
 数据结构
数据结构 网络
网络 关系数据库管理系统(RDBMS)
关系数据库管理系统(RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用BeautifulSoup修改HTML?
HTML(超文本标记语言)是互联网的基础。网站使用HTML以结构化的方式创建和显示内容。在许多情况下,需要修改HTML代码以添加新元素、删除不需要的元素或进行其他更改。这就是BeautifulSoup的用武之地。
BeautifulSoup是一个Python库,允许您解析HTML和XML文档。它提供了一个简单的界面来导航和搜索文档树,以及修改HTML代码。在本文中,我们将学习如何使用BeautifulSoup修改HTML。我们将学习使用BeautifulSoup修改HTML的步骤。
使用Beautifulsoup修改HTML的步骤
以下是使用Beautifulsoup修改HTML的完整步骤:
步骤1:安装和导入模块
使用Beautifulsoup修改HTML的第一步是安装Beautifulsoup模块并在之后导入它。我们可以使用pip(Python包管理器)安装该模块。打开终端窗口并运行以下命令:
pip install beautifulsoup4
安装BeautifulSoup后,我们需要将其导入到我们的Python脚本中。我们还将导入requests库,我们将使用它从网页获取HTML代码。
from bs4 import BeautifulSoup import requests
步骤2:获取HTML代码
下一步是获取HTML代码,我们将使用requests库从网页获取HTML代码。在下面的语法中,我们将从tutorialspoint主页获取HTML代码。
url = "https://tutorialspoint.com" response = requests.get(url) html_code = response.content
步骤3:创建BeautifulSoup对象
现在我们有了HTML代码,我们可以创建一个BeautifulSoup对象。这将允许我们导航和修改HTML代码。
soup = BeautifulSoup(html_code, "html.parser")
步骤4:修改HTML
使用BeautifulSoup对象,我们现在可以修改HTML代码。有几种方法可以做到这一点,但我们将介绍一些常见的场景。
添加新元素的语法
# create a new div element
new_div = soup.new_tag("div")
# set the text of the div element
new_div.string = "This is a new div element"
# add the div element to the body tag
soup.body.append(new_div)
删除元素的语法
# find all div elements with class="remove-me"
divs_to_remove = soup.find_all("div", class_="remove-me")
# remove each div element from the soup
for div in divs_to_remove:
div.decompose()
修改属性的语法
# find the first a element with href="https://example.com"
a_tag = soup.find("a", href="https://example.com")
# change the href attribute to "https://new-example.com"
a_tag["href"] = "https://new-example.com"
步骤5:保存HTML
完成修改后,我们将希望将修改后的HTML代码保存到文件中或将其发送回网页。
# write the modified HTML code to a file
with open("modified.html", "w") as f:
f.write(str(soup))
示例1:向网页添加新元素
在下面的示例中,我们将使用BeautifulSoup向网页添加新元素。我们将从网页获取HTML代码,创建一个新的div元素,并将其添加到body标签的末尾。
from bs4 import BeautifulSoup
import requests
# Read the HTML file
with open("myfile.html", "r") as f:
html_code = f.read()
# Creating a BeautifulSoup object
soup = BeautifulSoup(html_code, "html.parser")
# Creating a new div element
mynew_div = soup.new_tag("div")
mynew_div.string = "Welcome to new div element page using BeautifulSoup"
# Adding the new div element to the body tag
soup.body.append(mynew_div)
# Saving the modified HTML code to a file
with open("modifiedfile.html", "w") as f:
f.write(str(soup))
输出
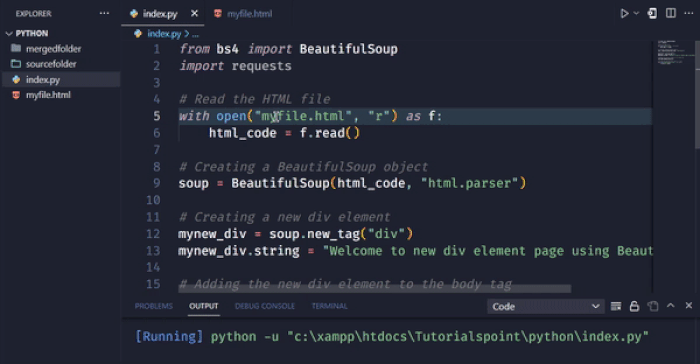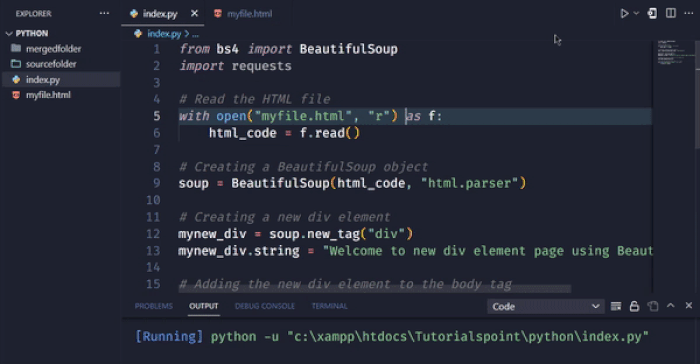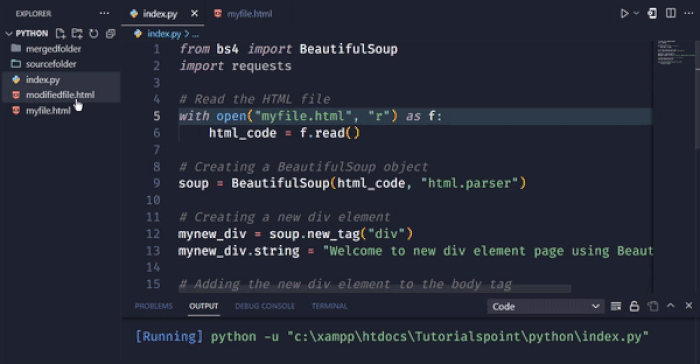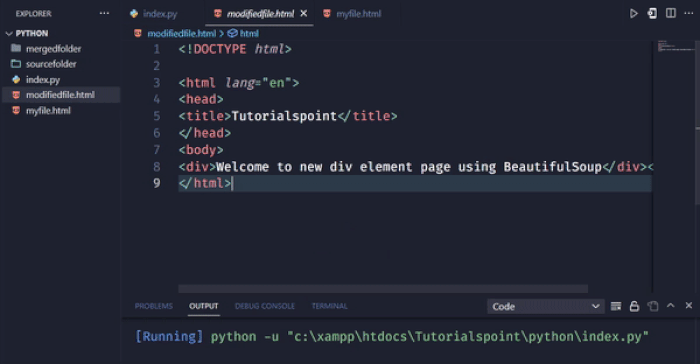
在这个例子中,我们使用new_tag方法创建一个新的div元素。我们使用字符串属性设置div元素的文本。然后,我们使用append方法将新的div元素添加到body标签的末尾。
示例2:从网页删除元素
在下面的示例中,我们将使用BeautifulSoup从网页删除元素。我们将从网页获取HTML代码,找到所有class为“remove-me”的div元素,并将它们从HTML代码中删除。
#imports
from bs4 import BeautifulSoup
import requests
# Read the HTML file
with open("myfile.html", "r") as f:
myhtml_code = f.read()
# creating a BeautifulSoup object
soup = BeautifulSoup(myhtml_code, "html.parser")
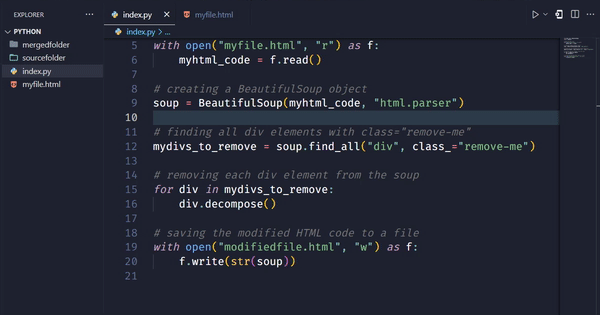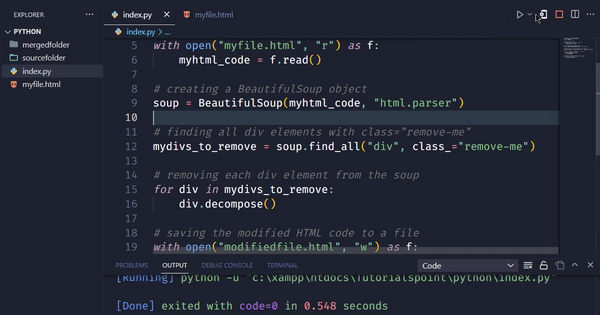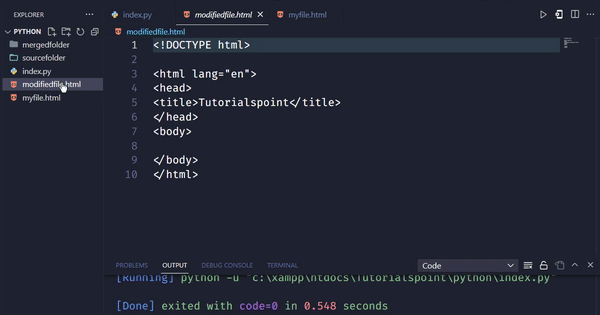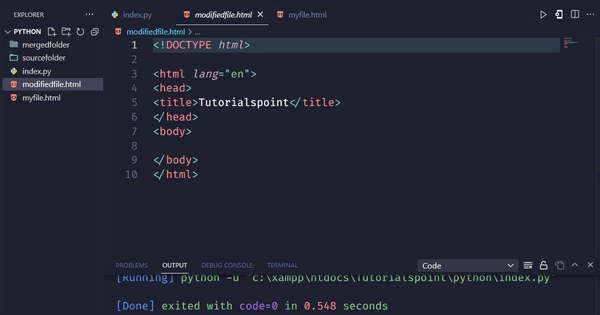
# finding all div elements with class="remove-me"
mydivs_to_remove = soup.find_all("div", class_="remove-me")
# removing each div element from the soup
for div in mydivs_to_remove:
div.decompose()
# saving the modified HTML code to a file
with open("yourmodifiedfile.html", "w") as f:
f.write(str(soup))
输出
在这个例子中,我们使用find_all方法查找所有class为“remove-me”的div元素。我们将它们存储在一个名为divs_to_remove的列表中。然后,我们使用for循环遍历列表,并使用decompose方法从soup中删除每个div元素。最后,我们将修改后的HTML代码保存到文件中。
示例3:修改特定HTML标签的文本
在下面的示例中,我们将修改网页上特定HTML标签的文本。
# Imports
import requests
from bs4 import BeautifulSoup
# Defining the URL of the webpage to fetch
myurl = 'https://tutorialspoint.com'
# Sending a GET request to fetch the HTML code of the webpage
myresponse = requests.get(myurl)
# Read the HTML file
with open("myfile.html", "r") as f:
myhtml_code = f.read()
# Parse the HTML code using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# Finding the first h1 tag on the page and modifying its text using BeautifulSoup
myfirst_modified_h1 = soup.find('h1')
myfirst_modified_h1.string = 'Welcome to tutorialspoint'
# Saving the modified HTML code to a file
with open('yourmodifiedfile.html', 'w') as f:
f.write(str(soup))
输出
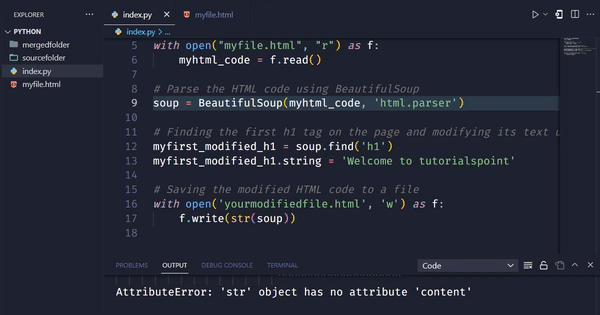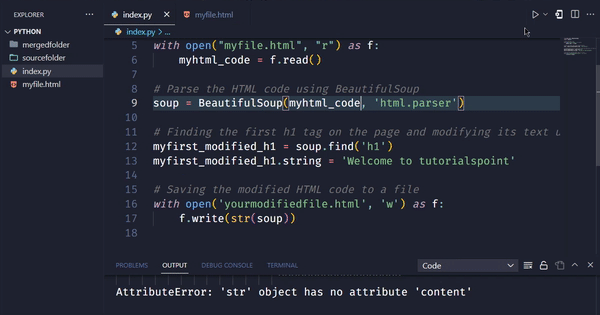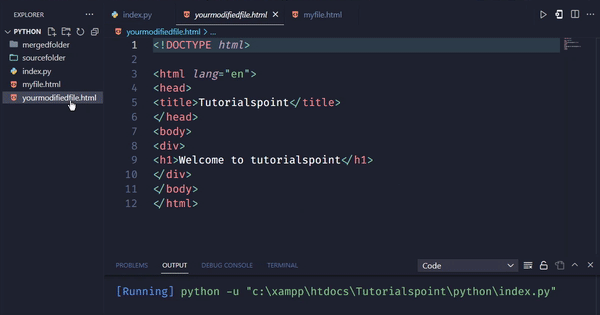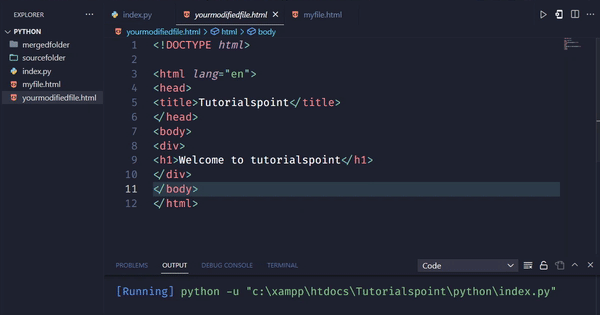
在上面的例子中,我们首先导入必要的库requests和BeautifulSoup。然后,我们定义要修改的网页的URL,并发送GET请求来获取网页的HTML代码。获取代码后,我们创建一个BeautifulSoup对象来解析它,并使用find()方法查找页面上的第一个h1标签,并使用字符串属性修改其文本。
最后,我们使用open()函数和w模式将修改后的HTML代码保存到名为modified.html的文件中。我们将修改后的BeautifulSoup对象传递给write()方法,以将修改后的HTML代码写入文件。
结论
总而言之,修改HTML是Web开发中的常见需求,而BeautifulSoup这个Python库提供了一种简单的方法来解析和修改HTML代码。在本文中,我们学习了如何使用BeautifulSoup修改HTML。我们已经了解了使用Beautifulsoup修改HTML的步骤,包括安装和导入模块、获取HTML代码、创建BeautifulSoup对象、修改HTML代码以及将修改后的HTML代码保存到文件。我们还看到了使用BeautifulSoup修改HTML代码的两个完整的示例——向网页添加新元素和从网页删除元素。使用这些工具和技术,开发人员可以轻松修改HTML代码以满足他们的需求。

2K+浏览量
