
 数据结构
数据结构 网络
网络 关系型数据库管理系统 (RDBMS)
关系型数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP训练数据和测试数据之间的区别
介绍
在机器学习中,如果我们拥有良好的数据表示和数量,就可以生成良好的模型。在训练模型时,数据可以被划分为不同的数据集,这些数据集具有不同的用途。训练集和测试集是两个非常有用且常见的数据集。训练集是原始数据集的一部分,用于训练模型并找到良好的拟合。测试数据是原始数据的一部分,用于验证模型训练并分析计算的指标。
在本文中,让我们详细探讨训练集和测试数据集。
| 训练数据 | 测试数据 |
|---|---|
| 提供给机器学习模型的数据,以便它可以通过分析数据来学习其中的模式,称为训练数据集。 | 用于评估模型并检查其性能的数据称为测试数据。 |
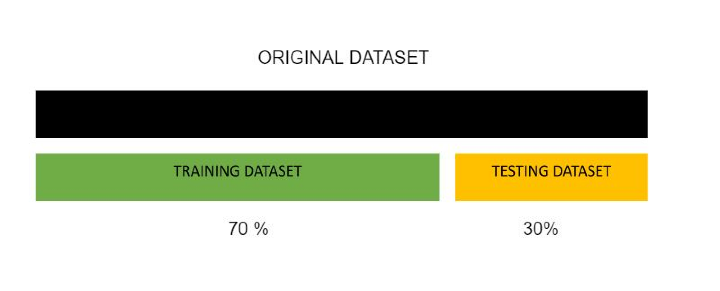
| 它通常大于创建的其他任何数据集。训练数据集的大小大于测试数据集。训练集和测试集之间常用的比例为 80:20、70:30 等 | 它通常以 80:20 或 70:30 等比例获取,较小的比例代表测试数据。 |
| 数据量越大,模型可用的信息就越多。但是,应注意不要用所有数据来训练模型,这可能导致过拟合。 | 用于测试的数据应该是完全未见过的,以便模型获得新数据来检查性能。 |
| 用于训练的数据可以有标签也可以没有标签。这取决于任务的类型。如果是像 KMeans 这样的无监督算法,则不需要标签,但如果是像查找电子邮件是否为垃圾邮件这样的分类任务,则需要带标签的训练数据。 | 测试数据可以根据任务类型添加或不添加标签。 |
| 数据应该与正在解决的用例或问题相关。例如,要确定房价,则与房屋位置、面积等相关的数据与训练相关。 | 数据应该代表原始数据,如训练数据集中所示,并且在特征上不应完全偏离。 |
| 训练数据应该更大,以便模型能够很好地拟合,并且不会由于数据不足而导致欠拟合。 | 数据集应该足够大,以便算法/模型能够做出更好的预测并在指标上显示一些相关结果。 |
| 例如,假设一个可以预测公司未来销售额的预测模型。为了构建和学习此模型,它需要过去的历史数据。这作为训练数据提供。 | 对于相同的预测模型,可以将一部分历史数据用于测试。 |
代码实现
让我们看看将数据集拆分为训练集和测试集的实现,并分析其一些特征。
数据集 CSVimport pandas as pd
from sklearn.model_selection import train_test_split
data = pd.read_csv('/content/train_test.csv')
X_data = data.iloc[:, :-1]
y_data = data.iloc[:, -1]
X_train, X_test, y_train, y_test = train_test_split(
X_data, y_data, test_size=0.3)
print("X Train shape : ",X_train.shape)
print("y Train shape : ",y_train.shape)
print("X Test shape : ",X_test.shape)
print("y Test shape : ",y_train.shape)
输出
X Train shape : (289, 7) y Train shape : (289,) X Test shape : (125, 7) y Test shape : (289,)
从上述实现中,我们已将原始数据集以 70:30 的比例拆分为训练集和测试集。数据集通常有 7 个特征列。Scikit learn 的 train_test_split 函数是一个方便且有用的工具,可以将任何数据集拆分为训练集和测试集。
结论
训练集和测试集都是原始数据的一部分。训练集用于训练模型,测试数据用于训练后的模型预测和评估模型在未见数据上的性能。训练集通常大于测试集,但两个数据集都应相关且来自同一来源,并具有相似的特征。

更新于: 2023年9月22日
5K+ 阅读量

广告