
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用正则表达式统计Python程序中大写字母、小写字母、特殊字符和数字字符个数的程序
正则表达式,通常简称为re或Regex,是用于操作和搜索文本模式的强大工具。在Python中,正则表达式是使用re模块实现的。正则表达式是一系列字符,用于定义搜索模式。该模式用于匹配和操作文本字符串,这对于数据清洗、解析和验证等任务非常有用。
为了使用正则表达式(regex)统计字符串中大写字母、小写字母、特殊字符和数字字符的个数,我们可以使用特定的模式来匹配和统计所需的字符。
以下是使用正则表达式统计大写字母、小写字母、特殊字符和数字字符个数的模式及其解释:
大写字母:
模式:[A-Z]
解释:模式[A-Z]匹配从A到Z的任何大写字母。连字符-指定字符范围。因此,此模式匹配输入字符串中的任何大写字母。
小写字母:
模式:[a-z]
解释:模式[a-z]匹配从a到z的任何小写字母。与大写字母类似,此模式捕获输入字符串中的任何小写字母。
特殊字符:
模式:[A-Za-z0-9]
解释:模式[^A-Za-z0-9]匹配任何不是大写字母、小写字母或数字的字符。方括号[]内的脱字符^表示否定。因此,此模式匹配不在A-Z、a-z或0-9范围内的任何特殊字符。
数字:
模式:[0-9]
解释:该模式匹配从0到9的任何数字。
为了统计每个类别的出现次数,我们可以使用Python中re模块的re.findall()函数。此函数搜索输入字符串中模式的所有不重叠的出现,并将其作为列表返回。生成的列表的长度给出了出现次数。
输入输出场景
让我们探索一些输入输出场景,以统计给定字符串中大写字母、小写字母、特殊字符和数字字符的个数。
场景1:
Input string: Hello World! Output: Uppercase letters: 2 Lowercase letters: 8 Special characters: 1 Numeric values: 0
输入字符串“Hello World!”包含2个大写字母(H和W)、8个小写字母(e、l、l、o、o、r、l、d)、1个特殊字符(!)和0个数字。
场景2:
Input string: @#Hello1234#@ Output: Uppercase letters: 1 Lowercase letters: 4 Special characters: 4 Numeric values: 4
输入字符串“@#Hello1234#@”包含1个大写字母(H)、4个小写字母(e、l、l、o)、4个特殊字符(@、#、#、@)和4个数字(1、2、3、4)。
示例
让我们举个例子来统计给定字符串中大写字母、小写字母、特殊字符和数字字符的个数。
import re
def count_characters(input_string):
uppercase_count = len(re.findall(r'[A-Z]', input_string))
lowercase_count = len(re.findall(r'[a-z]', input_string))
special_count = len(re.findall(r'[^A-Za-z0-9]', input_string))
numeric_count = len(re.findall(r'[0-9]', input_string))
return uppercase_count, lowercase_count, special_count, numeric_count
# define the input string
input_str = 'Tutor1als!p0int'
upper, lower, special, numeric = count_characters(input_str)
print("Uppercase letters:", upper)
print("Lowercase letters:", lower)
print("Special characters:", special)
print("Numeric values:", numeric)
输出
Uppercase letters: 1 Lowercase letters: 11 Special characters: 1 Numeric values: 2
示例
在这个例子中,我们将统计文本文件中大写字母、小写字母、特殊字符和数字字符的个数。以下是文本文件中存在的数据:
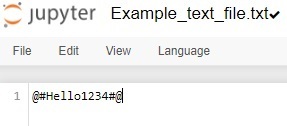
import re
def count_characters(filename):
with open(filename, 'r') as file:
for line in file:
uppercase_count = len(re.findall(r'[A-Z]', line))
lowercase_count = len(re.findall(r'[a-z]', line))
special_count = len(re.findall(r'[^A-Za-z0-9]', line))
numeric_count = len(re.findall(r'[0-9]', line))
return uppercase_count, lowercase_count, special_count, numeric_count
# Provide the path of the text file
file = 'Example_text_file.txt'
# Call the function to count Uppercase, Lowercase, special character and numeric values
upper, lower, special, numeric = count_characters(file)
print("Uppercase letters:", upper)
print("Lowercase letters:", lower)
print("Special characters:", special)
print("Numeric values:", numeric)
输出
Uppercase letters: 1 Lowercase letters: 4 Special characters: 4 Numeric values: 4

626 次查看
