
 数据结构
数据结构 网络
网络 RDBMS
RDBMS 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPJava程序:移除给定栈中的重复元素
在本文中,我们将探讨两种在Java中从栈中移除重复元素的方法。我们将比较使用**嵌套循环**的直接方法和使用HashSet的更高效的方法。目标是演示如何优化重复元素移除并评估每种方法的性能。
问题陈述
编写一个Java程序,从栈中移除重复元素。
输入
Stack<Integer> data = initData(10L);
输出
Unique elements using Naive Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Naive Approach: 18200 nanoseconds Unique elements using Optimized Approach: [1, 4, 3, 2, 8, 7, 5] Time spent for Optimized Approach: 34800 nanoseconds
要从给定栈中移除重复元素,我们有两种方法:
生成和克隆随机栈
下面的Java程序首先构建一个随机栈,然后创建它的副本以供进一步使用:
private static Stack initData(Long size) {
Stack stack = new Stack < > ();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i < size; ++i) {
stack.add(random.nextInt(bound) + 1);
}
return stack;
}
private static Stack < Integer > manualCloneStack(Stack < Integer > stack) {
Stack < Integer > newStack = new Stack < > ();
for (Integer item: stack) {
newStack.push(item);
}
return newStack;
}
initData 用于创建一个指定大小的栈,其中包含1到100之间的随机元素。
manualCloneStack 通过复制另一个栈中的数据来生成数据,用于比较两种方法的性能。
使用朴素方法从给定栈中移除重复元素
以下是使用朴素方法从给定栈中移除重复元素的步骤:
- 启动计时器。
- 创建一个空栈来存储唯一元素。
- 使用while循环迭代,直到原始栈为空,弹出顶部元素。
- 使用resultStack.contains(element)检查重复项,查看元素是否已在结果栈中。
- 如果元素不在结果栈中,则将其添加到resultStack。
- 记录结束时间并计算总花费时间。
- 返回结果
示例
以下是使用朴素方法从给定栈中移除重复元素的Java程序:
public static Stack idea1(Stack stack) {
long start = System.nanoTime();
Stack resultStack = new Stack < > ();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.println("Time spent for idea1 is %d nanosecond".formatted(System.nanoTime() - start));
return resultStack;
}
对于朴素方法,我们使用
while (!stack.isEmpty()) resultStack.contains(element)
用于检查元素是否已存在。使用优化方法(HashSet)从给定栈中移除重复元素
以下是使用优化方法从给定栈中移除重复元素的步骤:
- 启动计时器
- 创建一个Set来跟踪已查看的元素(用于O(1)复杂度检查)。
- 创建一个临时栈来存储唯一元素。
- 使用while循环迭代,直到栈为空。
- 从栈中移除顶部元素。
- 为了检查重复项,我们将使用seen.contains(element)来检查元素是否已在集合中。
- 如果元素不在集合中,则将其添加到seen和临时栈中。
- 记录结束时间并计算总花费时间。
- 返回结果
示例
以下是使用HashSet从给定栈中移除重复元素的Java程序:
public static Stack<Integer> idea2(Stack<Integer> stack) {
long start = System.nanoTime();
Set<Integer> seen = new HashSet<>();
Stack<Integer> tempStack = new Stack<>();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.println("Time spent for idea2 is %d nanosecond".formatted(System.nanoTime() - start));
return tempStack;
}
对于优化方法,我们使用
Set<Integer> seen结合使用两种方法
以下是使用上述两种方法从给定栈中移除重复元素的步骤:
- 初始化数据,我们使用initData(Long size)方法创建一个填充有随机整数的栈。
- 克隆栈,我们使用cloneStack(Stack stack)方法创建原始栈的精确副本。
- 使用initData生成初始栈。
- 使用cloneStack克隆此栈。
- 对原始栈应用朴素方法以移除重复元素。
- 对克隆栈应用优化方法以移除重复元素。
- 显示每种方法花费的时间以及两种方法产生的唯一元素。
示例
以下是使用上述两种方法从栈中移除重复元素的Java程序:
import java.util.HashSet;
import java.util.Random;
import java.util.Set;
import java.util.Stack;
public class DuplicateStackElements {
private static Stack<Integer> initData(Long size) {
Stack<Integer> stack = new Stack<>();
Random random = new Random();
int bound = (int) Math.ceil(size * 0.75);
for (int i = 0; i < size; ++i) {
stack.add(random.nextInt(bound) + 1);
}
return stack;
}
private static Stack<Integer> cloneStack(Stack<Integer> stack) {
Stack<Integer> newStack = new Stack<>();
newStack.addAll(stack);
return newStack;
}
public static Stack<Integer> idea1(Stack<Integer> stack) {
long start = System.nanoTime();
Stack<Integer> resultStack = new Stack<>();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!resultStack.contains(element)) {
resultStack.add(element);
}
}
System.out.printf("Time spent for idea1 is %d nanoseconds%n", System.nanoTime() - start);
return resultStack;
}
public static Stack<Integer> idea2(Stack<Integer> stack) {
long start = System.nanoTime();
Set<Integer> seen = new HashSet<>();
Stack<Integer> tempStack = new Stack<>();
while (!stack.isEmpty()) {
int element = stack.pop();
if (!seen.contains(element)) {
seen.add(element);
tempStack.push(element);
}
}
System.out.printf("Time spent for idea2 is %d nanoseconds%n", System.nanoTime() - start);
return tempStack;
}
public static void main(String[] args) {
Stack<Integer> data1 = initData(10L);
Stack<Integer> data2 = cloneStack(data1);
System.out.println("Unique elements using idea1: " + idea1(data1));
System.out.println("Unique elements using idea2: " + idea2(data2));
}
}
输出
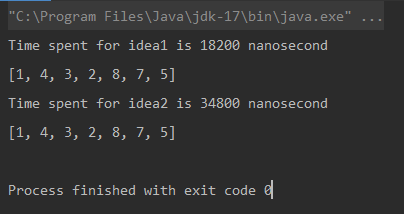
比较
* 测量单位为纳秒。
public static void main(String[] args) {
Stack<Integer> data1 = initData(<number of stack size want to test>);
Stack<Integer> data2 = manualCloneStack(data1);
idea1(data1);
idea2(data2);
}
| 方法 | 100个元素 | 1000个元素 | 10000个元素 |
100000个元素 |
1000000个元素 |
| 方法1 | 693100 |
4051600 |
19026900 |
114201800 |
1157256000 |
| 方法2 | 135800 |
681400 |
2717800 |
11489400 |
36456100 |
如观察到的,方法2的运行时间短于方法1,因为方法1的复杂度为O(n²) ,而方法2的复杂度为O(n)。因此,当栈的数量增加时,计算所花费的时间也会相应增加。

更新于:2024年8月14日
208 次浏览

广告