
 数据结构
数据结构 网络
网络 关系型数据库管理系统 (RDBMS)
关系型数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 语言编程
C 语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPDeepWalk 算法
简介
图是一种非常有用的数据结构,可以表示共同交互。这些共同交互可以通过神经网络编码为嵌入,用于不同的机器学习算法。这就是 DeepWalk 算法闪光的地方。
在本文中,我们将使用 Word2Vec 示例来探索 DeepWalk 算法。
让我们进一步了解图网络,该算法的核心基于此。
图
如果我们考虑一个特定的生态系统,图通常表示两个或多个实体之间的交互。图网络有两个对象——节点或顶点和边。
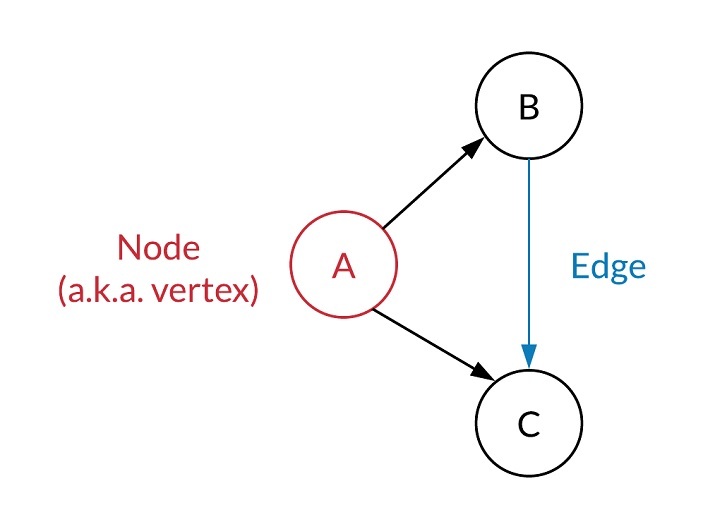
节点(或顶点)表示图系统中的每个元素。例如,Facebook 等社交网络使用图网络将用户表示为节点。此算法用于推荐朋友。
图的另一个方面是连接两个节点并从一个节点运行到另一个节点的边。这些边可以是单向的(有向的)或双向的(无向的)。它定义了节点的交互。它可以加权以表示交互或链接的强度。例如,在上面讨论的 Facebook 好友推荐算法中,边连接两个或多个用户。
现在,我们已经对图网络有了基本的了解,让我们深入了解 DeepWalk 算法。
DeepWalk 算法
word2Vec 模型允许将单词嵌入到 n 维空间向量中。Word2Vec 由 Google 于 2013 年发布。在 Works2Vec 中,相似的单词在 n 维空间中彼此靠近放置。换句话说,它们具有相同的余弦距离。
Word2Vec 使用基于滑动窗口方法的跳字算法进行训练。给定模型中的特定单词,跳字模型尝试预测周围的单词。在我们的场景中,我们将根据目标节点预测邻居节点。将对周围节点进行编码以找到最接近目标节点的节点。
DeepWalk
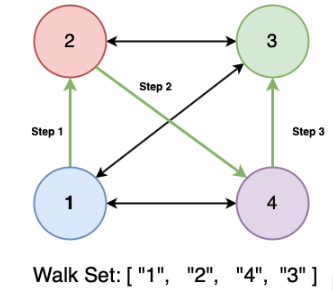
DeepWalk 通过随机遍历图来识别网络的潜在模式。然后,神经网络对这些模式进行编码和学习,以生成最终的嵌入。生成这些随机路径的一种极其简单的方法是从目标根开始,随机选择该节点的邻居,然后将其随机添加到路径中,然后随机选择该节点的邻居,并继续遍历,直到您已执行所需的步数。在 Facebook 好友推荐示例中,通过重复遍历网络的路径生成 ID。这些 ID 在 Word2Vec 模型中被视为标记。
DeepWalk 算法的步骤。
从特定节点开始,从每个节点执行“K-随机”步。
将每次遍历分配为节点和 ID 序列
使用给定的节点/ID 字符串列表,使用跳字算法训练 q Word2Vec 模型。
DeepWalk 算法的 Python 代码
## Deepwalk
import numpy as np
import random
from tqdm import tqdm
import warnings
warnings.filterwarnings('ignore')
from sklearn.decomposition import PCA
import networkx as nx
import matplotlib.pyplot as plt
import pandas as pd
from gensim.models import Word2Vec
%matplotlib inline
df_data = pd.read_csv("/content/space_data.tsv", sep = "\t")
df_data.head()
g = nx.from_pandas_edgelist(df_data, "source", "target", edge_attr=True, create_using=nx.Graph())
def get_random_walk(node, pathlength):
random_walk = [node]
for i in range(pathlength-1):
tmp = list(g.neighbors(node))
tmp = list(set(tmp) - set(random_walk))
if len(tmp) == 0:
break
ran_node = random.choice(tmp)
random_walk.append(ran_node)
node = ran_node
return random_walk
allnodes = list(g.nodes())
walks_list_random = []
for n in tqdm(allnodes):
for i in range(5):
walks_list_random.append(get_random_walk(n,10))
# count of sequences
len(walks_list_random)
model = Word2Vec(window = 4, sg = 1, hs = 0,
negative = 9,
alpha=0.04, min_alpha=0.0005,seed = 20)
model.build_vocab(walks_list_random, progress_per=2)
model.train(walks_list_random, total_examples = model.corpus_count, epochs=20, report_delay=1)
model.similar_by_word('artificial intelligence')
输出
100%|██████████| 2088/2088 [00:00<00:00, 6771.58it/s]
[('robot ethics', 0.9894747138023376),
('cognitive robotics', 0.9886192083358765),
('evolutionary robotics', 0.9876964092254639),
('multi-agent system', 0.9861799478530884),
('cloud robotics', 0.9842559099197388),
('fog robotics', 0.9835143089294434),
('glossary of robotics', 0.9817663431167603),
('soft robotics', 0.9738423228263855),
('robotic governance', 0.9687554240226746),
('robot rights', 0.9686211943626404)]
解释 - 输出列出了与搜索词(查询)“'人工智能'”最相似的词。输出是一个元组列表,其中每个元组的第一个元素是一个相似的词,第二个元素是置信度值。例如,“机器人伦理”相似度为 98.9%(置信度 - 0.989),然后是认知机器人学 (0.988) 等
结论
DeepWalk 是一种用途广泛的算法。只需稍加调整,就可以在多种网络中实现。它是可以考虑的最有效的算法之一。

476 次浏览
