
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 Pytorch Lightning 训练神经网络
Pytorch Lightning是一个非常强大的框架,它简化了训练神经网络的过程。众所周知,神经网络已成为解决机器学习相关问题的基本工具,然而训练神经网络已成为一项必要但具有挑战性的任务,需要仔细管理模型、数据和训练循环,这就是我们使用 PyTorch Lightning 的原因。
在本文中,我们将探讨什么是 PyTorch Lightning,如何使用 PyTorch Lightning 训练神经网络,它的优势以及提高训练过程的各种技术。
什么是 PyTorch Lightning?
PyTorch Lightning 是一个用户友好的 Python 库,它简化了神经网络的训练。它旨在使深度学习对初学者和专家都更容易。PyTorch Lightning 提供了一个清晰且组织良好的框架来构建模型,而不是陷入复杂的代码中。
它负责处理繁琐的任务,例如数据加载和训练循环,因此我们可以专注于令人兴奋的部分:设计网络架构和尝试不同的技术。使用 PyTorch Lightning,您可以加快学习曲线并更快地取得进展。
PyTorch Lightning 用于训练神经网络的优势
PyTorch Lightning 为神经网络训练提供了多项优势 -
它通过将问题或关注点分解成单独的模块(例如模型设计、数据加载和训练循环)来鼓励代码模块化。这种模块化方法使代码库更容易调试、理解和维护。
Pytorch lightning 自动执行许多常见任务,包括分布式训练、梯度累积和日志记录。这使我们能够专注于模型的主要组件,而不是实现问题。
使用 Pytorch Lightning 训练神经网络的步骤
以下是使用 PyTorch Lightning 训练神经网络的分步指南,PyTorch Lightning 是一个通过提供有用的抽象和处理单调任务来简化训练过程的框架。我们可以专注于创建模型和处理数据使用 PyTorch Lightning,而框架则处理训练循环和其他复杂操作的复杂性 -
导入我们将期望与神经网络和数据集一起使用的所有必要库,例如 light 和 pytorch_lightning。
我们定义神经网络的结构。我们的模型包含几个层,每一层在处理输入数据和做出预测方面都有其特定的任务。'forward' 方法描述了信息如何通过这些层移动。
定义模型后,我们继续描述和执行训练步骤。在准备过程中,模型获取数据块及其单独的名称。它使用这些批次来计算损失值并进行预测。此损失值解决了模型预测的准确程度。此外,我们记录损失值以监视模型在学习过程中的进展。
为了提高模型的性能,我们将需要一个优化器。优化器帮助模型调整其内部参数以获得更好的结果。
为了自动处理整个训练过程,我们需要设置训练器。我们还将指定训练轮次的次数,这指的是模型在训练期间将经历的数据集的完整遍历次数。
我们定义一个数据模块来处理数据集并将其设置为准备状态。此模块处理堆叠数据集,在下面的程序示例中,使用了 MNIST 数据集,并将数据集转换为模型可以处理的张量。
定义模型、数据模块和训练器后,我们为每个模块创建实例。这些实例将在整个训练过程中使用。
最后,我们准备开始训练过程。我们调用训练器的 'fit' 函数,该函数启动训练过程。训练器为预定的轮次运行循环。
在每个轮次中,模型获取数据批次,执行训练步骤(进行预测、计算损失并优化参数),并重复此循环,直到整个数据集都已处理完毕。
示例
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision.datasets import MNIST
from torchvision.transforms import ToTensor
import pytorch_lightning as pl
# Define your neural network model
class NeuralNetwork(pl.LightningModule):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.model = nn.Sequential(
nn.Linear(784, 64),
nn.ReLU(),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.flatten(x)
return self.model(x)
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self.forward(x)
loss = nn.CrossEntropyLoss()(y_hat, y)
self.log("train_loss", loss)
return loss
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=0.001)
# Create a PyTorch Lightning trainer
trainer = pl.Trainer(max_epochs=5)
# Create a PyTorch Lightning data module
class DataModule(pl.LightningDataModule):
def train_dataloader(self):
return DataLoader(MNIST(root="./data", train=True, transform=ToTensor(), download=True), batch_size=64)
# Create an instance of the data module
data_module = DataModule()
# Create an instance of the neural network model
model = NeuralNetwork()
# Train the model
trainer.fit(model, data_module)
输出
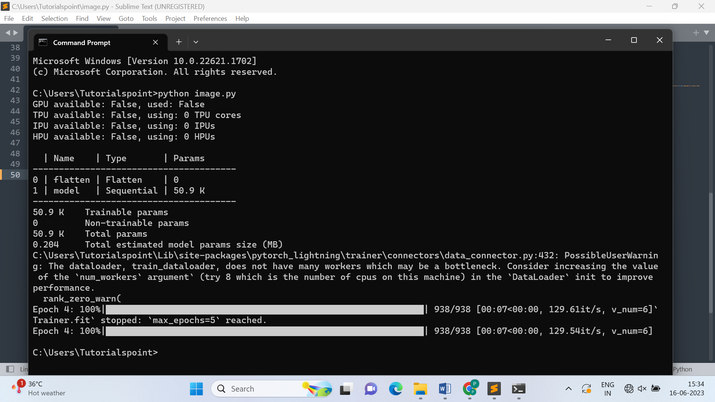
结论
总之,PyTorch Lightning 是一个强大的框架,它简化了训练神经网络的过程。它提供了一种结构化且组织良好的方法来管理数据、模型和训练循环。通过抽象化 PyTorch 的复杂性,PyTorch Lightning 使研究人员和从业人员能够专注于其模型的核心方面。凭借其易用性和灵活性,PyTorch Lightning 是深度学习领域初学者和经验丰富的从业人员的绝佳选择。

427 次查看
