
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用 Python 获取全球新冠确诊、康复和死亡病例数
新冠疫情影响了全球数十亿人的生活。疫情导致人们普遍担忧。开发了许多应用程序来确定并获取有关死亡总数、康复病例、确诊病例等准确信息。当开发者想要围绕疫情开发应用程序时,获取和分析这些信息非常重要。在本文中,我们将了解如何获取 COVID-19 病例的统计数据。
使用 API
API(应用程序编程接口)在现代编程和软件开发中非常重要。它使软件应用程序能够相互交互。它定义了一组协议,其他应用程序可以使用这些协议与软件应用程序交互、交换数据、功能等。API 可以采用多种形式,例如 Web API、库 API、操作系统 API 或硬件 API。基于 HTTP 的 Web API 较为常见。它们使开发者能够通过向特定端点发出 HTTP 请求来访问互联网上的数据和服务。
在下面的示例中,我们将使用以下 API
https://disease.sh/v3/covid-19/all示例
在以下代码中,我们首先导入了所有必要的模块。接下来构建了 fetch_data 函数,我们使用它通过 API 以 JSON 格式获取数据。process_data 函数将从获取的数据中返回一个数据框。analyze_cases 通过预处理数据框返回确诊、康复和死亡病例数。接下来,我们创建了 visualize_data 函数,它绘制数据的条形图。我们使用 matplotlib 绘制条形图。我们使用了 main 函数,它是我们的驱动代码。
import requests
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
def fetch_data(url):
response = requests.get(url)
data = response.json()
return data
def process_data(data):
df = pd.DataFrame(data, index=[0])
return df
def analyze_cases(df):
confirmed_cases = df['cases'].iloc[0]
recovered_cases = df['recovered'].iloc[0]
death_cases = df['deaths'].iloc[0]
return confirmed_cases, recovered_cases, death_cases
def visualize_data(confirmed_cases, recovered_cases, death_cases):
labels = ['Confirmed', 'Recovered', 'Deaths']
values = [confirmed_cases, recovered_cases, death_cases]
plt.figure(figsize=(8, 6))
sns.barplot(x=labels, y=values)
plt.xlabel("Cases")
plt.ylabel("Count")
plt.title("Global COVID-19 Cases")
plt.show()
def main():
url = "https://disease.sh/v3/covid-19/all"
data = fetch_data(url)
df = process_data(data)
confirmed_cases, recovered_cases, death_cases = analyze_cases(df)
print("Global COVID-19 Cases:")
print("Confirmed cases:", confirmed_cases)
print("Recovered cases:", recovered_cases)
print("Death cases:", death_cases)
visualize_data(confirmed_cases, recovered_cases, death_cases)
if __name__=='__main__':
main()
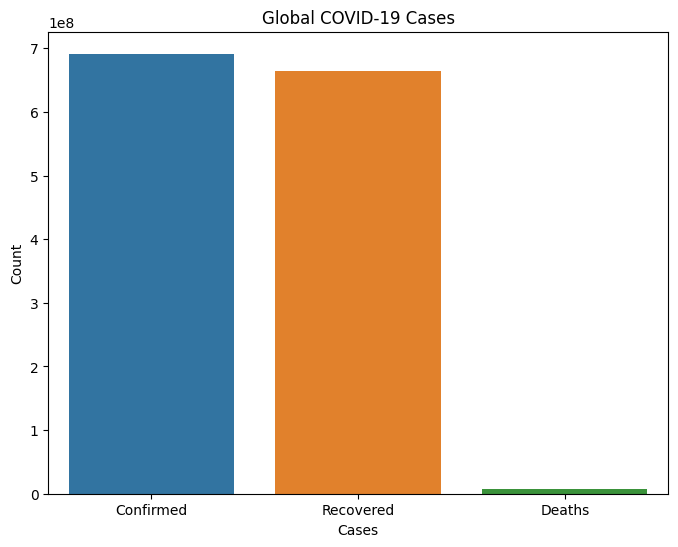
输出
Global COVID-19 Cases: Confirmed cases: 690148376 Recovered cases: 662646473 Death cases: 6890206
使用 Beautifulsoup 进行网页抓取
BeautifulSoup 是 Python 中一个流行的网页抓取库。网页抓取是从网络中提取有意义数据的过程。该库有助于解析 HTML 和 XML 格式的文档。该库提供了一种强大且便捷的方法来搜索和筛选解析文档中的元素。对于我们的用例,我们可以首先使用 Python 的 requests 库获取数据,然后使用 BeautifulSoup 库提取文本。
Python 中的 requests 库有助于与 Web 服务交互并处理 HTTP 请求。该库提供了一种用户友好的方式来发送请求和处理响应。使用 requests 库,开发者可以轻松发送各种 HTTP 请求,例如 GET、POST、PUT、DELETE 等。它支持不同类型的数据有效负载,包括 URL 编码表单数据、JSON 和文件上传,使其适用于不同的 Web 交互。
示例
在以下代码中,我们首先导入了 request、BeautifulSoup、seaborn 等。我们创建了函数 fetch_data,使用 requests 库获取数据并返回 HTML 解析内容。extract_case 函数利用 BeaautifulSoup 方法提取所需信息。visualize_data 函数以确诊病例、康复病例和死亡病例作为参数,并使用 matplotlib 库绘制条形图。我们创建了 main 函数,它是我们程序的驱动代码。
import requests
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import seaborn as sns
def fetch_data(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
return soup
def extract_cases(soup):
confirmed_cases = int(soup.find('div', class_='maincounter-number').span.text.replace(',', ''))
recovered_cases = int(soup.find_all('div', class_='maincounter-number')[2].span.text.replace(',', ''))
death_cases = int(soup.find_all('div', class_='maincounter-number')[1].span.text.replace(',', ''))
return confirmed_cases, recovered_cases, death_cases
def visualize_data(confirmed_cases, recovered_cases, death_cases):
labels = ['Confirmed', 'Recovered', 'Deaths']
values = [confirmed_cases, recovered_cases, death_cases]
plt.figure(figsize=(8, 6))
sns.barplot(x=labels, y=values)
plt.xlabel("Cases")
plt.ylabel("Count")
plt.title("Global COVID-19 Cases")
plt.show()
def main():
url = "https://www.worldometers.info/coronavirus/"
soup = fetch_data(url)
confirmed_cases, recovered_cases, death_cases = extract_cases(soup)
print("Global COVID-19 Cases:")
print("Confirmed cases:", confirmed_cases)
print("Recovered cases:", recovered_cases)
print("Death cases:", death_cases)
visualize_data(confirmed_cases, recovered_cases, death_cases)
if __name__=='__main__':
main()
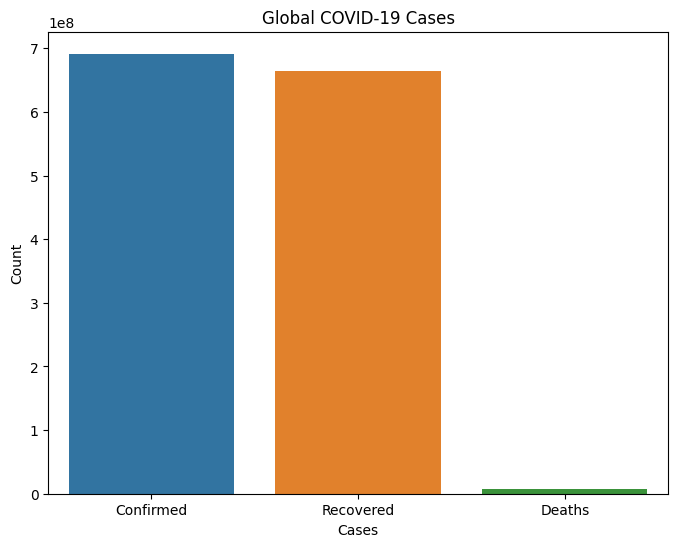
输出
Global COVID-19 Cases: Confirmed cases: 690148376 Recovered cases: 662646473 Death cases: 6890206
使用 selenium 库进行网页抓取
Selenium 是 Python 中一个强大的库,用于自动化 Web 浏览器。它允许程序员通过程序控制 Web 浏览器。这有助于他们自动化任务。Selenium 支持各种 Web 浏览器,包括 Chrome、Firefox、Safari 和 Microsoft Edge。它的工作原理是通过 WebDriver 与浏览器交互,WebDriver 充当 Selenium 库和浏览器之间的桥梁。我们可以使用 Selenium 自动获取 Web 页面内容以满足我们的特定需求。
示例
在以下示例中,我们首先导入了必要的模块和库,如 web driver、BeautifulSoup 等。接下来,我们使用 web driver 方法创建了驱动程序对象。我们使用 requests 库从 URL 获取响应。gety_html 函数返回 HTML 内容。extract_cases 函数是一个用户定义的函数,它从 HTML 解析文本中提取数据。接下来,我们创建了 visualize_data,它根据数据绘制条形图。main 函数包含我们的驱动代码。
from selenium import webdriver
from bs4 import BeautifulSoup
import matplotlib.pyplot as plt
import seaborn as sns
def get_html(url):
driver = webdriver.Chrome()
driver.get(url)
html = driver.page_source
driver.quit()
return html
def extract_cases(soup):
confirmed_cases = int(soup.find('div', class_='maincounter-number').span.text.replace(',', ''))
recovered_cases = int(soup.find_all('div', class_='maincounter-number')[2].span.text.replace(',', ''))
death_cases = int(soup.find_all('div', class_='maincounter-number')[1].span.text.replace(',', ''))
return confirmed_cases, recovered_cases, death_cases
def visualize_data(confirmed_cases, recovered_cases, death_cases):
labels = ['Confirmed', 'Recovered', 'Deaths']
values = [confirmed_cases, recovered_cases, death_cases]
plt.figure(figsize=(8, 6))
sns.barplot(x=labels, y=values)
plt.xlabel("Cases")
plt.ylabel("Count")
plt.title("Global COVID-19 Cases")
plt.show()
def main():
url = "https://www.worldometers.info/coronavirus/"
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
confirmed_cases, recovered_cases, death_cases = extract_cases(soup)
print("Global COVID-19 Cases:")
print("Confirmed cases:", confirmed_cases)
print("Recovered cases:", recovered_cases)
print("Death cases:", death_cases)
visualize_data(confirmed_cases, recovered_cases, death_cases)
if __name__ == '__main__':
main()
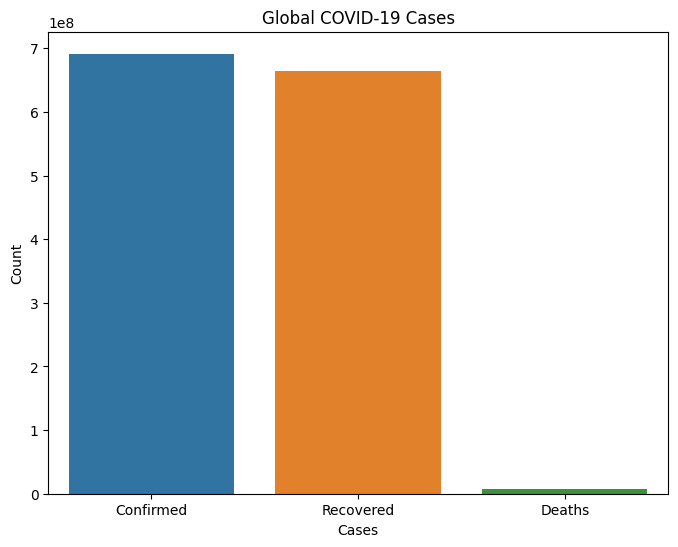
输出
Global COVID-19 Cases: Confirmed cases: 690148376 Recovered cases: 662646473 Death cases: 6890206
结论
在本文中,我们了解了如何获取 COVID-19 的统计数据。我们分析并可视化了数据。Python 是一种通用脚本语言,提供多种处理网页抓取和 API 的方法。因此,我们有很多选择,例如 API、网页抓取等,来获取相关数据。我们首先使用了第三方应用程序提供的 API 来获取相关数据。接下来,我们使用了网页抓取的概念从网页中提取所需数据。

53 次浏览
