
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHPJava 中 SAX 解析器和 DOM 解析器的区别
SAX 和 DOM 都是 XML 解析器 API 的一种类型。这里,API 代表应用程序编程接口,解析器用于以所需的格式读取和提取 XML 文档中的内容。从这句话可以看出,SAX 和 DOM 用于读取 XML 文档。
API 是在 Web 上迁移实时信息的一种现代方法。在本文中,我们将讨论 Java 中 SAX 和 DOM 解析器的区别。
XML 解析器类型
在进一步探讨本文之前,让我们简要讨论一下 XML 及其类型。
XML
它的全称是可扩展标记语言,据说是一种数据描述语言。在其中,用户可以根据需要定义自己的标签。它以树形结构存储信息,使其简单易懂。
这是一个 XML 文档示例
<?xml version="1.0"?>
<grocery>
<cart id = "c101">
<item> Milk </item>
<price> 65 </price>
<quantity> 15 </quantity>
</cart>
<cart id = "c102">
<item> Bread </item>
<price> 30 </price>
<quantity> 10 </quantity>
</cart>
<cart id = "c103">
<item> Butter </item>
<price> 40 </price>
<quantity> 5 </quantity>
</cart>
</grocery>
将数据从一个源传输到另一个源需要转换数据格式。通过 DOM 和 SAX 等解析方法,我们可以读取并将 XML 数据转换为所需的格式。
SAX 解析器
它是 XML 简单 API 的缩写。它从头到尾逐行读取 XML 文档。每当它在解析过程中遇到任何标签时,它都会调用该方法并为用户检索信息。
例如,假设我们想从 XML 文档中访问地址,并且该文档中有一个名为“address”的标签。在这种情况下,当 SAX 解析器到达该标签时,它将调用该方法来检索地址。
SAX 解析器的接口
SAXParserFactory − 它是解析器的对象,是解析的第一步
SAXParser − 它定义了一个名为“parse()”的方法,用于解析。
SAXReader − 它处理与 SAX 事件处理程序的通信。
DOM 解析器
它是文档对象模型的缩写,由万维网联盟 (W3C) 开发。首先,它读取整个 XML 文档并将整个文档转换为树的形式存储在内存中。这棵树有一个根节点和多个父节点和子节点。下图描绘了上面 XML 文档的树 -
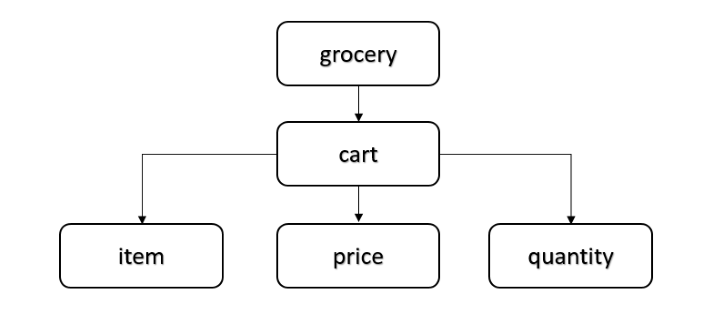
在上图中,“grocery”是根节点。“cart”是父节点,其余节点是其子节点。
我们创建了一个名为 DocumentBuilder 的 DocumentBuilderFactory 接口实例,该接口具有一个内置的 parse 方法,该方法将 XML 文档作为参数并将其转换为 DOM 树。
SAX 和 DOM 解析器的区别
从上面的讨论中,我们可以得出 SAX 和 DOM 解析器之间以下区别 -
SAX 解析器 |
DOM 解析器 |
|---|---|
它是 XML 文档的简单 API。 |
它是文档对象模型。 |
它由 XML-Dev 成员开发。 |
它由万维网联盟 (W3C) 开发。 |
SAX 基于事件模型工作。 |
DOM 基于树模型工作。 |
它只能对 XML 文档执行读取操作。 |
它是双向的,可以对 XML 文档执行读取和写入操作。 |
SAX 以自上而下的方式读取 XML 文件,无法提供随机访问。 |
它更适合复杂和随机访问。 |
它内存效率高,可以处理大型 XML 文件。 |
它内存效率不高,不适合处理大型文件。 |
它从开始处理给定的文档,从而减少了解析的等待时间。 |
从开始处理给定的文档,从而减少了解析的等待时间。在解析之前,它会创建一个 DOM 树。因此,应用程序必须等到树创建完成。 |
结论
在本文中,我们区分了 SAX 和 DOM 解析器。在此过程中,我们发现了 XML,它是一种数据描述语言。它提供各种解析器,如 StAX、DOM 和 SAX,用于读取和写入 XML 文件。所有解析器在许多方面都相似,但区别在于它们的功能和工作方式。此外,它们也各有优缺点。

3K+ 阅读量
