- Apache Presto 教程
- Apache Presto - 首页
- Apache Presto - 概述
- Apache Presto - 架构
- Apache Presto - 安装
- Apache Presto - 配置
- Apache Presto - 管理
- Apache Presto - SQL 操作
- Apache Presto - SQL 函数
- Apache Presto - MySQL 连接器
- Apache Presto - JMX 连接器
- Apache Presto - HIVE 连接器
- Apache Presto - KAFKA 连接器
- Apache Presto - JDBC 接口
- 自定义函数应用
- Apache Presto 有用资源
- Apache Presto - 快速指南
- Apache Presto - 有用资源
- Apache Presto - 讨论
Apache Presto - 架构
Presto 的架构与经典的 MPP(大规模并行处理)DBMS 架构几乎相同。下图说明了 Presto 的架构。
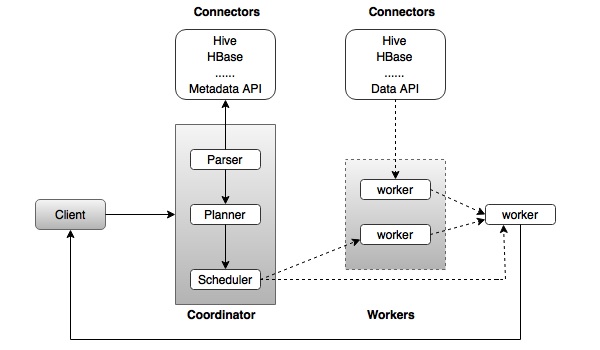
上图包含不同的组件。下表详细描述了每个组件。
| 序号 | 组件及描述 |
|---|---|
| 1. | 客户端 客户端(Presto CLI)将 SQL 语句提交给协调器以获取结果。 |
| 2. | 协调器 协调器是主守护进程。协调器最初解析 SQL 查询,然后分析和计划查询执行。调度程序执行管道执行,将工作分配给最接近的节点并监控进度。 |
| 3. | 连接器 存储插件称为连接器。Hive、HBase、MySQL、Cassandra 等充当连接器;或者您也可以实现自定义连接器。连接器为查询提供元数据和数据。协调器使用连接器获取元数据以构建查询计划。 |
| 4. | 工作节点 协调器将任务分配给工作节点。工作节点从连接器获取实际数据。最后,工作节点将结果传递给客户端。 |
Presto - 工作流程
Presto 是一个在节点集群上运行的分布式系统。Presto 的分布式查询引擎针对交互式分析进行了优化,并支持标准 ANSI SQL,包括复杂查询、聚合、联接和窗口函数。Presto 架构简单且可扩展。Presto 客户端(CLI)将 SQL 语句提交给主守护进程协调器。
调度程序通过执行管道连接。调度程序将工作分配给最接近数据的节点并监控进度。协调器将任务分配给多个工作节点,最后工作节点将结果返回给客户端。客户端从输出进程中提取数据。可扩展性是关键设计。可插拔连接器(如 Hive、HBase、MySQL 等)为查询提供元数据和数据。Presto 采用“简单的存储抽象”设计,使其能够轻松地针对这些不同类型的数据源提供 SQL 查询功能。
执行模型
Presto 支持自定义查询和执行引擎,以及旨在支持 SQL 语义的操作符。除了改进的调度之外,所有处理都在内存中进行,并在不同阶段的网络之间进行流水线处理。这避免了不必要的 I/O 延迟开销。