
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP计算机网络中的Unicode
Unicode是信息技术标准,用于一致地编码、表示和处理以世界各种书写系统表达的文本。该标准由Unicode联盟于1991年创建。它包括符号、箭头、字符等。英语中最常用的字符由Unicode的ASCII子集表示。另一方面,Unicode是一种更全面的编码技术,可以表示来自各种语言和文字的字符,包括数学符号和其他专业字符。
Unicode标准已获得Unicode联盟和国际标准ISO的批准。
定义
Unicode是由Unicode联盟创建的通用字符编码标准。Unicode联盟开发了全球字符编码标准,它提供了一个大型字符集。Unicode简化了软件本地化,并增强了多语言文本处理。Unicode可以解决ASCII提出的问题并扩展ASCII。Unicode遵循一组严格的规则,只使用4个字节来表示字符。因此,提供了多种编码方式。最重要的编码方式是UTF。它代表Unicode转换格式。Unicode提供了确保不同平台和语言之间兼容性所需的规则、算法和功能。
主要有三种类型:UTF-7、UTF-8、UTF-16和UTF-32。
任何编程语言的默认编码都是UTF-8。
UTF-7
UTF-7表示ASCII标准。
使用7位ASCII编码。在遵循此协议的电子邮件和通信中表示ASCII字符。
UTF-8
UTF-8等编码经常使用。根据ASCII标准,英语字母和符号用1个字节,中东字母和符号用2个字节,亚洲字母用3个字节,其他字符用4个字节。UTF-8主要用于Web开发、标准XML文件、UNIX和Linux文件、表情符号等等。
UTF-16
它主要支持4个字节来表达额外的字符。
在Java、Microsoft Windows等编程语言中进行内部处理。它是UCS-2的扩展版本。
这是一个全球编码标准。
支持多种脚本环境。
节省空间和内存的效率。
提高了代码的跨平台数据互操作性。
UTF-32
它描述了仅由字节计数确定的多字节编码。
例如,用于UNIX系统。
Unicode示例
世界 -
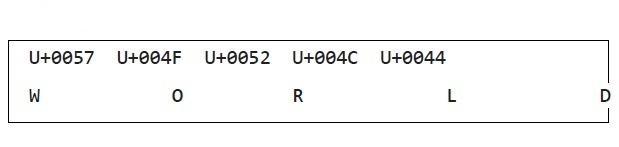
每个字符的Unicode表示使用U+Hex表示。
Unicode的重要性
因为单个应用程序的代码可以在多个平台上运行,而无需完全重写。
Unicode是所有编码方案的超集。它可以转换为其他标准编码。
常用在编程语言中。
转换过程快速,数据丢失少。
Unicode和ASCII码
ASCII码是一种字母数字代码,用于表示数字、字母和符号。ASCII是美国信息交换标准代码的缩写。虽然它是一种7位代码,但为了方便起见,使用8位。
对于7位代码,它支持128个字符;对于8位代码,它支持256个字符。
在内存方面,ASCII比Unicode的需求更低。
与ASCII相关的主要问题是对于8位字符,最多只能写入255个字符。
Unicode和ISCII码
印度信息交换脚本代码(ISCII)编码系统用于表示各种印度文字系统。ISCII使用8位编码。高于128的代码点是ISCII特有的,而低于128的代码点是标准ASCII。包括梵文和吠陀文字语言,以及所有印度语言。
印度信息交换脚本代码(ISCII)于1997年首次由印度标准局使用。
Unicode的缺点
需要大量的内存来解析各种字符。
UTF-16和UTF-32需要较大的内存空间。
字节大小随着变体字母符号的增加而增加。
结论
在本文中,我们解释了计算机网络中的Unicode。Unicode是一种字符编码,用于国际标准,使字符可读并与各种设备兼容。此外,ASCII字符不足以涵盖所有语言,为了解决这个问题,Unicode联盟引入了Unicode编码。

719 次浏览
