
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP探索数据分布
介绍
在处理任何数据科学或机器学习用例时,数据分布能让我们对数据有有用的见解。数据分布指的是数据的可用方式及其当前状态、关于数据特定部分的信息、数据中的任何异常值以及与数据相关的中心趋势。
为了探索数据分布,有一些常用的图形方法在处理数据时非常有用。在本文中,让我们探索这些方法。
了解您的数据:图形化方法
直方图和KDE密度图
直方图是在图形方法中使用最广泛且最常见的数据探索工具。在直方图中,矩形条用于表示特定变量或类别(或箱)的频率。当数据可以存在于不同的桶中时,会用到分箱。
让我们使用以下关于房价数据集的代码示例来了解直方图。
数据集链接 − https://drive.google.com/file/d/1XbyBcw6OfE_w3ZeqPM1s_6jT8XeTCeOT/view?usp=sharing
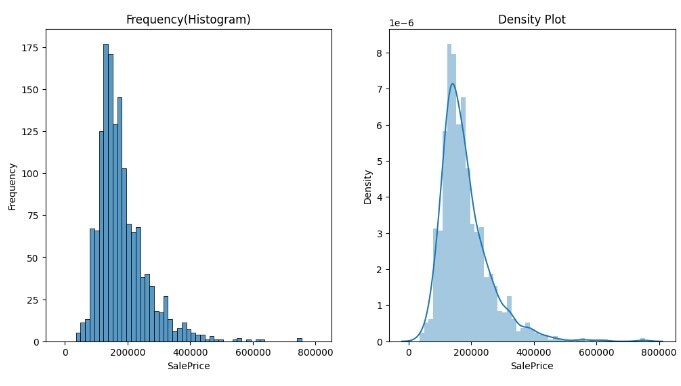
下面的代码帮助我们更有效地理解直方图。在这个代码示例中,我们使用了房价数据集来绘制左侧的销售价格与频率的频率或直方图。右侧的图是销售价格与频率分布的KDE图。密度图是直方图的概率密度函数。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
df = pd.read_csv("/content/house_price_data.csv")
figure, ax = plt.subplots(1, 2, sharex=True, figsize=(12, 6))
ax[0]= sns.histplot(data=df, x="SalePrice",ax=ax[0])
ax[0].set_ylabel("Frequency")
ax[0].set_xlabel("SalePrice")
ax[0].set_title("Frequency(Histogram)")
ax[1]= sns.distplot(df.SalePrice, kde = True,ax=ax[1])
ax[1].set_ylabel("Density")
ax[1].set_xlabel("SalePrice")
ax[1].set_title("Frequency(Histogram)")
输出
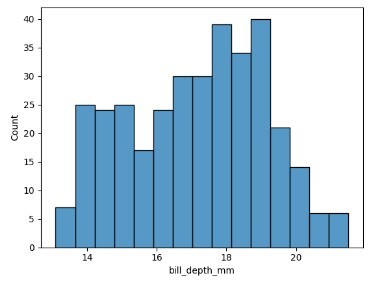
在下面的代码示例中,我们使用了不同类别的箱。我们使用了企鹅数据集来绘制喙深度与计数。这里,喙深度被分成不同的区间,并在x轴上绘制,y轴上绘制计数或频率。
# Using bins on penguins' dataset – seaborn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
data_pen = sns.load_dataset("penguins")
sns.histplot(data=data_pen, x="bill_depth_mm", bins=15)
输出
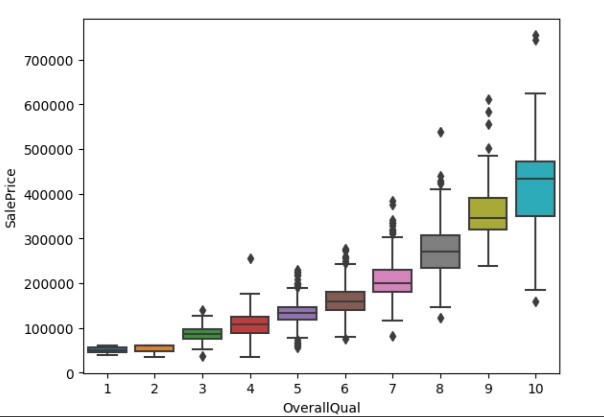
箱线图
箱线图也称为盒须图。箱线图表示数据的百分位数。整个数据被分成不同的百分位数,其中主要分位数是第25、50和75百分位数。第50百分位数表示中位数。箱线图显示位于第25和75百分位数之间的数据,称为IQR(四分位数间距)。

让我们使用以下关于房价数据集的代码示例来了解箱线图。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
df = pd.read_csv("/content/house_price_data.csv")
subset = pd.concat([df['SalePrice'], df['OverallQual']])
figure = sns.boxplot(x='OverallQual', y="SalePrice", data=df)
输出
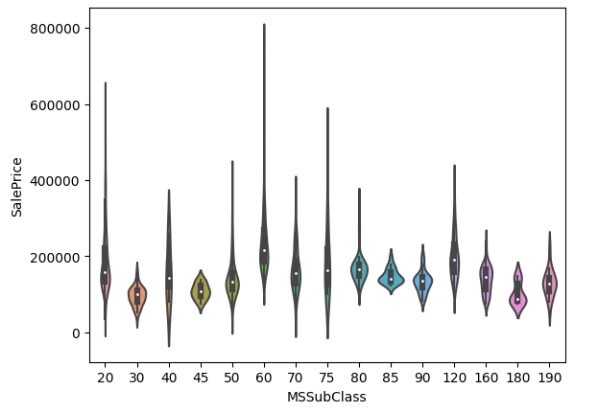
小提琴图
它看起来类似于箱线图,但是它还在图中显示了变量的概率分布。它用于比较所观察变量的概率分布。
让我们使用以下关于房价数据集的代码示例来了解小提琴图。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
df = pd.read_csv("/content/house_price_data.csv")
subset = pd.concat([df['SalePrice'], df['MSSubClass']])
figure = sns.violinplot(x='MSSubClass', y="SalePrice", data=df)
输出
结论
箱线图、密度图和小提琴图是探索数据分布最流行和最常用的方法。它们可靠且受到机器学习工程师和数据科学家的高度信赖。这些图让我们了解数据以及数据的分布方式。此外,还可以从图中确定关于偏度、稀疏性等的基本信息。箱线图和小提琴图等图还可以指示异常值点。

369 次浏览
