
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 R 探索数据挖掘
介绍
数据挖掘是一种强大的技术,用于从大型数据集中提取有意义的见解和模式。它涉及应用统计和计算算法来揭示数据中隐藏的关系和趋势。R 编程语言是数据挖掘的一种流行工具。在本文中,我们将深入探讨使用 R 进行数据挖掘的世界,探索其功能和应用。
了解数据挖掘
数据挖掘是从大型数据集中发现模式、关系和见解的过程。它涉及多个步骤,包括数据预处理、探索性数据分析、模型构建和评估。数据挖掘技术可应用于各个领域,例如金融、医疗保健、营销等。
R 在数据挖掘中的强大功能
R 是一种广泛使用的编程语言和环境,用于统计计算和图形处理。它提供了大量专门为数据挖掘任务设计的包和库。以下是 R 成为数据挖掘热门选择的一些关键原因:
强大的数据操作功能 - R 提供了强大的数据操作、转换和清理工具。借助 dplyr 和 tidyr 等包,用户可以轻松过滤、排列和重塑数据,以将其准备用于挖掘。
丰富的统计功能 - R 配备了一套全面的统计函数和算法,使用户能够执行各种分析,例如回归、聚类、分类和关联规则挖掘。caret 和 randomForest 等包提供了流行算法的实现。
可视化工具 - R 通过 ggplot2 和 plotly 等包提供了出色的数据可视化功能。这些包使用户能够创建视觉上吸引人和信息丰富的绘图、图表和图形,以探索和展示其数据挖掘分析的结果。
社区支持和积极开发 - R 拥有一个充满活力的数据科学家、统计学家和开发人员社区,他们积极推动其发展。这确保了数据挖掘任务持续涌现新的包、更新和资源。
R 中的数据挖掘技术
R 提供了广泛的数据挖掘技术,可应用于不同类型的数据集。以下是一些常用技术:
回归分析 - 回归分析用于模拟因变量和一个或多个自变量之间的关系。R 提供了各种回归模型,例如线性回归、逻辑回归和多项式回归,以分析和预测数值或分类结果。
聚类 - 聚类是一种根据数据点的特征或接近程度将相似数据点分组在一起的技术。R 提供了 k 均值、层次聚类和 DBSCAN 等算法来执行聚类分析,并在数据中识别自然模式或聚类。
分类 - 分类用于将数据分类到预定义的类别或类别中。R 提供了决策树、随机森林和支持向量机 (SVM) 等算法用于分类任务。这些算法可以在标记数据上进行训练,以预测看不见的实例的类别。
关联规则挖掘 - 关联规则挖掘用于发现大型数据集中项目之间有趣的关系或关联。R 提供了 Apriori 和 Eclat 等算法,这些算法分析事务数据并根据项目共现模式生成规则。
实际示例和用例
使用 R 进行的数据挖掘在各个领域都有应用。以下是一些示例:
市场购物篮分析 - 零售商可以使用关联规则挖掘来分析客户购买数据,并识别诸如经常一起购买的商品等模式。此信息可用于目标营销和产品摆放策略。
欺诈检测 - 可以使用异常检测和分类等数据挖掘技术来检测金融交易中的欺诈活动,帮助组织防止财务损失并维护安全。
客户细分 - 可以使用聚类算法根据客户的行为、偏好或人口统计特征对客户进行分组。此细分使组织能够调整其营销策略,并为不同的客户细分提供个性化体验。
预测性维护 - 通过分析历史设备数据,数据挖掘技术可以预测机器的维护需求和潜在故障。这有助于企业优化维护计划,最大程度地减少停机时间并降低维护成本。
这是一个在 R 中演示数据挖掘技术的简单且可执行的示例代码
# Load required packages library(dplyr) # For data manipulation library(ggplot2) # For data visualization library(caret) # For machine learning algorithms # Load dataset data(iris) # Exploratory Data Analysis summary(iris) # Summary statistics of the dataset plot(iris$Sepal.Length, iris$Sepal.Width, col = iris$Species, pch = 19, xlab = "Sepal Length", ylab = "Sepal Width") # Scatter plot # Data preprocessing # Filter and select specific columns filtered_data <- iris %>% filter(Species != "setosa") %>% select(Species, Sepal.Length, Sepal.Width) # Data visualization ggplot(filtered_data, aes(x = Sepal.Length, y = Sepal.Width, color = Species)) + geom_point() + labs(x = "Sepal Length", y = "Sepal Width", color = "Species") + theme_minimal() # Classification using Random Forest # Split the data into training and testing sets set.seed(123) train_indices <- createDataPartition(filtered_data$Species, p = 0.8, list = FALSE) train_data <- filtered_data[train_indices, ] test_data <- filtered_data[-train_indices, ] # Train the Random Forest model rf_model <- train(Species ~ Sepal.Length + Sepal.Width, data = train_data, method = "rf") # Predict on test data predictions <- predict(rf_model, newdata = test_data) # Evaluate model performance confusionMatrix(predictions, test_data$Species)
输出
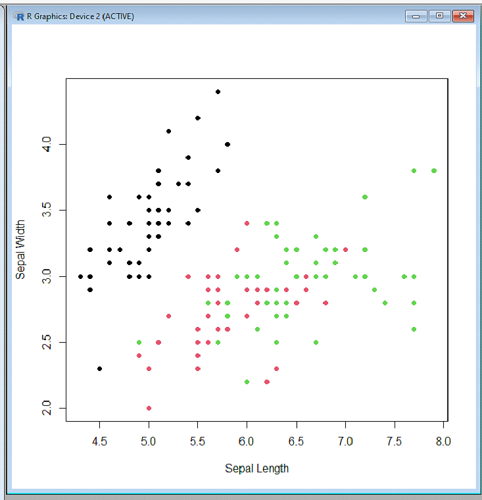
此示例代码执行以下任务:
加载数据操作、可视化和机器学习所需包。
加载著名的 Iris 数据集进行探索。
通过显示汇总统计信息和创建散点图来进行探索性数据分析。
通过过滤和选择特定列来执行数据预处理。
使用散点图可视化预处理数据。
使用 caret 包中的随机森林算法构建分类模型。
将数据拆分为训练集和测试集。
在训练数据上训练随机森林模型。
使用测试数据预测物种。
通过生成混淆矩阵评估模型性能。
请随时在 R 中运行此代码以探索本文中讨论的数据挖掘技术。如果您尚未安装必要的包,请务必安装。

1K+ 次查看
