数据科学 - 需求工具
数据科学工具用于深入挖掘原始和复杂的数据(非结构化或结构化数据),并使用统计学、计算机科学、预测建模和分析以及深度学习等不同的数据处理技术对其进行处理、提取和分析,以发现有价值的见解。
数据科学家在数据科学生命周期的不同阶段使用各种工具来处理每天产生的泽字节和尧字节的结构化和/或非结构化数据,并从中获得有用的见解。这些工具最重要的方面在于,它们使得在无需使用复杂的编程语言的情况下执行数据科学任务成为可能。这是因为这些工具已经内置了算法、函数和图形用户界面(GUI)。
最佳数据科学工具
市场上有很多数据科学工具。因此,很难决定哪一个最适合您的学习和职业发展。下图根据需求展示了一些最佳的数据科学工具:
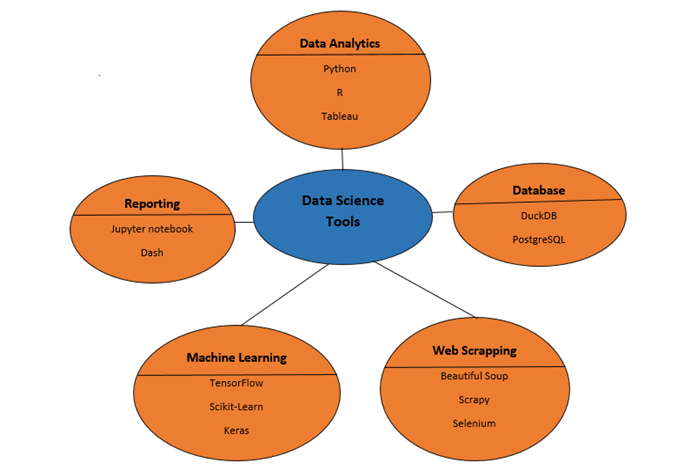
SQL
数据科学是对数据的全面研究。要访问和处理数据,必须从数据库中提取数据,这需要使用 SQL。数据科学严重依赖关系数据库管理。使用 SQL 命令和查询,数据科学家可以管理、定义、修改、创建和查询数据库。
虽然许多现代行业已将其产品数据管理与 NoSQL 技术结合起来,但 SQL 仍然是许多商业智能工具和办公流程的最佳选择。
DuckDB
DuckDB 是一个基于表的关联数据库管理系统,它也允许您使用 SQL 查询进行分析。它是免费和开源的,并且具有许多功能,如更快的分析查询、更简单的操作等等。
DuckDB 还与 Python、R、Java 等数据科学中使用的编程语言兼容。您可以使用这些语言来创建、注册和操作数据库。
Beautiful Soup
Beautiful Soup 是一个 Python 库,可以从 HTML 或 XML 文件中提取或抓取信息。它是一个易于使用的工具,允许您读取网站的 HTML 内容以从中提取信息。
这个库可以帮助数据科学家或数据工程师建立自动的网络爬取,这是完全自动化数据管道的重要步骤。
它主要用于网络抓取。
Scrapy
Scrapy 是一个开源的 Python 网络爬取框架,用于抓取大量网页。它是一个网络爬虫,可以同时抓取和爬取网页。它为您提供了从网站快速获取数据、以所需方式处理数据以及以所需结构和格式存储数据的所有必要工具。
Selenium
Selenium 是一款免费的开源测试工具,用于在不同浏览器上测试 Web 应用程序。Selenium 只能测试 Web 应用程序,因此无法用于测试桌面或移动应用程序。Appium 和 HP 的 QTP 是其他两种可用于测试软件和移动应用程序的工具。
Python
Python 是数据科学家使用最多的编程语言,也是最受欢迎的编程语言之一。Python 在数据科学领域如此受欢迎的主要原因之一是它易于使用且语法简单。这使得没有工程背景的人也可以轻松学习和使用它。此外,还有许多开源库和在线指南来实现机器学习、深度学习、数据可视化等数据科学任务。
以下是 Python 在数据科学中一些最常用的库:
- NumPy
- Pandas
- Matplotlib
- SciPy
- Plotly
R
R 是继 Python 之后数据科学中使用第二多的编程语言。它最初是为了解决统计问题而创建的,但后来发展成为一个完整的数据科学生态系统。
大多数人使用库 dplyr 和 readr 来加载和转换数据。ggplot2 允许您使用各种方式以图形方式表示数据。
Tableau
Tableau 是一款可视化分析平台,正在改变个人和组织使用数据解决问题的方式。它为个人和组织提供了充分利用其数据的工具。
在沟通方面,Tableau 至关重要。数据科学家通常需要将信息分解,以便团队、同事、高管和客户能够更好地理解。在这种情况下,信息需要易于查看和理解。
Tableau 帮助团队深入挖掘数据,发现通常隐藏的见解,然后以美观且易于理解的方式呈现这些数据。Tableau 还帮助数据科学家快速浏览数据,动态添加和删除元素,最终生成一个交互式可视化,突出显示所有相关内容。
TensorFlow
TensorFlow 是一个开源的、免费使用的机器学习平台,使用数据流图。图的节点是数学运算,边是在它们之间流动的多维数据数组(张量)。这种架构非常灵活,可以将机器学习算法描述为协同工作的操作图。它们可以在 GPU、CPU 和 TPU 上以及各种平台(如便携式设备、台式机和高端服务器)上进行训练和运行,而无需更改代码。这使得来自不同背景的程序员可以协同使用相同的工具,从而极大地提高了他们的生产力。Google Brain 团队创建了该系统来研究机器学习和深度神经网络 (DNN)。但是,该系统足够灵活,可以应用于各种其他领域。
Scikit-learn
Scikit-learn 是一个流行的开源 Python 机器学习库,易于使用。它提供各种监督和无监督学习算法,以及用于模型选择、评估和数据预处理的工具。Scikit-learn 在学术界和工业界得到广泛应用。它以快速、可靠和易用而闻名。
它还提供了降维、特征选择、特征提取、集成技术和内置数据集的功能。我们将依次探讨这些功能。
Keras
Google 的 Keras 是一个高级深度学习 API,用于创建神经网络。它是用 Python 编写的,用于简化神经网络的构建。此外,它支持不同的后端神经网络计算。
由于它提供了一个高度抽象的 Python 接口和许多用于计算的后端,因此 Keras 相对易于学习和使用。这使得 Keras 比其他深度学习框架慢,但对于初学者来说非常友好。
Jupyter Notebook
Jupyter Notebook 是一款开源的在线应用程序,允许创建和共享包含实时代码、方程式、可视化和叙述文本的文档。它在数据科学家和机器学习从业者中很受欢迎,因为它提供了一个交互式环境来探索和分析数据。
使用 Jupyter Notebook,您可以在 Web 浏览器中直接编写和运行 Python 代码(以及其他编程语言编写的代码)。结果会显示在同一文档中。这使您能够将代码、数据和文本解释都放在一个地方,从而轻松共享和重现您的分析。
Dash
Dash 是一个重要的数据科学工具,因为它允许您使用 Python 创建交互式 Web 应用程序。它使创建数据可视化仪表板和应用程序变得快速而简单,而无需了解 Web 开发。
SPSS
SPSS(代表“社会科学统计软件包”)是数据科学中一个重要的工具,因为它为新手和经验丰富的用户提供了一套完整的统计和数据分析工具。