- Apache Spark 教程
- Apache Spark - 首页
- Apache Spark - 简介
- Apache Spark - RDD
- Apache Spark - 安装
- Apache Spark - 核心编程
- Apache Spark - 部署
- 高级 Spark 编程
- Apache Spark 有用资源
- Apache Spark 快速指南
- Apache Spark - 有用资源
- Apache Spark - 讨论
Apache Spark 快速指南
Apache Spark - 简介
许多行业广泛使用 Hadoop 来分析其数据集。原因是 Hadoop 框架基于简单的编程模型(MapReduce),它能够提供可扩展、灵活、容错且经济高效的计算解决方案。这里,主要关注的是在处理大型数据集时保持速度,包括查询之间的等待时间和程序运行的等待时间。
Apache 软件基金会推出了 Spark,以加快 Hadoop 计算软件的处理速度。
与普遍看法相反,Spark 不是 Hadoop 的修改版本,实际上也不依赖于 Hadoop,因为它有自己的集群管理。Hadoop 只是实现 Spark 的方法之一。
Spark 以两种方式使用 Hadoop——一种是存储,另一种是处理。由于 Spark 拥有自己的集群管理计算,它仅将 Hadoop 用于存储目的。
Apache Spark
Apache Spark 是一种闪电般快速的集群计算技术,专为快速计算而设计。它基于 Hadoop MapReduce,并扩展了 MapReduce 模型,以便高效地将其用于更多类型的计算,包括交互式查询和流处理。Spark 的主要特点是其内存中集群计算,这提高了应用程序的处理速度。
Spark 设计用于涵盖各种工作负载,例如批处理应用程序、迭代算法、交互式查询和流处理。除了在各自的系统中支持所有这些工作负载外,它还减少了维护单独工具的管理负担。
Apache Spark 的发展
Spark 是 Hadoop 的一个子项目,2009 年由 Matei Zaharia 在加州大学伯克利分校的 AMPLab 开发。它于 2010 年在 BSD 许可下开源。2013 年捐赠给 Apache 软件基金会,现在 Apache Spark 已成为从 2014 年 2 月开始的顶级 Apache 项目。
Apache Spark 的特点
Apache Spark 具有以下特点:
速度 - Spark 可以帮助在 Hadoop 集群中运行应用程序,在内存中快 100 倍,在磁盘上运行时快 10 倍。这是通过减少对磁盘的读/写操作次数来实现的。它将中间处理数据存储在内存中。
支持多种语言 - Spark 提供了 Java、Scala 或 Python 的内置 API。因此,您可以使用不同的语言编写应用程序。Spark 提供了 80 多个高级运算符用于交互式查询。
高级分析 - Spark 不仅支持“Map”和“reduce”。它还支持 SQL 查询、流数据、机器学习 (ML) 和图算法。
Spark 基于 Hadoop
下图显示了 Spark 如何使用 Hadoop 组件的三种方式。
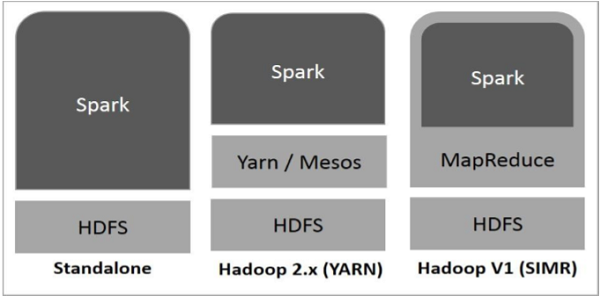
Spark 的部署方式如下所示。
独立模式 - Spark 独立模式部署意味着 Spark 位于 HDFS(Hadoop 分布式文件系统)之上,并为 HDFS 显式分配空间。在这里,Spark 和 MapReduce 将并排运行,以涵盖集群上的所有 Spark 作业。
Hadoop Yarn - Hadoop Yarn 部署意味着 Spark 仅在 Yarn 上运行,无需任何预安装或 root 访问权限。它有助于将 Spark 集成到 Hadoop 生态系统或 Hadoop 堆栈中。它允许其他组件在堆栈顶部运行。
MapReduce 中的 Spark (SIMR) - MapReduce 中的 Spark 用于除了独立部署之外启动 Spark 作业。使用 SIMR,用户可以启动 Spark 并使用其 shell,无需任何管理权限。
Spark 的组件
下图描述了 Spark 的不同组件。
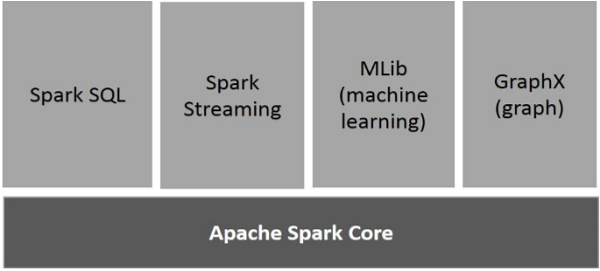
Apache Spark Core
Spark Core 是 Spark 平台的基础通用执行引擎,所有其他功能都是基于它构建的。它提供内存计算和引用外部存储系统中的数据集。
Spark SQL
Spark SQL 是 Spark Core 之上的一个组件,它引入了一种名为 SchemaRDD 的新的数据抽象,它提供对结构化和半结构化数据的支持。
Spark Streaming
Spark Streaming 利用 Spark Core 的快速调度功能来执行流分析。它以小批次的形式摄取数据,并在这些小批次数据上执行 RDD(弹性分布式数据集)转换。
MLlib(机器学习库)
MLlib 是 Spark 之上的一个分布式机器学习框架,因为它基于分布式内存的 Spark 架构。根据 MLlib 开发人员与交替最小二乘法 (ALS) 实现进行的基准测试,Spark MLlib 的速度是 Hadoop 基于磁盘的Apache Mahout版本(在 Mahout 获得 Spark 接口之前)的九倍。
GraphX
GraphX 是 Spark 之上的一个分布式图处理框架。它提供了一个 API 用于表达图计算,可以使用 Pregel 抽象 API 对用户定义的图进行建模。它还为此抽象提供了优化的运行时。
Apache Spark - RDD
弹性分布式数据集
弹性分布式数据集 (RDD) 是 Spark 的基本数据结构。它是一个不可变的对象分布式集合。RDD 中的每个数据集都细分为逻辑分区,这些分区可以在集群的不同节点上计算。RDD 可以包含任何类型的 Python、Java 或 Scala 对象,包括用户定义的类。
正式地说,RDD 是一个只读的分区记录集合。RDD 可以通过对稳定存储上的数据或其他 RDD 执行确定性操作来创建。RDD 是一个容错的元素集合,可以并行操作。
创建 RDD 有两种方法 - 将驱动程序程序中现有的集合并行化,或引用外部存储系统(例如共享文件系统、HDFS、HBase 或任何提供 Hadoop 输入格式的数据源)中的数据集。
Spark 利用 RDD 的概念来实现更快、更高效的 MapReduce 操作。让我们首先讨论 MapReduce 操作是如何进行的以及为什么它们效率不高。
MapReduce 中的数据共享速度慢
MapReduce 被广泛用于使用集群上的并行分布式算法处理和生成大型数据集。它允许用户使用一组高级运算符编写并行计算,而无需担心工作分配和容错。
不幸的是,在大多数当前框架中,在计算之间(例如,在两个 MapReduce 作业之间)重用数据的唯一方法是将其写入外部稳定存储系统(例如 HDFS)。尽管此框架提供了许多用于访问集群计算资源的抽象,但用户仍然需要更多。
迭代和交互式应用程序都需要在并行作业之间进行更快的数据共享。由于复制、序列化和磁盘 I/O,MapReduce 中的数据共享速度很慢。关于存储系统,大多数 Hadoop 应用程序花费超过 90% 的时间进行 HDFS 读写操作。
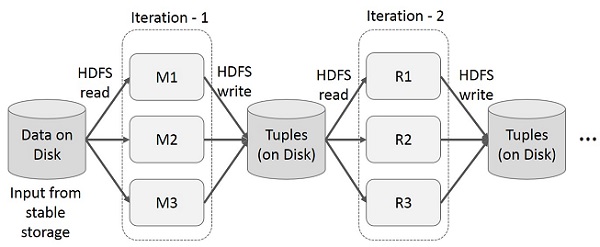
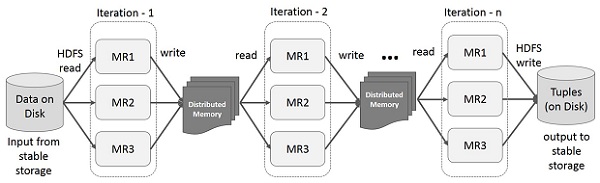
MapReduce 上的迭代操作
在多阶段应用程序中跨多个计算重用中间结果。下图说明了当前框架在 MapReduce 上执行迭代操作时的工作方式。由于数据复制、磁盘 I/O 和序列化,这会产生大量的开销,从而使系统变慢。
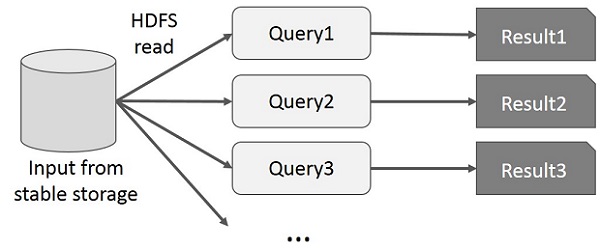
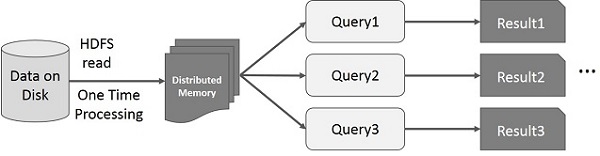
MapReduce 上的交互式操作
用户对同一数据集的子集运行 ad-hoc 查询。每个查询都将对稳定存储执行磁盘 I/O,这可能会主导应用程序执行时间。
下图说明了当前框架在 MapReduce 上执行交互式查询时的工作方式。
使用 Spark RDD 进行数据共享
由于复制、序列化和磁盘 I/O,MapReduce 中的数据共享速度很慢。大多数 Hadoop 应用程序花费超过 90% 的时间进行 HDFS 读写操作。
研究人员认识到这个问题,开发了一个名为 Apache Spark 的专用框架。Spark 的关键思想是弹性分布式数据集 (RDD);它支持内存处理计算。这意味着它将内存状态作为对象跨作业存储,并且该对象可在这些作业之间共享。内存中的数据共享速度比网络和磁盘快 10 到 100 倍。
现在让我们尝试找出 Spark RDD 中迭代和交互操作是如何进行的。
Spark RDD 上的迭代操作
下图显示了 Spark RDD 上的迭代操作。它将中间结果存储在分布式内存中而不是稳定存储(磁盘)中,从而使系统更快。
注意 - 如果分布式内存 (RAM) 足以存储中间结果(作业状态),则它将这些结果存储在磁盘上。
Spark RDD 上的交互式操作
此图显示了 Spark RDD 上的交互式操作。如果对同一数据集重复运行不同的查询,则可以将此特定数据保存在内存中以获得更好的执行时间。
默认情况下,每次对转换后的 RDD 运行操作时,都可能会重新计算它。但是,您也可以将 RDD 保存在内存中,在这种情况下,Spark 将在集群上保留这些元素,以便下次查询时可以更快地访问它们。还支持将 RDD 保存在磁盘上或跨多个节点复制。
Apache Spark - 安装
Spark 是 Hadoop 的子项目。因此,最好将 Spark 安装到基于 Linux 的系统中。以下步骤显示如何安装 Apache Spark。
步骤 1:验证 Java 安装
Java 安装是安装 Spark 的一项必备工作。尝试以下命令来验证 JAVA 版本。
$java -version
如果 Java 已安装在您的系统上,您将看到以下响应:
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果您系统上没有安装 Java,请先安装 Java,然后再进行下一步。
步骤 2:验证 Scala 安装
您应该使用 Scala 语言来实现 Spark。因此,让我们使用以下命令验证 Scala 安装。
$scala -version
如果您的系统上已经安装了 Scala,您将看到以下响应:
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
如果您系统上没有安装 Scala,请继续下一步进行 Scala 安装。
步骤 3:下载 Scala
访问以下链接下载最新版本的 Scala 下载 Scala。本教程使用 scala-2.11.6 版本。下载后,您将在下载文件夹中找到 Scala 的 tar 文件。
步骤 4:安装 Scala
请按照以下步骤安装 Scala。
解压 Scala tar 文件
输入以下命令来解压 Scala tar 文件:
$ tar xvf scala-2.11.6.tgz
移动 Scala 软件文件
使用以下命令将 Scala 软件文件移动到相应的目录 **(/usr/local/scala)**。
$ su – Password: # cd /home/Hadoop/Downloads/ # mv scala-2.11.6 /usr/local/scala # exit
设置 Scala 的 PATH
使用以下命令设置 Scala 的 PATH。
$ export PATH = $PATH:/usr/local/scala/bin
验证 Scala 安装
安装完成后,最好验证一下。使用以下命令验证 Scala 安装。
$scala -version
如果您的系统上已经安装了 Scala,您将看到以下响应:
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
步骤 5:下载 Apache Spark
访问以下链接下载最新版本的 Spark 下载 Spark。本教程使用 **spark-1.3.1-bin-hadoop2.6** 版本。下载后,您将在下载文件夹中找到 Spark 的 tar 文件。
步骤 6:安装 Spark
请按照以下步骤安装 Spark。
解压 Spark tar 文件
使用以下命令解压 Spark tar 文件:
$ tar xvf spark-1.3.1-bin-hadoop2.6.tgz
移动 Spark 软件文件
使用以下命令将 Spark 软件文件移动到相应的目录 **(/usr/local/spark)**。
$ su – Password: # cd /home/Hadoop/Downloads/ # mv spark-1.3.1-bin-hadoop2.6 /usr/local/spark # exit
设置 Spark 的环境
将以下行添加到 ~**/.bashrc** 文件中。这意味着将 Spark 软件文件所在的路径添加到 PATH 变量中。
export PATH=$PATH:/usr/local/spark/bin
使用以下命令加载 ~/.bashrc 文件。
$ source ~/.bashrc
步骤 7:验证 Spark 安装
使用以下命令打开 Spark shell。
$spark-shell
如果 Spark 安装成功,您将看到以下输出。
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>
Apache Spark - 核心编程
Spark Core 是整个项目的基石。它提供分布式任务调度和基本的 I/O 功能。Spark 使用一种称为 RDD(弹性分布式数据集)的特殊基本数据结构,它是在机器之间划分的数据的逻辑集合。RDD 可以通过两种方式创建;一种是引用外部存储系统中的数据集,另一种是对现有 RDD 应用转换(例如 map、filter、reducer、join)。
RDD 抽象通过语言集成 API 公开。这简化了编程的复杂性,因为应用程序操作 RDD 的方式类似于操作本地数据集合。
Spark Shell
Spark 提供了一个交互式 shell——一个强大的工具,用于交互式地分析数据。它可以使用 Scala 或 Python 语言。Spark 的主要抽象是称为弹性分布式数据集 (RDD) 的项目的分布式集合。RDD 可以从 Hadoop 输入格式(例如 HDFS 文件)创建,也可以通过转换其他 RDD 来创建。
打开 Spark Shell
使用以下命令打开 Spark shell。
$ spark-shell
创建简单的 RDD
让我们从文本文件创建一个简单的 RDD。使用以下命令创建一个简单的 RDD。
scala> val inputfile = sc.textFile(“input.txt”)
以上命令的输出为:
inputfile: org.apache.spark.rdd.RDD[String] = input.txt MappedRDD[1] at textFile at <console>:12
Spark RDD API 引入了一些**转换**和一些**动作**来操作 RDD。
RDD 转换
RDD 转换返回指向新 RDD 的指针,并允许您在 RDD 之间创建依赖关系。依赖链(依赖字符串)中的每个 RDD 都有一个计算其数据的函数,并有一个指向其父 RDD 的指针(依赖)。
Spark 是惰性的,所以除非您调用一些转换或动作来触发作业创建和执行,否则不会执行任何操作。请看以下单词计数示例代码片段。
因此,RDD 转换不是一组数据,而是在程序中的一步(可能是唯一的一步),告诉 Spark 如何获取数据以及如何处理它。
| 序号 | 转换及含义 |
|---|---|
| 1 |
map(func) 返回一个新的分布式数据集,该数据集通过函数 **func** 传递源的每个元素而形成。 |
| 2 |
filter(func) 返回一个新的数据集,该数据集通过选择源中 **func** 返回 true 的那些元素而形成。 |
| 3 |
flatMap(func) 类似于 map,但每个输入项可以映射到 0 个或多个输出项(因此 *func* 应该返回一个 Seq 而不是单个项)。 |
| 4 |
mapPartitions(func) 类似于 map,但在 RDD 的每个分区(块)上单独运行,因此当在类型为 T 的 RDD 上运行时,**func** 必须是 Iterator<T> ⇒ Iterator<U> 类型。 |
| 5 |
mapPartitionsWithIndex(func) 类似于 mapPartitions,但还为 **func** 提供一个整数,表示分区的索引,因此当在类型为 T 的 RDD 上运行时,**func** 必须是 (Int, Iterator<T>) ⇒ Iterator<U> 类型。 |
| 6 |
sample(withReplacement, fraction, seed) 对数据进行 **fraction** 抽样,是否放回,使用给定的随机数生成器种子。 |
| 7 |
union(otherDataset) 返回一个新的数据集,其中包含源数据集和参数中的元素的并集。 |
| 8 |
intersection(otherDataset) 返回一个新的 RDD,其中包含源数据集和参数中元素的交集。 |
| 9 |
distinct([numTasks]) 返回一个新的数据集,其中包含源数据集的唯一元素。 |
| 10 |
groupByKey([numTasks]) 当在一个 (K, V) 对的数据集上调用时,返回一个 (K, Iterable<V>) 对的数据集。 **注意** - 如果您是为了对每个键进行聚合(例如求和或平均值)而进行分组,则使用 reduceByKey 或 aggregateByKey 将产生更好的性能。 |
| 11 |
reduceByKey(func, [numTasks]) 当在一个 (K, V) 对的数据集上调用时,返回一个 (K, V) 对的数据集,其中每个键的值使用给定的 reduce 函数 *func* 进行聚合,该函数必须是 (V, V) ⇒ V 类型。与 groupByKey 一样,reduce 任务的数量可以通过可选的第二个参数进行配置。 |
| 12 |
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) 当在一个 (K, V) 对的数据集上调用时,返回一个 (K, U) 对的数据集,其中每个键的值使用给定的组合函数和中性“零”值进行聚合。允许聚合的值类型与输入值类型不同,同时避免不必要的分配。与 groupByKey 一样,reduce 任务的数量可以通过可选的第二个参数进行配置。 |
| 13 |
sortByKey([ascending], [numTasks]) 当在一个 (K, V) 对的数据集上调用时,其中 K 实现 Ordered,返回一个按键的升序或降序排序的 (K, V) 对的数据集,如布尔型 ascending 参数中指定。 |
| 14 |
join(otherDataset, [numTasks]) 当在类型为 (K, V) 和 (K, W) 的数据集上调用时,返回一个 (K, (V, W)) 对的数据集,其中包含每个键的所有元素对。通过 leftOuterJoin、rightOuterJoin 和 fullOuterJoin 支持外部连接。 |
| 15 |
cogroup(otherDataset, [numTasks]) 当在类型为 (K, V) 和 (K, W) 的数据集上调用时,返回一个 (K, (Iterable<V>, Iterable<W>)) 元组的数据集。此操作也称为 groupWith。 |
| 16 |
cartesian(otherDataset) 当在类型为 T 和 U 的数据集上调用时,返回一个 (T, U) 对的数据集(所有元素对)。 |
| 17 |
pipe(command, [envVars]) 通过 shell 命令(例如 Perl 或 bash 脚本)传递 RDD 的每个分区。RDD 元素写入进程的 stdin,并将其 stdout 输出的行作为字符串的 RDD 返回。 |
| 18 |
coalesce(numPartitions) 减少 RDD 中的分区数量到 numPartitions。在过滤掉大型数据集后,有助于更有效地运行操作。 |
| 19 |
repartition(numPartitions) 随机重新调整 RDD 中的数据,以创建更多或更少的分区,并在它们之间进行平衡。这总是会在网络上打乱所有数据。 |
| 20 |
repartitionAndSortWithinPartitions(partitioner) 根据给定的分区器重新分区 RDD,并在每个结果分区内按其键对记录进行排序。这比调用 repartition 然后在每个分区内排序更有效,因为它可以将排序推送到 shuffle 机制中。 |
动作
| 序号 | Action 及含义 |
|---|---|
| 1 |
reduce(func) 使用函数 **func**(它接受两个参数并返回一个参数)聚合数据集的元素。该函数应该是可交换的和关联的,以便可以并行正确地计算它。 |
| 2 |
collect() 将数据集的所有元素作为数组返回到驱动程序程序。这通常在筛选或其他返回足够小的数据子集的操作之后很有用。 |
| 3 |
count() 返回数据集中元素的数量。 |
| 4 |
first() 返回数据集的第一个元素(类似于 take(1))。 |
| 5 |
take(n) 返回一个数组,其中包含数据集的前 **n** 个元素。 |
| 6 |
takeSample(withReplacement, num, [seed]) 返回一个数组,其中包含数据集的 **num** 个元素的随机样本,是否放回,可以选择预先指定随机数生成器种子。 |
| 7 |
takeOrdered(n, [ordering]) 使用它们的自然顺序或自定义比较器返回 RDD 的前 **n** 个元素。 |
| 8 |
saveAsTextFile(path) 将数据集的元素作为文本文件(或一组文本文件)写入本地文件系统、HDFS 或任何其他 Hadoop 支持的文件系统中的给定目录中。Spark 调用 toString 来将每个元素转换为文件中的文本行。 |
| 9 |
saveAsSequenceFile(path)(Java 和 Scala) 将数据集的元素作为 Hadoop SequenceFile 写入本地文件系统、HDFS 或任何其他 Hadoop 支持的文件系统中的给定路径中。这适用于实现 Hadoop 的 Writable 接口的键值对的 RDD。在 Scala 中,它也适用于可以隐式转换为 Writable 的类型(Spark 包含对 Int、Double、String 等基本类型的转换)。 |
| 10 |
saveAsObjectFile(path)(Java 和 Scala) 使用 Java 序列化以简单的格式写入数据集的元素,然后可以使用 SparkContext.objectFile() 加载。 |
| 11 |
countByKey() 仅适用于类型为 (K, V) 的 RDD。返回一个 (K, Int) 对的哈希映射,其中包含每个键的计数。 |
| 12 |
foreach(func) 在数据集的每个元素上运行函数 **func**。这通常是为了产生副作用,例如更新累加器或与外部存储系统交互。 **注意** - 修改 foreach() 外的累加器以外的变量可能会导致未定义的行为。有关详细信息,请参阅理解闭包。 |
使用RDD编程
让我们通过一个例子来看看RDD编程中一些RDD转换和操作的实现。
示例
考虑一个单词计数示例——它计算文档中出现的每个单词。将以下文本作为输入,并将其保存为input.txt文件到主目录。
input.txt - 输入文件。
people are not as beautiful as they look, as they walk or as they talk. they are only as beautiful as they love, as they care as they share.
按照以下步骤执行给定示例。
打开Spark-Shell
使用以下命令打开spark shell。通常,spark是用Scala构建的。因此,Spark程序在Scala环境中运行。
$ spark-shell
如果Spark shell成功打开,您将看到以下输出。“Spark context available as sc”的最后一行表示Spark容器自动创建名为sc的Spark context对象。在开始程序的第一步之前,应该创建SparkContext对象。
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
15/06/04 15:25:22 INFO SecurityManager: Changing view acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: Changing modify acls to: hadoop
15/06/04 15:25:22 INFO SecurityManager: SecurityManager: authentication disabled;
ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/06/04 15:25:22 INFO HttpServer: Starting HTTP Server
15/06/04 15:25:23 INFO Utils: Successfully started service 'HTTP class server' on port 43292.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.4.0
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Spark context available as sc
scala>
创建RDD
首先,我们必须使用Spark-Scala API读取输入文件并创建一个RDD。
以下命令用于从给定位置读取文件。这里,使用inputfile的名称创建一个新的RDD。在textFile("")方法中作为参数给出的字符串是输入文件名的绝对路径。但是,如果只给出文件名,则表示输入文件位于当前位置。
scala> val inputfile = sc.textFile("input.txt")
执行单词计数转换
我们的目标是计算文件中单词的数量。创建一个flat map,将每一行分割成单词 (flatMap(line ⇒ line.split(" ")))。
接下来,使用map函数将每个单词作为键值对,值为'1'(<键, 值> = <单词,1>)(map(word ⇒ (word, 1)))。
最后,通过将相似键的值相加来减少这些键 (reduceByKey(_+_))。
以下命令用于执行单词计数逻辑。执行此操作后,您不会发现任何输出,因为这不是一个action(动作),而是一个transformation(转换);指向一个新的RDD或告诉spark如何处理给定数据。
scala> val counts = inputfile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_);
当前RDD
在使用RDD时,如果想了解当前RDD,请使用以下命令。它将显示有关当前RDD及其依赖项的信息,用于调试。
scala> counts.toDebugString
缓存转换
可以使用persist()或cache()方法标记要持久化的RDD。第一次在action中计算它时,它将保存在节点的内存中。使用以下命令将中间转换存储在内存中。
scala> counts.cache()
应用Action
应用一个action,例如将所有转换结果存储到文本文件中。saveAsTextFile(" ")方法的字符串参数是输出文件夹的绝对路径。尝试以下命令将输出保存到文本文件。在下面的示例中,“output”文件夹位于当前位置。
scala> counts.saveAsTextFile("output")
检查输出
打开另一个终端以转到主目录(在另一个终端中执行spark)。使用以下命令检查输出目录。
[hadoop@localhost ~]$ cd output/ [hadoop@localhost output]$ ls -1 part-00000 part-00001 _SUCCESS
以下命令用于查看Part-00000文件的输出。
[hadoop@localhost output]$ cat part-00000
输出
(people,1) (are,2) (not,1) (as,8) (beautiful,2) (they, 7) (look,1)
以下命令用于查看Part-00001文件的输出。
[hadoop@localhost output]$ cat part-00001
输出
(walk, 1) (or, 1) (talk, 1) (only, 1) (love, 1) (care, 1) (share, 1)
取消持久化存储
在取消持久化之前,如果要查看此应用程序使用的存储空间,请在浏览器中使用以下URL。
https://:4040
您将看到以下屏幕,其中显示了正在Spark shell上运行的应用程序使用的存储空间。
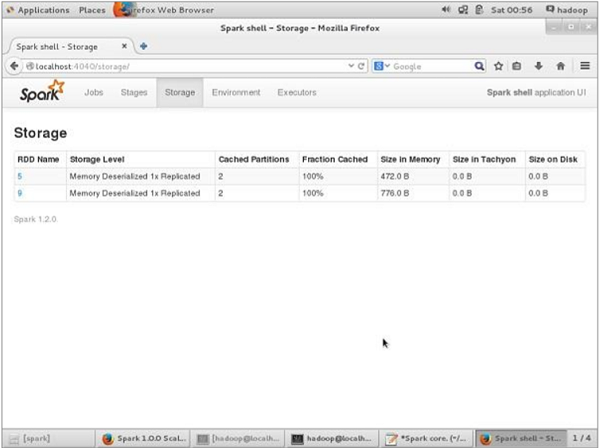
如果要取消持久化特定RDD的存储空间,请使用以下命令。
Scala> counts.unpersist()
您将看到如下输出:
15/06/27 00:57:33 INFO ShuffledRDD: Removing RDD 9 from persistence list 15/06/27 00:57:33 INFO BlockManager: Removing RDD 9 15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_1 15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_1 of size 480 dropped from memory (free 280061810) 15/06/27 00:57:33 INFO BlockManager: Removing block rdd_9_0 15/06/27 00:57:33 INFO MemoryStore: Block rdd_9_0 of size 296 dropped from memory (free 280062106) res7: cou.type = ShuffledRDD[9] at reduceByKey at <console>:14
要验证浏览器中的存储空间,请使用以下URL。
https://:4040/
您将看到以下屏幕。它显示了正在Spark shell上运行的应用程序使用的存储空间。
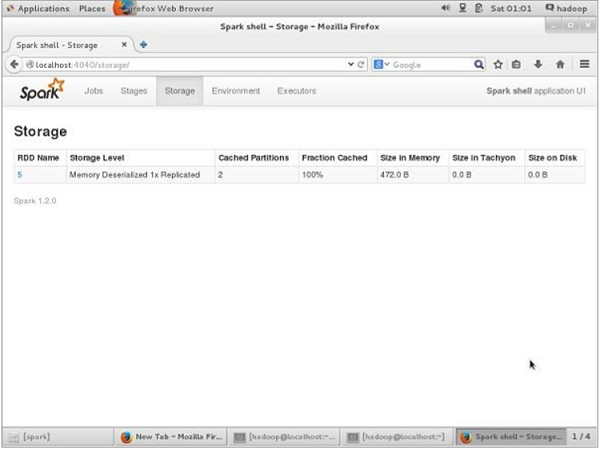
Apache Spark - 部署
使用spark-submit的Spark应用程序是一个shell命令,用于将Spark应用程序部署到集群。它通过统一接口使用所有相应的集群管理器。因此,您不必为每个管理器配置应用程序。
示例
让我们以之前使用的单词计数为例,使用shell命令。在这里,我们将相同的示例视为一个Spark应用程序。
示例输入
以下文本是输入数据,文件名是in.txt。
people are not as beautiful as they look, as they walk or as they talk. they are only as beautiful as they love, as they care as they share.
查看以下程序:
SparkWordCount.scala
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark._
object SparkWordCount {
def main(args: Array[String]) {
val sc = new SparkContext( "local", "Word Count", "/usr/local/spark", Nil, Map(), Map())
/* local = master URL; Word Count = application name; */
/* /usr/local/spark = Spark Home; Nil = jars; Map = environment */
/* Map = variables to work nodes */
/*creating an inputRDD to read text file (in.txt) through Spark context*/
val input = sc.textFile("in.txt")
/* Transform the inputRDD into countRDD */
val count = input.flatMap(line ⇒ line.split(" "))
.map(word ⇒ (word, 1))
.reduceByKey(_ + _)
/* saveAsTextFile method is an action that effects on the RDD */
count.saveAsTextFile("outfile")
System.out.println("OK");
}
}
将上述程序保存到名为SparkWordCount.scala的文件中,并将其放在名为spark-application的用户定义目录中。
注意 - 在将inputRDD转换为countRDD时,我们使用flatMap()将文本文件中的行标记为单词,使用map()方法计算单词频率,使用reduceByKey()方法计算每个单词的重复次数。
使用以下步骤提交此应用程序。通过终端在spark-application目录中执行所有步骤。
步骤1:下载Spark Jar
编译需要Spark core jar,因此,从以下链接下载spark-core_2.10-1.3.0.jar Spark core jar 并将jar文件从下载目录移动到spark-application目录。
步骤2:编译程序
使用以下命令编译上述程序。此命令应从spark-application目录执行。这里,/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar是从Spark库中获取的Hadoop支持jar。
$ scalac -classpath "spark-core_2.10-1.3.0.jar:/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar" SparkPi.scala
步骤3:创建JAR
使用以下命令创建Spark应用程序的jar文件。这里,wordcount是jar文件的文件名。
jar -cvf wordcount.jar SparkWordCount*.class spark-core_2.10-1.3.0.jar/usr/local/spark/lib/spark-assembly-1.4.0-hadoop2.6.0.jar
步骤4:提交Spark应用程序
使用以下命令提交Spark应用程序:
spark-submit --class SparkWordCount --master local wordcount.jar
如果成功执行,您将找到以下输出。以下输出中的OK用于用户识别,它是程序的最后一行。如果您仔细阅读以下输出,您会发现不同的内容,例如:
- successfully started service 'sparkDriver' on port 42954
- MemoryStore started with capacity 267.3 MB
- Started SparkUI at http://192.168.1.217:4040
- Added JAR file:/home/hadoop/piapplication/count.jar
- ResultStage 1 (saveAsTextFile at SparkPi.scala:11) finished in 0.566 s
- Stopped Spark web UI at http://192.168.1.217:4040
- MemoryStore cleared
15/07/08 13:56:04 INFO Slf4jLogger: Slf4jLogger started 15/07/08 13:56:04 INFO Utils: Successfully started service 'sparkDriver' on port 42954. 15/07/08 13:56:04 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@192.168.1.217:42954] 15/07/08 13:56:04 INFO MemoryStore: MemoryStore started with capacity 267.3 MB 15/07/08 13:56:05 INFO HttpServer: Starting HTTP Server 15/07/08 13:56:05 INFO Utils: Successfully started service 'HTTP file server' on port 56707. 15/07/08 13:56:06 INFO SparkUI: Started SparkUI at http://192.168.1.217:4040 15/07/08 13:56:07 INFO SparkContext: Added JAR file:/home/hadoop/piapplication/count.jar at http://192.168.1.217:56707/jars/count.jar with timestamp 1436343967029 15/07/08 13:56:11 INFO Executor: Adding file:/tmp/spark-45a07b83-42ed-42b3b2c2-823d8d99c5af/userFiles-df4f4c20-a368-4cdd-a2a7-39ed45eb30cf/count.jar to class loader 15/07/08 13:56:11 INFO HadoopRDD: Input split: file:/home/hadoop/piapplication/in.txt:0+54 15/07/08 13:56:12 INFO Executor: Finished task 0.0 in stage 0.0 (TID 0). 2001 bytes result sent to driver (MapPartitionsRDD[5] at saveAsTextFile at SparkPi.scala:11), which is now runnable 15/07/08 13:56:12 INFO DAGScheduler: Submitting 1 missing tasks from ResultStage 1 (MapPartitionsRDD[5] at saveAsTextFile at SparkPi.scala:11) 15/07/08 13:56:13 INFO DAGScheduler: ResultStage 1 (saveAsTextFile at SparkPi.scala:11) finished in 0.566 s 15/07/08 13:56:13 INFO DAGScheduler: Job 0 finished: saveAsTextFile at SparkPi.scala:11, took 2.892996 s OK 15/07/08 13:56:13 INFO SparkContext: Invoking stop() from shutdown hook 15/07/08 13:56:13 INFO SparkUI: Stopped Spark web UI at http://192.168.1.217:4040 15/07/08 13:56:13 INFO DAGScheduler: Stopping DAGScheduler 15/07/08 13:56:14 INFO MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped! 15/07/08 13:56:14 INFO Utils: path = /tmp/spark-45a07b83-42ed-42b3-b2c2823d8d99c5af/blockmgr-ccdda9e3-24f6-491b-b509-3d15a9e05818, already present as root for deletion. 15/07/08 13:56:14 INFO MemoryStore: MemoryStore cleared 15/07/08 13:56:14 INFO BlockManager: BlockManager stopped 15/07/08 13:56:14 INFO BlockManagerMaster: BlockManagerMaster stopped 15/07/08 13:56:14 INFO SparkContext: Successfully stopped SparkContext 15/07/08 13:56:14 INFO Utils: Shutdown hook called 15/07/08 13:56:14 INFO Utils: Deleting directory /tmp/spark-45a07b83-42ed-42b3b2c2-823d8d99c5af 15/07/08 13:56:14 INFO OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
步骤5:检查输出
程序成功执行后,您将在spark-application目录中找到名为outfile的目录。
以下命令用于打开和检查outfile目录中的文件列表。
$ cd outfile $ ls Part-00000 part-00001 _SUCCESS
检查part-00000文件的命令是:
$ cat part-00000 (people,1) (are,2) (not,1) (as,8) (beautiful,2) (they, 7) (look,1)
检查part-00001文件的命令是:
$ cat part-00001 (walk, 1) (or, 1) (talk, 1) (only, 1) (love, 1) (care, 1) (share, 1)
阅读以下部分以了解有关“spark-submit”命令的更多信息。
Spark-submit语法
spark-submit [options] <app jar | python file> [app arguments]
选项
| 序号 | 选项 | 描述 |
|---|---|---|
| 1 | --master | spark://host:port, mesos://host:port, yarn, 或 local。 |
| 2 | --deploy-mode | 是在本地 ("client") 启动驱动程序,还是在集群内的某个工作机器上启动 ("cluster") (默认值:client)。 |
| 3 | --class | 应用程序的主类 (对于 Java/Scala 应用程序)。 |
| 4 | --name | 应用程序的名称。 |
| 5 | --jars | 要在驱动程序和执行程序类路径中包含的本地 jar 的逗号分隔列表。 |
| 6 | --packages | 要在驱动程序和执行程序类路径中包含的 jar 的 maven 坐标的逗号分隔列表。 |
| 7 | --repositories | 要搜索 --packages 给出的 maven 坐标的其他远程存储库的逗号分隔列表。 |
| 8 | --py-files | 要在 Python 应用程序的 PYTHON PATH 上放置的 .zip、.egg 或 .py 文件的逗号分隔列表。 |
| 9 | --files | 要放在每个执行程序的工作目录中的文件的逗号分隔列表。 |
| 10 | --conf (prop=val) | 任意的 Spark 配置属性。 |
| 11 | --properties-file | 要从中加载额外属性的文件的路径。如果未指定,它将查找 conf/spark-defaults。 |
| 12 | --driver-memory | 驱动程序的内存 (例如 1000M、2G) (默认值:512M)。 |
| 13 | --driver-java-options | 要传递给驱动程序的额外 Java 选项。 |
| 14 | --driver-library-path | 要传递给驱动程序的额外库路径条目。 |
| 15 | --driver-class-path | 要传递给驱动程序的额外类路径条目。 请注意,使用 --jars 添加的 jar 会自动包含在类路径中。 |
| 16 | --executor-memory | 每个执行程序的内存 (例如 1000M、2G) (默认值:1G)。 |
| 17 | --proxy-user | 提交应用程序时要模拟的用户。 |
| 18 | --help, -h | 显示此帮助消息并退出。 |
| 19 | --verbose, -v | 打印额外的调试输出。 |
| 20 | --version | 打印当前 Spark 的版本。 |
| 21 | --driver-cores NUM | 驱动程序的核心数 (默认值:1)。 |
| 22 | --supervise | 如果给出,则在发生故障时重新启动驱动程序。 |
| 23 | --kill | 如果给出,则终止指定的驱动程序。 |
| 24 | --status | 如果给出,则请求指定的驱动程序的状态。 |
| 25 | --total-executor-cores | 所有执行程序的总核心数。 |
| 26 | --executor-cores | 每个执行程序的核心数。(默认值:在 YARN 模式下为 1,或在独立模式下为工作程序上的所有可用核心)。 |
高级 Spark 编程
Spark包含两种不同类型的共享变量——一个是广播变量,另一个是累加器。
广播变量 - 用于高效地分发大值。
累加器 - 用于聚合特定集合的信息。
广播变量
广播变量允许程序员将只读变量缓存在每台机器上,而不是将它的副本与任务一起发送。例如,它们可以用于以高效的方式为每个节点提供大型输入数据集的副本。Spark 还尝试使用高效的广播算法来分发广播变量,以降低通信成本。
Spark 操作通过一系列阶段执行,这些阶段由分布式“混洗”操作分隔。Spark 自动广播每个阶段中任务所需公共数据。
以这种方式广播的数据以序列化形式缓存,并在运行每个任务之前反序列化。这意味着显式创建广播变量仅在多个阶段的任务需要相同数据或在反序列化形式缓存数据很重要时才有用。
通过调用SparkContext.broadcast(v)从变量v创建广播变量。广播变量是v的包装器,其值可以通过调用value方法来访问。以下代码显示了这一点:
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
输出:
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(0)
创建广播变量后,应在集群上运行的任何函数中使用它,而不是使用值v,这样v就不会多次发送到节点。此外,在广播对象v之后,不应修改对象v,以确保所有节点获得广播变量的相同值。
累加器
累加器是只能通过关联操作“添加”的变量,因此可以在并行环境中有效地支持它们。它们可以用来实现计数器(如在MapReduce中)或求和。Spark 本地支持数值类型的累加器,程序员可以添加对新类型的支持。如果累加器是用名称创建的,它们将显示在Spark 的 UI中。这对于了解正在运行的阶段的进度很有用(注意:Python 中尚不支持此功能)。
累加器 (Accumulator) 通过调用 **SparkContext.accumulator(v)** 从初始值 **v** 创建。集群上运行的任务可以使用 **add** 方法或 += 运算符(在 Scala 和 Python 中)向其添加值。但是,它们无法读取累加器的值。只有驱动程序 (driver program) 可以使用其 **value** 方法读取累加器的值。
下面的代码展示了如何使用累加器对数组元素求和:
scala> val accum = sc.accumulator(0) scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
如果您想查看上述代码的输出,请使用以下命令:
scala> accum.value
输出
res2: Int = 10
数值 RDD 操作
Spark 允许您使用预定义的 API 方法对数值数据执行不同的操作。Spark 的数值操作使用流式算法实现,允许一次构建一个元素的模型。
这些操作通过调用 **status()** 方法计算并作为 **StatusCounter** 对象返回。
| 序号 | 方法及含义 |
|---|---|
| 1 | count() count() |
| 2 | RDD 中元素的数量。 mean() |
| 3 | RDD 中元素的平均值。 sum() |
| 4 | RDD 中元素的总和。 max() |
| 5 | RDD 中所有元素中的最大值。 min() |
| 6 | RDD 中所有元素中的最小值。 variance() |
| 7 | 元素的方差。 stdev() |
标准差。