
 数据结构
数据结构 网络
网络 关系数据库管理系统
关系数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用 Selenium Python 定位元素?
随着技术的不断变化,为了在网络上呈现内容,经常需要重新设计和重构网页或网站的内容。Selenium 与 Python 的结合是一个很好的组合,有助于从网页中提取所需的内容。Selenium 是一种免费的开源自动化工具,用于在多个平台上评估 Web 应用程序。Selenium 测试脚本可以用多种计算机语言编写,例如 Java、C#、Python、NodeJS、PHP、Perl 等。在这篇 Python Selenium 文章中,通过两个不同的示例,给出了使用 Selenium 定位网页元素的方法。在这两个示例中,都使用了新闻网站来提取内容。
定位要提取的元素 -
打开要从中提取内容的网站。现在按下鼠标右键并打开检查窗口。突出显示网页上的元素或部分,并在检查窗口中查看其 HTML 设计规范。使用这些规范来定位元素。

示例 1:使用 Selenium 和 Python 定位具有特定类名的 div 元素
算法
步骤 1 - 首先下载与 Chrome 版本相同的 Chrome 驱动程序。现在将该驱动程序保存到 Python 文件所在的同一文件夹中。
步骤 2 - 使用 START_URL= “https://www.indiatoday.in/science”。导入 BeautifulSoup 用于解析。使用“class”作为“story__grid”来定位 div 元素。
步骤 3 - 指定网站 URL,并启动驱动程序以获取 URL。
步骤 4 - 使用 BeautifulSoup 解析获取的页面。
步骤 5 - 搜索具有所需类名的 div 标签。
步骤 6 - 提取内容。打印它并将其转换为 html 格式,方法是在 HTML 标签内包含提取的内容。
步骤 7 - 编写输出 HTML 文件。运行程序。打开输出 HTML 文件并检查结果。
示例
from selenium import webdriver
from bs4 import BeautifulSoup
import time
START_URL= "https://www.indiatoday.in/science"
driver = webdriver.Chrome("./chromedriver")
driver.get(START_URL)
time.sleep(10)
def scrape():
temp_l=[]
soup = BeautifulSoup(driver.page_source, "html.parser")
for div_tag in soup.find_all("div", attrs={"class", "story__grid"}):
temp_l.append(str(div_tag))
print(temp_l)
enclosing_start= "<html><head><link rel='stylesheet' " + "href='styles.css'></head> <body>"
enclosing_end= "</body></html>"
with open('restructuredarticle.html', 'w+', encoding='utf-16') as f:
f.write(enclosing_start)
f.write('\n' + '<p> EXTRACTED CONTENT START </p>'+'\n')
for items in temp_l:
f.write('%s' %items)
f.write('\n' + enclosing_end)
print("File written successfully")
f.close()
scrape()
输出
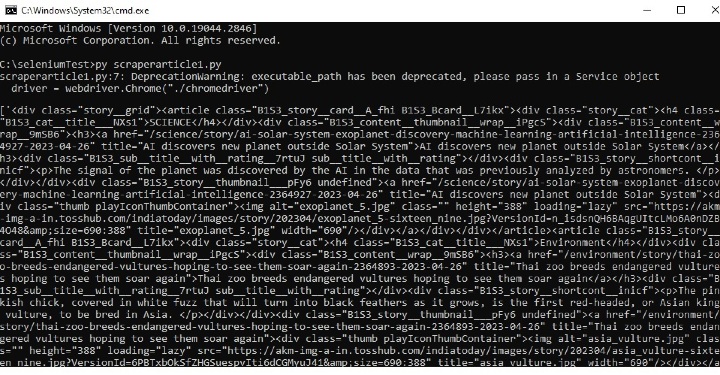
在命令窗口中运行 Python 文件 -
打开 cmd 窗口。首先,我们将在 cmd 窗口中检查输出。然后在浏览器中打开保存的 html 文件以查看提取的内容。
示例 2:使用 Selenium 和 Python 定位具有特定类名的 h4 元素
步骤 1 - 首先下载与 Chrome 版本相同的 chromedriver。现在将该驱动程序保存到 Python 文件所在的同一文件夹中。
步骤 2 - 使用 START_URL= “https://jamiatimes.in/”。导入 BeautifulSoup 用于解析。使用“class”作为“entry-title title”来定位 h4 元素。
步骤 3 - 指定网站 URL,并启动驱动程序以获取 URL。
步骤 4 - 使用 BeautifulSoup 解析获取的页面。
步骤 5 - 搜索具有所需类名的 h4 标签。
步骤 6 - 提取内容。打印它并将其转换为 html 格式,方法是在 HTML 标签内包含提取的内容。
步骤 7 - 编写输出 HTML 文件。运行程序。打开输出 HTML 文件并检查结果。
示例
from selenium import webdriver
from bs4 import BeautifulSoup
import time
START_URL= "https://jamiatimes.in/"
driver = webdriver.Chrome("./chromedriver")
driver.get(START_URL)
time.sleep(10)
def scrape():
temp_l=[]
soup = BeautifulSoup(driver.page_source, "html.parser")
for h4_tag in soup.find_all("h4", attrs={"class", "entry-title title"}):
temp_l.append(str(h4_tag))
enclosing_start= "<html><head><link rel='stylesheet' " + "href='styles.css'></head> <body>"
enclosing_end= "</body></html>"
with open('restructuredarticle2.html', 'w+', encoding='utf-16') as f:
f.write(enclosing_start)
f.write('\n' + '<p> EXTRACTED CONTENT START </p>'+'\n')
for items in temp_l:
f.write('%s' %items)
f.write('\n' + enclosing_end)
print("File written successfully")
f.close()
print(temp_l)
scrape()
输出
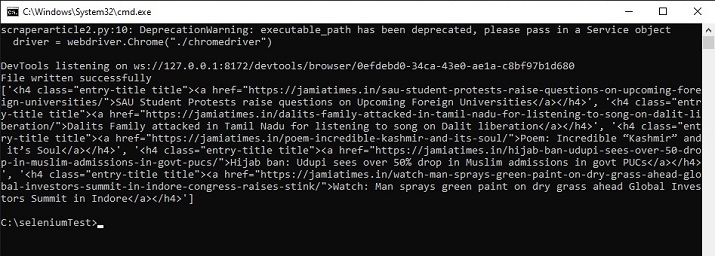
在命令窗口中运行 python 文件 -
打开 cmd 窗口。首先,我们将在 cmd 窗口中检查输出。然后在浏览器中打开保存的 html 文件以查看提取的内容。


在这篇 Python Selenium 文章中,给出了两个不同的示例,展示了如何定位元素进行抓取的方法。在第一个示例中,Selenium 用于定位 div 标签,然后从新闻网站抓取指定的元素。在第二个示例中,定位了 h4 标签,并从另一个新闻网站提取了所需的标题。

891 次浏览
