
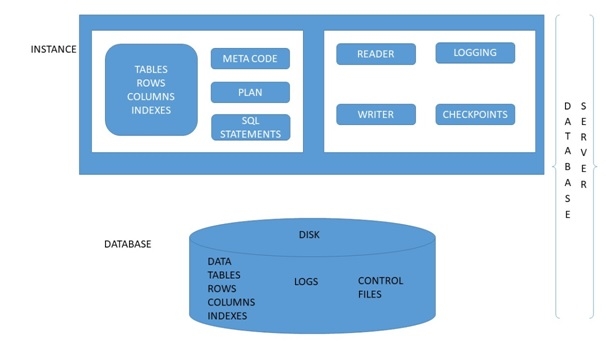
 数据结构
数据结构 网络
网络 RDBMS
RDBMS 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 语言编程
C 语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP关系型数据库管理系统 (RDBMS)
关系数据库设计 (RDD) 模型将信息和数据组织成一组包含行和列的表。关系/表的每一行表示一条记录,每一列表示数据的某个属性。结构化查询语言 (SQL) 用于操作关系数据库。关系数据库的设计由四个阶段组成,其中数据被建模成一组相关的表。这些阶段包括:
- 定义关系/属性
- 定义主键
- 定义关系
- 规范化
关系数据库在组织数据和执行事务方面与其他数据库不同。在 RDD 中,数据被组织成表,所有类型的数据访问都通过受控事务执行。关系数据库设计满足数据库设计所需的 ACID(原子性、一致性、完整性和持久性)属性。关系数据库设计要求在应用程序中使用数据库服务器来处理数据管理问题。
关系数据库设计过程
数据库设计更像是一门艺术而不是科学,因为您必须做出许多决策。数据库通常会被定制以适应特定的应用程序。没有两个定制的应用程序是相同的,因此,也没有两个数据库是相同的。在做出这些设计决策时,会提供一些指导原则(通常是关于“不要做什么”而不是“做什么”),但最终的选择权在于设计者。
步骤 1 - 定义数据库的目的(需求分析)
- 收集需求并定义数据库的目标。
- 草拟示例输入表单、查询和报表通常会有所帮助。
步骤 2 - 收集数据,组织成表并指定主键
- 确定数据库的目的后,收集需要存储在数据库中的数据。将数据划分为基于主题的表。
- 选择一列(或几列)作为所谓的“主键”,它唯一地标识每一行。
步骤 3 - 创建表之间的关系
一个由独立且不相关的表组成的数据库几乎没有用处(您可以考虑使用电子表格)。关系数据库的强大之处在于可以在表之间定义关系。设计关系数据库最关键的方面是识别表之间的关系。关系类型包括:
- 一对多
- 多对多
- 一对一
一对多
在“课程花名册”数据库中,一位老师可以教授零个或多个课程,而一个课程由一位(且仅一位)老师教授。在“公司”数据库中,一位经理可以管理零个或多个员工,而一位员工由一位(且仅一位)经理管理。在“产品销售”数据库中,一位客户可以下多个订单;而一个订单是由一位特定客户下的。这种关系被称为一对多。
一对多关系不能在一个表中表示。例如,在“课程花名册”数据库中,我们可以从一个名为 Teachers 的表开始,其中存储有关教师的信息(例如姓名、办公室、电话和电子邮件)。为了存储每位教师教授的课程,我们可以创建列 class1、class2、class3,但立即面临一个问题,即创建多少列。另一方面,如果我们从一个名为 Classes 的表开始,其中存储有关课程的信息,我们可以创建其他列来存储有关(一个)教师的信息(例如姓名、办公室、电话和电子邮件)。但是,由于一位教师可以教授许多课程,因此其数据将在 Classes 表的许多行中重复。
为了支持一对多关系,我们需要设计两个表:例如,一个 Classes 表来存储有关课程的信息,classID 作为主键;以及一个 Teachers 表来存储有关教师的信息,teacherID 作为主键。然后,我们可以通过在 Classes 表(“多”端或子表)中存储 Teacher 表(“一”端或父表)的主键(即 teacherID)来创建一对多关系,如下所示。
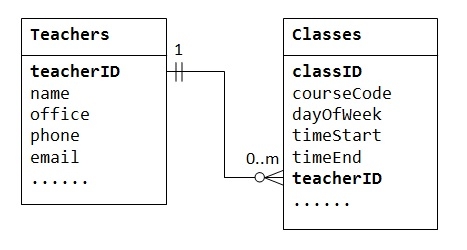 子表 Classes 中的列 teacherID 被称为外键。子表的外键是父表的主键,用于引用父表。
子表 Classes 中的列 teacherID 被称为外键。子表的外键是父表的主键,用于引用父表。
多对多
在“产品销售”数据库中,客户的订单可能包含一个或多个产品;并且一个产品可以出现在多个订单中。在“书店”数据库中,一本书由一个或多个作者撰写;而一个作者可以撰写零个或多个书籍。这种关系被称为多对多。
让我们以“产品销售”数据库为例。我们从两个表开始:Products 和 Orders。Products 表包含有关产品的信息(例如名称、描述和库存数量),productID 作为其主键。Orders 表包含客户的订单(customerID、dateOrdered、dateRequired 和状态)。同样,我们不能在 Orders 表中存储订购的商品,因为我们不知道为商品保留多少列。我们也不能在 Products 表中存储订单信息。
为了支持多对多关系,我们需要创建一个第三个表(称为连接表),例如 OrderDetails(或 OrderLines),其中每一行表示特定订单的商品。对于 OrderDetails 表,主键包含两列:orderID 和 productID,它们唯一地标识每一行。OrderDetails 表中的列 orderID 和 productID 用于引用 Orders 和 Products 表,因此它们也是 OrderDetails 表中的外键。
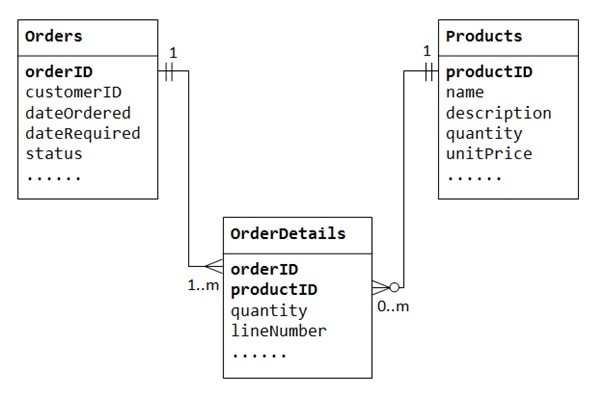
实际上,多对多关系是通过引入连接表实现为两个一对多关系。
一个订单在 OrderDetails 中有多个商品。OrderDetails 商品属于一个特定订单。
一个产品可能出现在多个 OrderDetails 中。每个 OrderDetails 商品指定了一个产品。
一对一
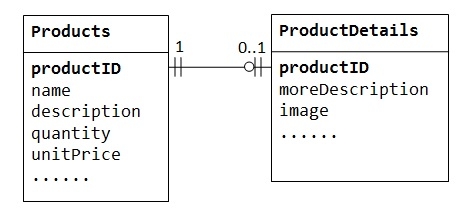
在“产品销售”数据库中,一个产品可能有一些可选的补充信息,例如图像、更多描述和评论。将它们保留在 Products 表中会导致许多空单元格(在没有这些可选数据的记录中)。此外,这些大型数据可能会降低数据库的性能。
相反,我们可以创建另一个表(例如 ProductDetails、ProductLines 或 ProductExtras)来存储可选数据。仅为具有可选数据的那些产品创建记录。这两个表 Products 和 ProductDetails 表现出一对一的关系。也就是说,对于父表中的每一行,子表中最多只有一行(可能为零)。相同的列 productID 应被用作两个表的主键。
一些数据库限制了可以在表中创建的列数。您可以使用一对一关系将数据拆分为两个表。一对一关系也可用于将某些敏感数据存储在安全表中,而将非敏感数据存储在主表中。
列数据类型
您需要为每一列选择合适的数据类型。常用的数据类型包括整数、浮点数、字符串(或文本)、日期/时间、二进制、集合(如枚举和集合)。
步骤 4 - 细化和规范化设计
例如,
- 添加更多列,
- 使用一对一关系为可选数据创建新表,
- 将一个大表拆分为两个较小的表,
- 其他方法。
规范化
应用所谓的规范化规则来检查您的数据库结构是否正确且最优。
第一范式 (1NF):如果每个单元格包含单个值,而不是值列表,则该表为 1NF。此属性称为原子性。1NF 还禁止重复的列组,例如 item1、item2、itemN。相反,您应该使用一对多关系创建另一个表。
第二范式 (2NF) − 当一个表满足第一范式,并且每个非键列都完全依赖于主键时,该表就处于第二范式。此外,如果主键由多个列组成,则每个非键列都应依赖于整个主键,而不是其中的一部分。
例如,OrderDetails 表的主键由 orderID 和 productID 组成。如果 unitPrice 仅依赖于 productID,则它不应该保存在 OrderDetails 表中(而应该保存在 Products 表中)。另一方面,如果单价依赖于产品以及特定的订单,则它应该保存在 OrderDetails 表中。
第三范式 (3NF) − 当一个表满足第二范式,并且非键列之间相互独立时,该表就处于第三范式。换句话说,非键列仅依赖于主键,且仅依赖于主键,不依赖于其他任何东西。例如,假设我们有一个 Products 表,其列包括 productID(主键)、name 和 unitPrice。如果 discountRate 也依赖于 unitPrice(不是主键的一部分),则 discountRate 不应属于 Products 表。
更高范式:第三范式存在一些不足,这导致了更高范式的出现,例如 Boyce/Codd 范式、第四范式 (4NF) 和第五范式 (5NF),这些内容在本教程中不作介绍。
有时,出于性能原因(例如,在 Orders 表中创建一个名为 totalPrice 的列,该列可以从 orderDetails 记录中推导出来),或者由于最终用户的请求,您可能决定打破某些规范化规则;请确保您充分了解这一点,并开发相应的编程逻辑来处理它,以及正确记录您的决策。
完整性规则
您还应该应用完整性规则来检查设计的完整性 −
1. 实体完整性规则 − 主键不能包含空值。否则,它无法唯一地识别行。对于由多个列组成的组合键,任何列都不能包含空值。大多数 RDBMS 会检查并执行此规则。
2. 参照完整性规则 − 每个外键值必须与被引用表(或父表)中的主键值匹配。
只有当父表中存在该值时,您才能在子表中插入包含外键的行。
如果父表中键的值发生更改(例如,行更新或删除),则必须相应地处理子表中所有具有此外键的行。您可以 (a) 禁止更改;(b) 在子表中级联更改(或删除记录);(c) 将子表中的键值设置为 NULL。
大多数 RDBMS 可以设置为以指定的方式执行检查并确保参照完整性。
3. 业务逻辑完整性 − 除了以上两个通用完整性规则外,还可能存在与业务逻辑相关的完整性(验证),例如,邮政编码应为 5 位数字,并在特定范围内,送货日期和时间应在营业时间内;订购数量应等于或小于库存数量等。这些可以通过验证规则(针对特定列)或编程逻辑来执行。
列索引
您可以在选定的列上创建索引以方便数据搜索和检索。索引是一个结构化文件,可以加快 SELECT 查询的数据访问速度,但可能会降低 INSERT、UPDATE 和 DELETE 的速度。如果没有索引结构,要处理具有匹配条件的 SELECT 查询(例如,SELECT * FROM Customers WHERE name='Tan Ah Teck'),数据库引擎需要比较表中的每条记录。一个专门的索引(例如,BTREE 结构)可以在不比较每条记录的情况下找到记录。但是,每当记录发生更改时,都需要重建索引,这会导致与使用索引相关的开销。
索引可以定义在单个列上、一组列上(称为连接索引)或列的一部分上(例如,VARCHAR(100) 的前 10 个字符)(称为部分索引)。您可以在一个表中构建多个索引。例如,如果您经常使用 customerName 或 phone number 搜索客户,则可以通过在 customerName 列和 phoneNumber 列上构建索引来加快搜索速度。大多数 RDBMS 会自动为主键构建索引。

17K+ 次浏览
