
 数据结构
数据结构 网络
网络 关系数据库管理系统(RDBMS)
关系数据库管理系统(RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何在使用Python和Selenium的条件下获取工作表中特定行的所有值?
我们可以使用Selenium获取工作表中特定行的所有值,基于一定的条件。Excel是一个以.xlsx扩展名保存的电子表格。一个Excel工作簿包含多个工作表,每个工作表由行和列组成。
在我们访问特定工作表时,它被称为活动工作表。工作表中的每个单元格都有一个唯一的地址,它是行号和列号的组合。
列号从字母A开始,行号从数字1开始。单元格可以包含多种类型的值,它们是工作表的主要组成部分。
要在Python和Selenium中使用Excel,我们需要借助OpenPyXL库。这个库负责读取和写入Excel文件,支持xlsx、xlsm、xltm、xltx等扩展名。
要安装OpenPyXL库,我们需要执行命令 **pip install openpyxl**。这是因为OpenPyXL不是Python的默认库。之后,我们应该在代码中 **import openpyxl**,然后就可以与Excel进行交互了。
要从特定行获取值,首先我们需要通过指定其所在路径来加载整个工作簿。这是通过load_workbook()方法实现的。接下来,我们需要使用active方法来识别所有工作表中的活动工作表。
接下来,我们需要使用max_row方法,它给出已占用行的数量。请注意,此方法应与工作表级别的对象一起使用。
我们需要使用max_column方法,它给出已占用列的数量。请注意,此方法应与工作表级别的对象一起使用。
我们需要从1迭代到已占用最大行数,以遍历所有行。假设我们的目标值位于第1列。因此,我们需要检查该值是否存在。
如果该值存在,我们需要从1迭代到已占用最大列数,以遍历所有列。
最后,要检索该特定行中的所有值,我们需要行号、列号和cell方法(接受行号和列号作为参数)。例如,要指向对应于第2行和第3列的单元格,我们需要写 sheet.cell(row=2,column=3)。
语法
wrkbk = load_workbook("C:\work\SeleniumPython.xlsx")
# to identify the active sheet
sh = wrkbk.active
# identify the number of occupied rows
sh.max_row
# identify the number of occupied rows
sh.max_column示例
获取特定行所有值的代码实现。
import openpyxl
# load excel with its path
wrkbk = load_workbook("C:\work\SeleniumPython.xlsx")
# to get the active work sheet
sh = wrkbk.active
# to print the maximum number of occupied rows in console
print(sh.max_row)
# to print the maximum number of occupied columns in console
print(sh.max_column)
# to get all the values from the excel and traverse through the rows
for r in range(1,max_row+1):
# to check the value in column 1
if(sh.cell(row=r, column=1).value == "2":
# to traverse through the columns
for c in range(2,max_column+1):
# to get all the values
print(sh.cell(row=r, column=c).value)我们引用的Excel数据:
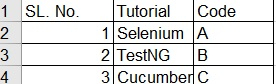

826 次浏览
