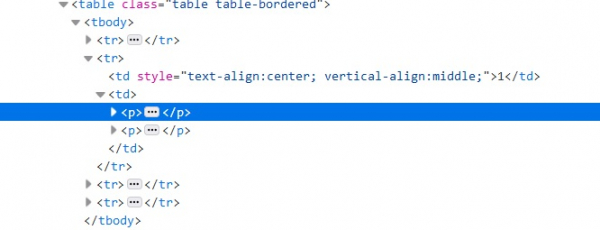
示例
获取第二行数据的编码实现。
from selenium import webdriver
#browser exposes an executable file
#Through Selenium test we will invoke the executable file which will then
#invoke actual browser
driver = webdriver.Chrome(executable_path="C:\chromedriver.exe")
# to maximize the browser window
driver.maximize_window()
#get method to launch the URL
driver.get("https://tutorialspoint.com/plsql/plsql_basic_syntax.htm")
#to refresh the browser
driver.refresh()
# identifying the from row2 having <td> tag
rwdata = driver.find_elements_by_xpath("//table/tbody/tr[2]/td")
# len method is used to get the size of that list
print(len(rwdata))
for r in rwdata:
print(r.text)
#to close the browser
driver.close()

更新于: 2020-07-29
3K+ 阅读量

广告