
 数据结构
数据结构 网络
网络 关系型数据库管理系统 (RDBMS)
关系型数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP在ScrapingHub上部署Scrapy爬虫
Scrapy爬虫
Scrapy爬虫是一个类,它提供了一种跟踪网站链接并从网页中提取信息的功能。
这是其他爬虫必须继承的主要类。
Scrapinghub
Scrapinghub是一个开源应用程序,用于运行Scrapy爬虫。Scrapinghub将网络内容转换成一些有用的数据或信息。它允许我们从网页中提取数据,即使是复杂的网页。
我们将使用scrapinghub将scrapy爬虫部署到云端并执行它。
在scrapinghub上部署爬虫的步骤:
步骤1:
创建一个scrapy项目:
安装scrapy后,只需在终端中运行以下命令:
$scrapy startproject <project_name>
将您的目录更改为新项目 (project_name)。
步骤2:
为您的目标网站编写一个scrapy爬虫,让我们以一个常见的网站“quotes.toscrape.com”为例。
下面是我的一个非常简单的scrapy爬虫:
代码:
#import scrapy library
import scrapy
class AllSpider(scrapy.Spider):
crawled = set()
#Spider name
name = 'all'
#starting url
start_urls = ['https://tutorialspoint.com/']
def __init__(self):
self.links = []
def parse(self, response):
self.links.append(response.url)
for href in response.css('a::attr(href)'):
yield response.follow(href, self.parse)步骤3:
运行您的爬虫并将输出保存到您的links.json文件:
执行上述代码后,您将能够抓取所有链接并将其保存到links.json文件中。这可能不是一个漫长的过程,但是为了持续运行24/7,我们需要将这个爬虫部署到Scrapinghub。
步骤4:
在Scrapinghub上创建帐户
为此,您只需使用您的Gmail帐户或Github登录ScrapingHub登录页面即可。它将重定向到仪表板。
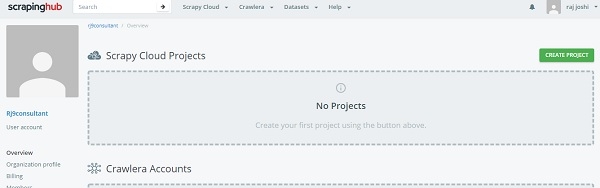
现在单击“创建项目”并提及项目的名称。现在我们可以使用命令行(CLI)或通过github将项目添加到云端。接下来我们将通过shub CLI部署我们的代码,首先安装shub
$pip install shub
安装shub后,使用创建帐户时生成的API密钥登录shub帐户(从https://app.scrapinghub.com/account/apikey输入您的API密钥)。
$shub login
如果您的API密钥正确,您现在已登录。现在我们需要使用在“部署您的代码”部分的命令行部分看到的部署ID(6位数字)来部署它。
$ shub deploy deploy_id
这就是命令行的方法,现在回到“爬虫”仪表板部分,用户可以看到已准备好的爬虫。只需单击爬虫名称和“运行”按钮即可。现在您可以在仪表板中看到您的爬虫,如下所示:
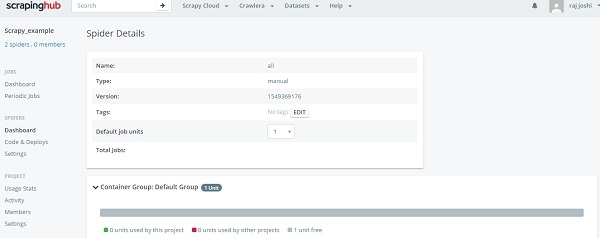
它将通过一次点击向我们展示运行进度,您无需让本地机器24/7运行。

154 次浏览
