
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP机器学习中学习曲线的应用详解
简介
机器学习的核心在于教会计算机学习模式并在无需显式编程的情况下做出决策。它通过支持能够解决复杂问题的智能系统,彻底改变了多个行业。机器学习中一个经常被忽视的关键方面是学习曲线。这些曲线反映了一个基本的过程,模型随着时间的推移逐渐提高其预测能力。在本文中,我们将通过创意示例和详细解释来探索机器学习中学习曲线的迷人世界。
机器学习中的学习曲线
学习曲线是图形化的表示,用于可视化模型性能随着数据集大小的增加或训练过程的进行而发生的变化。通常将其描绘成将模型错误率(在训练数据和测试数据上)与各种样本大小或迭代次数进行比较的图表,从而提供了关于模型泛化能力的有价值的见解。
富有洞察力的旅程
想象一下,踏上一段穿越未知领域的冒险之旅——在深入机器学习令人兴奋的领域(错综复杂的算法和方法)时,也适用了类似的比喻。
考虑使用数量不断增加的带标签数据训练图像分类算法——最初从小规模开始,但逐渐转向从数千张到数百万张图像的更大数据集。在整个过程中,机器会适应识别给定数据集中存在的模式——从简单开始,然后随着从额外样本中获得更多知识而发展为更复杂的模式。
初始阶段 - 高偏差(欠拟合)
当我们的虚拟图像分类器遇到其初始任务相关的挑战时,仅使用有限数量的观察结果(例如 100 张图像),由于高偏差或欠拟合问题,它很可能泛化能力较差。过于简单的表示未能捕捉到更大量数据集中存在的关键细微差别——类似于尝试性地浏览未探索的路径,但由于信息不足而无法得出准确的预测或分类。
中期阶段 - 最佳平衡
在我们的探险中进一步前进,需要向算法提供包含数千张(例如 10,000 张)图像的逐渐增大的带标签数据集。在此阶段,学习者力求在捕捉内在模式和避免过度泛化或过度复杂性之间取得最佳平衡。随着模型吸收更多知识,其学习曲线逐渐趋于平缓——显示出一个收敛点,其中训练误差趋于平稳,而测试误差逐渐减小。此阶段代表了一个重要的里程碑,表明在处理新的、未见过的数据方面具有良好的泛化能力。
高级阶段 - 高方差(过拟合)
冒险进入机器学习探索之旅的最深处,揭示了包含数百万(或更多)带标签图像的高度多样化数据集带来的新挑战。
方法 1:Python 代码 - 在机器学习中使用学习曲线
学习曲线是任何机器学习工具包中不可或缺的工具,可以释放算法性能的真正力量。
算法
步骤 1:导入必要的库(scikit-learn、matplotlib)。
步骤 2:使用 scikit-learn 中的 load_digits() 函数加载数字数据集。
步骤 3:分别将特征和标签分配给 X 和 Y。
步骤 4:使用 scikit-learn 中的 learning_curve() 函数生成学习曲线
对支持向量机分类器 (SVC) 使用线性核
使用 10 折交叉验证
使用准确率作为评分指标
将训练大小从 10% 更改到 100%
步骤 5:计算每个训练大小下各折的训练分数和测试分数的均值和标准差。
步骤 6:绘制训练准确率均值与训练样本数量的图表,并用阴影(用于透明度)表示标准差。
步骤 7:绘制交叉验证准确率均值与训练样本数量的图表,并用阴影(用于透明度)表示标准差。
步骤 8:添加轴标签和图表标题,显示图表。
示例
#Importing the required libraries that is load_digits, learning_curve, SVC (Support Vector Classifier), matplotlib
from sklearn.datasets import load_digits
from sklearn.model_selection import learning_curve
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
#Loading the digits dataset and storing in digits variable
digits = load_digits()
#Storing the features to the variables
X, y = digits.data, digits.target
#The learning curve is generated using the required function
train_sizes, train_scores, test_scores = learning_curve(
#linear kernel is used for SVC
SVC(kernel='linear'), X, y,
#cv is assigned with value 10-fold cross validation
cv=10,
#Scoring variable is assigned to hold scoring metric
scoring='accuracy',
#Using the parallel processing
n_jobs=-1,
#By interchanging the training size from 10% to 100%
train_sizes=np.linspace(0.1, 1.0, 10),
)
#To get the mean of the training scores
train_mean = np.mean(train_scores, axis=1)
#To get the standard deviation of the training scores
train_std = np.std(train_scores, axis=1)
#To get the mean test scores across folds
test_mean = np.mean(test_scores, axis=1)
#To get the standard deviation test scores across folds
test_std = np.std(test_scores, axis=1)
#It plots the graph between training accuracy vs number of training examples
plt.plot(train_sizes * len(y), train_mean,label="Training Accuracy")
#filling the area between mean and standard deviation with alpha 0.2
plt.fill_between(train_sizes * len(y), train_mean - train_std,
train_mean + train_std,alpha=0.2)
#It plots the graph between cross-validation accuracy vs number of training examples
plt.plot(train_sizes * len(y), test_mean,label="Cross-validation Accuracy")
# filling the area between mean and standard deviation with alpha 0.2
plt.fill_between(train_sizes * len(y), test_mean - test_std,
test_mean + test_std,alpha=0.2)
#Plotting the x axis with Number of training examples
plt.xlabel("Number of Training Examples")
#Plotting the y axis with accuracy
plt.ylabel("Accuracy")
#The plot with title “Learning curves: Training vs Cross-Validation Accuracy”
plt.title("Learning Curves: Training vs Cross-validation Accuracy")
#Adding the legends and displaying the output
plt.legend()
plt.show()
输出
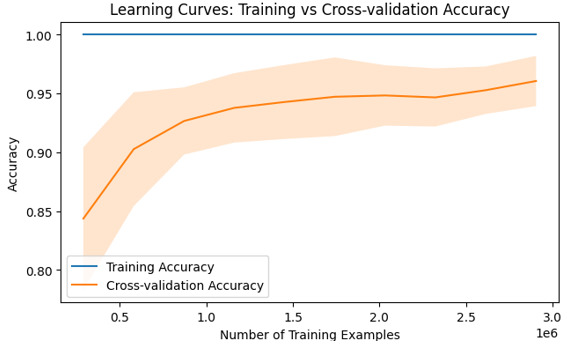
结论
理解学习曲线在机器学习中至关重要,因为它们提供了对模型性能趋势(随着数据集大小或复杂程度的变化)的见解。通过使用如上所示的 Python 代码将错误率与样本大小之间的关系可视化,研究人员可以诊断诸如过拟合或欠拟合等常见缺陷,同时做出明智的决策以优化模型。

244 次浏览
