
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用Python和Scrapy进行网页抓取?
Scrapy是开发爬虫的最佳框架之一。Scrapy是一个流行的网页抓取和爬取框架,它利用高级功能使抓取网站更容易。
安装
在Windows上安装Scrapy很容易:我们可以使用pip或conda(如果您有Anaconda)。Scrapy可以在Python 2和3版本上运行。
pip install Scrapy
或者
conda install –c conda-forge scrapy
如果Scrapy安装正确,现在终端中将可以使用scrapy命令。
C:\Users\rajesh>scrapy Scrapy 1.6.0 - no active project Usage: scrapy <command> [options] [args] Available commands: bench Run quick benchmark test fetch Fetch a URL using the Scrapy downloader genspider Generate new spider using pre-defined templates runspider Run a self-contained spider (without creating a project) settings Get settings values shell Interactive scraping console startproject Create new project version Print Scrapy version view Open URL in browser, as seen by Scrapy [ more ] More commands available when run from project directory Use "scrapy <command> -h" to see more info about a command.
启动项目
现在Scrapy已安装,我们可以运行**startproject**命令来生成第一个Scrapy项目的默认结构。
为此,请打开终端并导航到要存储Scrapy项目的目录,然后运行**scrapy startproject <项目名称>**。下面我使用scrapy_example作为项目名称。
C:\Users\rajesh>scrapy startproject scrapy_example New Scrapy project 'scrapy_example', using template directory 'c:\python\python361\lib\site-packages\scrapy\templates\project', created in: C:\Users\rajesh\scrapy_example You can start your first spider with: cd scrapy_example scrapy genspider example example.com C:\Users\rajesh>cd scrapy_example C:\Users\rajesh\scrapy_example>tree /F Folder PATH listing Volume serial number is 8CD6-8D39 C:. │ scrapy.cfg │ └───scrapy_example │ items.py │ middlewares.py │ pipelines.py │ settings.py │ __init__.py │ ├───spiders │ │ __init__.py │ │ │ └───__pycache__ └───__pycache__
另一种方法是运行scrapy shell并进行网页抓取,如下所示:
In [18]: fetch ("https://www.wsj.com/india")
019-02-04 22:38:53 [scrapy.core.engine] DEBUG: Crawled (200) https://www.wsj.com/india> (referer: None) Scrapy爬虫将返回一个包含已下载信息的“response”对象。让我们检查一下上面的爬虫包含什么:
In [19]: view(response) Out[19]: True
在您的默认浏览器中,网页链接将打开,您将看到类似的内容:

很好,这看起来与我们的网页有点相似,因此爬虫已成功下载整个网页。
现在让我们看看我们的爬虫包含什么:
In [22]: print(response.text) <!DOCTYPE html> <html data-region = "asia,india" data-protocol = "https" data-reactid = ".2316x0ul96e" data-react-checksum = "851122071"> <head data-reactid = ".2316x0ul96e.0"> <title data-reactid = ".2316x0ul96e.0.0">The Wall Street Journal & Breaking News, Business, Financial and Economic News, World News and Video</title> <meta http-equiv = "X-UA-Compatible" content = "IE = edge" data-reactid = ".2316x0ul96e.0.1"/> <meta http-equiv = "Content-Type" content = "text/html; charset = UTF-8" data-reactid = ".2316x0ul96e.0.2"/> <meta name = "viewport" content = "initial-scale = 1.0001, minimum-scale = 1.0001, maximum-scale = 1.0001, user-scalable = no" data-reactid = ".2316x0ul96e.0.3"/> <meta name = "description" content = "WSJ online coverage of breaking news and current headlines from the US and around the world. Top stories, photos, videos, detailed analysis and in-depth reporting." data-reactid = ".2316x0ul96e.0.4"/> <meta name = "keywords" content = "News, breaking news, latest news, US news, headlines, world news, business, finances, politics, WSJ, WSJ news, WSJ.com, Wall Street Journal" data-reactid = ".2316x0ul96e.0.5"/> <meta name = "page.site" content = "wsj" data-reactid = ".2316x0ul96e.0.7"/> <meta name = "page.site.product" content = "WSJ" data-reactid = ".2316x0ul96e.0.8"/> <meta name = "stack.name" content = "dj01:vir:prod-sections" data-reactid = ".2316x0ul96e.0.9"/> <meta name = "referrer" content = "always" data-reactid = ".2316x0ul96e.0.a"/> <link rel = "canonical" href = "https://www.wsj.com/india/" data-reactid = ".2316x0ul96e.0.b"/> <meta nameproperty = "og:url" content = "https://www.wsj.com/india/" data-reactid = ".2316x0ul96e.0.c:$0"/> <meta nameproperty = "og:title" content = "The Wall Street Journal & Breaking News, Business, Financial and Economic News, World News and Video" data-reactid = ".2316x0ul96e.0.c:$1"/> <meta nameproperty = "og:description" content = "WSJ online coverage of breaking news and current headlines from the US and around the world. Top stories, photos, videos, detailed analysis and in-depth reporting." data-reactid = ".2316x0ul96e.0.c:$2"/> <meta nameproperty = "og:type" content = "website" data-reactid = ".2316x0ul96e.0.c:$3"/> <meta nameproperty = "og:site_name" content = "The Wall Street Journal" data-reactid = ".2316x0ul96e.0.c:$4"/> <meta nameproperty = "og:image" content = "https://s.wsj.net/img/meta/wsj-social-share.png" data-reactid = ".2316x0ul96e.0.c:$5"/> <meta name = "twitter:site" content = "@wsj" data-reactid = ".2316x0ul96e.0.c:$6"/> <meta name = "twitter:app:name:iphone" content = "The Wall Street Journal" data-reactid = ".2316x0ul96e.0.c:$7"/> <meta name = "twitter:app:name:googleplay" content = "The Wall Street Journal" data-reactid = " "/> …& so much more:
让我们尝试从该网页中提取一些重要信息:
提取网页标题:
Scrapy提供了一种基于CSS选择器(如类、ID等)从HTML中提取信息的方法。要查找任何网页标题的CSS选择器,只需右键单击并单击“检查”,如下所示
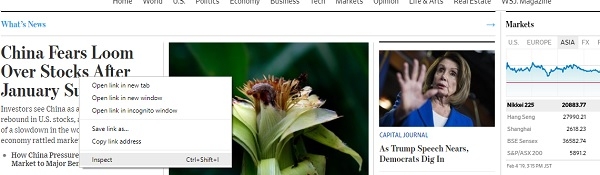
这将在您的浏览器窗口中打开开发者工具:

可以看到,CSS类“wsj-headline-link”应用于所有具有标题的锚点(<a>)标签。有了这些信息,我们将尝试从response对象中的其余内容中查找所有标题:

response.css()是根据传递给它的CSS选择器(如上面的锚点标签)提取内容的函数。让我们看看response.css函数的更多示例。
In [24]: response.css(".wsj-headline-link::text").extract_first()
Out[24]: 'China Fears Loom Over Stocks After January Surge'和
In [25]: response.css(".wsj-headline-link").extract_first()
Out[25]: '<a class="wsj-headline-link" href = "https://www.wsj.com/articles/china-fears-loom-over-stocks-after-january-surge-11549276200" data-reactid=".2316x0ul96e.1.1.5.1.0.3.3.0.0.0:$0.1.0">China Fears Loom Over Stocks After January Surge</a>'要获取网页上的所有链接:
links = response.css('a::attr(href)').extract()输出
['https://www.google.com/intl/en_us/chrome/browser/desktop/index.html', 'https://support.apple.com/downloads/', 'https://www.mozilla.org/en-US/firefox/new/', 'https://windows.microsoft.com/en-us/internet-explorer/download-ie', 'https://www.barrons.com', 'http://bigcharts.marketwatch.com', 'https://www.wsj.com/public/page/wsj-x-marketing.html', 'https://www.dowjones.com/', 'https://global.factiva.com/factivalogin/login.asp?productname=global', 'https://www.fnlondon.com/', 'https://www.mansionglobal.com/', 'https://www.marketwatch.com', 'https://newsplus.wsj.com', 'https://privatemarkets.dowjones.com', 'https://djlogin.dowjones.com/login.asp?productname=rnc', 'https://www.wsj.com/conferences', 'https://www.wsj.com/pro/centralbanking', 'https://www.wsj.com/video/', 'https://www.wsj.com', 'http://www.bigdecisions.com/', 'https://www.businessspectator.com.au/', 'https://www.checkout51.com/?utm_source=wsj&utm_medium=digitalhousead&utm_campaign=wsjspotlight', 'https://www.harpercollins.com/', 'https://housing.com/', 'https://www.makaan.com/', 'https://nypost.com/', 'https://www.newsamerica.com/', 'https://www.proptiger.com', 'https://www.rea-group.com/', …… ……
要获取wsj(华尔街日报)网页上的评论数:
In [38]: response.css(".wsj-comment-count::text").extract()
Out[38]: ['71', '59']以上只是通过scrapy进行网页抓取的介绍,我们可以用scrapy做更多的事情。

608 次查看
