- Hadoop 教程
- Hadoop - 首页
- Hadoop - 大数据概述
- Hadoop - 大数据解决方案
- Hadoop - 简介
- Hadoop - 环境搭建
- Hadoop - HDFS 概述
- Hadoop - HDFS 操作
- Hadoop - 命令参考
- Hadoop - MapReduce
- Hadoop - 流处理 (Streaming)
- Hadoop - 多节点集群
- Hadoop 有用资源
- Hadoop - 常见问题解答
- Hadoop 快速指南
- Hadoop - 有用资源
Hadoop 快速指南
Hadoop - 大数据概述
“全球90%的数据是在过去几年中产生的。”
由于新技术、设备和社交网络等通信手段的出现,人类每年产生的数据量都在迅速增长。从古至今到2003年,我们产生的数据总量为50亿吉字节。如果把这些数据以磁盘的形式堆叠起来,可能可以填满整个足球场。而同样的数据量,在2011年每两天产生一次,在2013年每十分钟产生一次。这一增长速度仍在持续快速增长。尽管所有这些产生的信息都很有意义,并在经过处理后可以发挥作用,但它们却被忽视了。
什么是大数据?
大数据是指无法使用传统计算技术进行处理的大型数据集的集合。它不是单一的技术或工具,而是一个完整的学科,涉及各种工具、技术和框架。
大数据包含哪些内容?
大数据包含不同设备和应用程序产生的数据。以下是属于大数据领域的一些方面。
黑盒数据 - 它是直升机、飞机和喷气式飞机等的组成部分。它捕获飞行机组人员的声音、麦克风和耳机的录音以及飞机的性能信息。
社交媒体数据 - Facebook 和 Twitter 等社交媒体包含来自全球数百万人的信息和观点。
证券交易数据 - 证券交易数据包含客户对不同公司股票的“买入”和“卖出”决策信息。
电网数据 - 电网数据包含特定节点相对于基站的功耗信息。
交通数据 - 交通数据包括车辆的型号、容量、行驶距离和可用性。
搜索引擎数据 - 搜索引擎从不同的数据库检索大量数据。

因此,大数据包含海量数据、高速数据和可扩展的各种数据。其中的数据将分为三种类型。
结构化数据 - 关系数据。
半结构化数据 - XML 数据。
非结构化数据 - Word、PDF、文本、媒体日志。
大数据的益处
利用 Facebook 等社交网络中的信息,营销机构可以了解其活动、促销和其他广告媒介的响应情况。
通过利用社交媒体中的信息,例如消费者的偏好和产品认知,产品公司和零售组织正在规划其生产。
通过使用患者既往病史的数据,医院可以提供更好、更快捷的服务。
大数据技术
大数据技术对于提供更准确的分析至关重要,这可能带来更具体的决策,从而提高业务运营效率、降低成本并降低风险。
为了利用大数据的力量,您需要一个能够实时管理和处理海量结构化和非结构化数据,并能够保护数据隐私和安全的架构。
市场上有来自亚马逊、IBM、微软等不同供应商的各种技术来处理大数据。在研究处理大数据的技术时,我们考察以下两类技术:
运营型大数据
这包括像 MongoDB 这样的系统,它们为实时、交互式工作负载提供操作能力,数据主要在其中捕获和存储。
NoSQL 大数据系统旨在利用过去十年中出现的新型云计算架构,从而允许以经济高效的方式运行海量计算。这使得运营型大数据工作负载更容易管理、更便宜且更快地实现。
一些 NoSQL 系统可以在无需编码,并且无需数据科学家和额外基础设施的情况下,根据实时数据提供对模式和趋势的洞察。
分析型大数据
这包括像大规模并行处理 (MPP) 数据库系统和 MapReduce 这样的系统,它们为回顾性和复杂分析提供分析能力,这些分析可能涉及大部分或全部数据。
MapReduce 提供了一种新的数据分析方法,它与 SQL 提供的功能相辅相成,并且基于 MapReduce 的系统可以从单台服务器扩展到数千台高低端机器。
这两类技术是互补的,并且经常一起部署。
运营型系统与分析型系统
| 运营型 | 分析型 | |
|---|---|---|
| 延迟 | 1 毫秒 - 100 毫秒 | 1 分钟 - 100 分钟 |
| 并发性 | 1000 - 100,000 | 1 - 10 |
| 访问模式 | 写入和读取 | 读取 |
| 查询 | 选择性 | 非选择性 |
| 数据范围 | 运营型 | 回顾性 |
| 最终用户 | 客户 | 数据科学家 |
| 技术 | NoSQL | MapReduce,MPP 数据库 |
大数据挑战
与大数据相关的重大挑战如下:
- 数据采集
- 数据整理
- 数据存储
- 数据搜索
- 数据共享
- 数据传输
- 数据分析
- 数据呈现
为了应对上述挑战,组织通常会借助企业服务器。
Hadoop - 大数据解决方案
传统方法
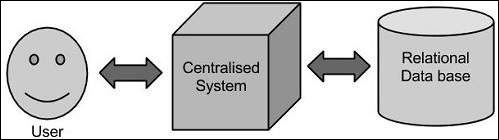
在这种方法中,企业将拥有一台计算机来存储和处理大数据。为了存储,程序员将借助他们选择的数据库供应商,例如 Oracle、IBM 等。在这种方法中,用户与应用程序交互,应用程序反过来处理数据存储和分析的部分。
局限性
这种方法适用于处理那些标准数据库服务器可以容纳的数据量较小的应用程序,或者处理数据的处理器的限制范围内。但是,当涉及到处理大量可扩展数据时,通过单个数据库瓶颈来处理此类数据是一项繁琐的任务。
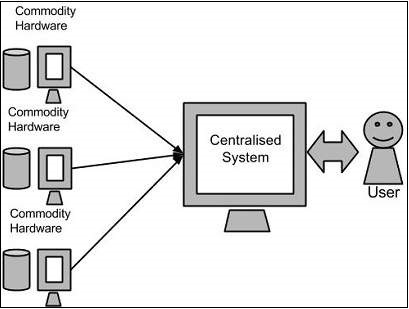
Google 的解决方案
Google 使用名为 MapReduce 的算法解决了这个问题。此算法将任务划分为小的部分并将其分配给许多计算机,并从它们那里收集结果,这些结果集成后形成结果数据集。
Hadoop
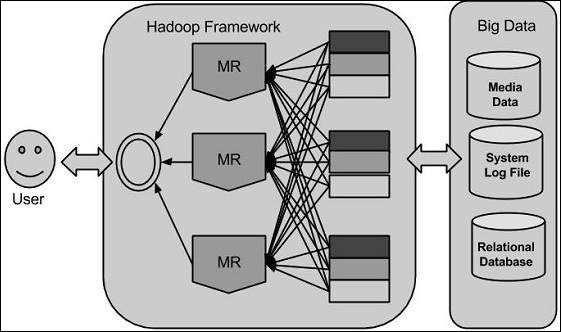
利用 Google 提供的解决方案,Doug Cutting 和他的团队开发了一个名为 HADOOP 的开源项目。
Hadoop 使用 MapReduce 算法运行应用程序,其中数据与其他数据并行处理。简而言之,Hadoop 用于开发能够对海量数据执行完整统计分析的应用程序。
Hadoop - 简介
Hadoop 是一个用 Java 编写的 Apache 开源框架,它允许使用简单的编程模型跨计算机集群分布式处理大型数据集。Hadoop 框架应用程序在一个环境中运行,该环境在计算机集群中提供分布式存储和计算。Hadoop 设计用于从单台服务器扩展到数千台机器,每台机器都提供本地计算和存储。
Hadoop 架构
Hadoop 的核心有两个主要层:
- 处理/计算层 (MapReduce),和
- 存储层 (Hadoop 分布式文件系统)。

MapReduce
MapReduce 是一种并行编程模型,用于编写分布式应用程序,由 Google 设计用于在大型商品硬件集群(数千个节点)上高效处理大量数据(多 TB 数据集),以可靠、容错的方式。MapReduce 程序运行在 Hadoop 上,Hadoop 是一个 Apache 开源框架。
Hadoop 分布式文件系统
Hadoop 分布式文件系统 (HDFS) 基于 Google 文件系统 (GFS),并提供一个设计在商品硬件上运行的分布式文件系统。它与现有的分布式文件系统有很多相似之处。但是,与其他分布式文件系统的区别是显着的。它具有高度容错性,并设计用于部署在低成本硬件上。它提供对应用程序数据的较高吞吐量访问,并且适用于具有大型数据集的应用程序。
除了上述两个核心组件外,Hadoop 框架还包括以下两个模块:
Hadoop Common - 这些是其他 Hadoop 模块所需的 Java 库和实用程序。
Hadoop YARN - 这是一个用于作业调度和集群资源管理的框架。
Hadoop 如何工作?
构建具有强大配置以处理大规模处理的更大服务器非常昂贵,但作为替代方案,您可以将许多带有单 CPU 的商品计算机连接在一起,作为一个单一的、功能性的分布式系统,实际上,集群机器可以并行读取数据集并提供更高的吞吐量。此外,它比一台高端服务器更便宜。因此,这是使用 Hadoop 的第一个动机因素,因为它可以在集群式和低成本机器上运行。
Hadoop 在计算机集群上运行代码。此过程包括 Hadoop 执行的以下核心任务:
数据最初被划分为目录和文件。文件被划分为大小相同的块,为 128M 和 64M(最好是 128M)。
然后将这些文件分发到各个集群节点以进行进一步处理。
HDFS 位于本地文件系统之上,负责监督处理过程。
复制块以处理硬件故障。
检查代码是否已成功执行。
执行 map 和 reduce 阶段之间发生的排序。
将排序后的数据发送到特定计算机。
为每个作业编写调试日志。
Hadoop 的优势
Hadoop 框架允许用户快速编写和测试分布式系统。它效率很高,它自动将数据和工作分配到各个机器上,从而利用 CPU 核心的底层并行性。
Hadoop 不依赖于硬件来提供容错性和高可用性 (FTHA),而是 Hadoop 库本身的设计就是为了检测和处理应用程序层面的故障。
可以动态地向集群添加或删除服务器,而 Hadoop 继续不间断地运行。
Hadoop 的另一个巨大优势是,它除了是开源的之外,由于它是基于 Java 的,因此在所有平台上都兼容。
Hadoop - 环境搭建
Hadoop 支持 GNU/Linux 平台及其衍生版本。因此,我们必须安装 Linux 操作系统才能搭建 Hadoop 环境。如果您使用的操作系统不是 Linux,可以在其中安装 Virtualbox 软件,并在 Virtualbox 中安装 Linux。
安装前设置
在 Linux 环境中安装 Hadoop 之前,我们需要使用ssh(安全外壳)设置 Linux。请按照以下步骤设置 Linux 环境。
创建用户
首先,建议为 Hadoop 创建一个单独的用户,以将 Hadoop 文件系统与 Unix 文件系统隔离。请按照以下步骤创建用户:
使用命令“su”打开 root。
使用命令“useradd 用户名”从 root 帐户创建用户。
现在,您可以使用命令“su 用户名”打开现有的用户帐户。
打开 Linux 终端并键入以下命令以创建用户。
$ su password: # useradd hadoop # passwd hadoop New passwd: Retype new passwd
SSH 设置和密钥生成
SSH 设置是执行集群上不同操作(例如启动、停止、分布式守护程序 shell 操作)所必需的。为了对 Hadoop 的不同用户进行身份验证,需要为 Hadoop 用户提供公钥/私钥对,并将其与不同的用户共享。
以下命令用于使用 SSH 生成密钥值对。将公钥从 id_rsa.pub 复制到 authorized_keys,并分别为所有者提供对 authorized_keys 文件的读写权限。
$ ssh-keygen -t rsa $ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
安装 Java
Java 是 Hadoop 的主要先决条件。首先,您应该使用命令“java -version”验证系统中是否存在 java。java 版本命令的语法如下所示。
$ java -version
如果一切正常,它将为您提供以下输出。
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果您的系统中未安装 java,则请按照以下步骤安装 java。
步骤 1
访问以下链接下载 java(JDK <最新版本>-X64.tar.gz)www.oracle.com
然后jdk-7u71-linux-x64.tar.gz 将下载到您的系统中。
步骤 2
通常,您会在 Downloads 文件夹中找到下载的 java 文件。验证它并使用以下命令解压jdk-7u71-linux-x64.gz 文件。
$ cd Downloads/ $ ls jdk-7u71-linux-x64.gz $ tar zxf jdk-7u71-linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-linux-x64.gz
步骤 3
要使所有用户都能使用 java,您必须将其移动到“/usr/local/”位置。打开 root,然后键入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
步骤 4
要设置PATH 和JAVA_HOME 变量,请将以下命令添加到~/.bashrc 文件中。
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=$PATH:$JAVA_HOME/bin
现在将所有更改应用到当前运行的系统中。
$ source ~/.bashrc
步骤 5
使用以下命令配置 java 替代项:
# alternatives --install /usr/bin/java java usr/local/java/bin/java 2 # alternatives --install /usr/bin/javac javac usr/local/java/bin/javac 2 # alternatives --install /usr/bin/jar jar usr/local/java/bin/jar 2 # alternatives --set java usr/local/java/bin/java # alternatives --set javac usr/local/java/bin/javac # alternatives --set jar usr/local/java/bin/jar
现在,如上所述,从终端验证 java -version 命令。
下载 Hadoop
使用以下命令从 Apache 软件基金会下载并解压 Hadoop 2.4.1。
$ su password: # cd /usr/local # wget http://apache.claz.org/hadoop/common/hadoop-2.4.1/ hadoop-2.4.1.tar.gz # tar xzf hadoop-2.4.1.tar.gz # mv hadoop-2.4.1/* to hadoop/ # exit
Hadoop 操作模式
下载 Hadoop 后,您可以通过三种受支持的模式之一来操作 Hadoop 集群:
本地/独立模式 - 在您的系统中下载 Hadoop 后,默认情况下,它以独立模式配置,并且可以作为单个 java 进程运行。
伪分布式模式 - 这是在单台机器上的分布式模拟。每个 Hadoop 守护程序(例如 hdfs、yarn、MapReduce 等)都将作为单独的 java 进程运行。此模式对于开发很有用。
完全分布式模式 - 此模式是完全分布式的,至少需要两台或多台机器作为集群。我们将在接下来的章节中详细介绍此模式。
在独立模式下安装 Hadoop
在这里,我们将讨论在独立模式下安装Hadoop 2.4.1。
没有运行的守护程序,所有内容都在单个 JVM 中运行。独立模式适用于在开发过程中运行 MapReduce 程序,因为它易于测试和调试。
设置 Hadoop
您可以通过将以下命令添加到~/.bashrc 文件来设置 Hadoop 环境变量。
export HADOOP_HOME=/usr/local/hadoop
在继续之前,您需要确保 Hadoop 运行良好。只需发出以下命令:
$ hadoop version
如果您的设置一切正常,那么您应该看到以下结果:
Hadoop 2.4.1 Subversion https://svn.apache.org/repos/asf/hadoop/common -r 1529768 Compiled by hortonmu on 2013-10-07T06:28Z Compiled with protoc 2.5.0 From source with checksum 79e53ce7994d1628b240f09af91e1af4
这意味着您的 Hadoop 独立模式设置运行良好。默认情况下,Hadoop 配置为在单台机器上以非分布式模式运行。
示例
让我们检查一下 Hadoop 的一个简单示例。Hadoop 安装提供以下示例 MapReduce jar 文件,该文件提供 MapReduce 的基本功能,可用于计算,例如 Pi 值、给定文件列表中的单词计数等。
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar
让我们创建一个输入目录,我们将向其中推送一些文件,我们的要求是计算这些文件中的总单词数。为了计算总单词数,我们不需要编写自己的 MapReduce,前提是 .jar 文件包含单词计数的实现。您可以使用相同的 .jar 文件尝试其他示例;只需发出以下命令即可检查 hadoop-mapreduce-examples-2.2.0.jar 文件支持的 MapReduce 功能程序。
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar
步骤 1
在输入目录中创建临时内容文件。您可以在任何想要工作的地方创建此输入目录。
$ mkdir input $ cp $HADOOP_HOME/*.txt input $ ls -l input
它将在您的输入目录中提供以下文件:
total 24 -rw-r--r-- 1 root root 15164 Feb 21 10:14 LICENSE.txt -rw-r--r-- 1 root root 101 Feb 21 10:14 NOTICE.txt -rw-r--r-- 1 root root 1366 Feb 21 10:14 README.txt
这些文件已从 Hadoop 安装主目录复制。在您的实验中,您可以拥有不同且更大的文件集。
步骤 2
让我们启动 Hadoop 进程来计算输入目录中所有文件的总单词数,如下所示:
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.2.0.jar wordcount input output
步骤 3
步骤 2 将执行所需的处理并将输出保存在 output/part-r00000 文件中,您可以使用以下方法检查:
$cat output/*
它将列出输入目录中所有文件中所有单词及其总计数。
"AS 4 "Contribution" 1 "Contributor" 1 "Derivative 1 "Legal 1 "License" 1 "License"); 1 "Licensor" 1 "NOTICE” 1 "Not 1 "Object" 1 "Source” 1 "Work” 1 "You" 1 "Your") 1 "[]" 1 "control" 1 "printed 1 "submitted" 1 (50%) 1 (BIS), 1 (C) 1 (Don't) 1 (ECCN) 1 (INCLUDING 2 (INCLUDING, 2 .............
在伪分布式模式下安装 Hadoop
请按照以下步骤在伪分布式模式下安装 Hadoop 2.4.1。
步骤 1 - 设置 Hadoop
您可以通过将以下命令添加到~/.bashrc 文件来设置 Hadoop 环境变量。
export HADOOP_HOME=/usr/local/hadoop export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_INSTALL=$HADOOP_HOME
现在将所有更改应用到当前运行的系统中。
$ source ~/.bashrc
步骤 2 - Hadoop 配置
您可以在“$HADOOP_HOME/etc/hadoop”位置找到所有 Hadoop 配置文件。需要根据您的 Hadoop 基础设施更改这些配置文件。
$ cd $HADOOP_HOME/etc/hadoop
为了用 java 开发 Hadoop 程序,您必须通过将JAVA_HOME 值替换为系统中 java 的位置来重置hadoop-env.sh 文件中的 java 环境变量。
export JAVA_HOME=/usr/local/jdk1.7.0_71
以下是您必须编辑以配置 Hadoop 的文件列表。
core-site.xml
core-site.xml 文件包含诸如 Hadoop 实例使用的端口号、为文件系统分配的内存、存储数据的内存限制以及读/写缓冲区的大小等信息。
打开 core-site.xml 并将以下属性添加到 <configuration>、</configuration> 标记之间。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://:9000</value>
</property>
</configuration>
hdfs-site.xml
hdfs-site.xml 文件包含诸如复制数据的值、namenode 路径和本地文件系统的 datanode 路径等信息。这意味着您要存储 Hadoop 基础设施的位置。
让我们假设以下数据。
dfs.replication (data replication value) = 1 (In the below given path /hadoop/ is the user name. hadoopinfra/hdfs/namenode is the directory created by hdfs file system.) namenode path = //home/hadoop/hadoopinfra/hdfs/namenode (hadoopinfra/hdfs/datanode is the directory created by hdfs file system.) datanode path = //home/hadoop/hadoopinfra/hdfs/datanode
打开此文件并将以下属性添加到此文件中的 <configuration> </configuration> 标记之间。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/namenode </value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopinfra/hdfs/datanode </value>
</property>
</configuration>
注意 - 在上述文件中,所有属性值都是用户定义的,您可以根据您的 Hadoop 基础设施进行更改。
yarn-site.xml
此文件用于将 yarn 配置到 Hadoop 中。打开 yarn-site.xml 文件并将以下属性添加到此文件中的 <configuration>、</configuration> 标记之间。
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
mapred-site.xml
此文件用于指定我们正在使用哪个 MapReduce 框架。默认情况下,Hadoop 包含 yarn-site.xml 的模板。首先,需要使用以下命令将文件从mapred-site.xml.template 复制到mapred-site.xml 文件:
$ cp mapred-site.xml.template mapred-site.xml
打开mapred-site.xml 文件并将以下属性添加到此文件中的 <configuration>、</configuration> 标记之间。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
验证 Hadoop 安装
以下步骤用于验证 Hadoop 安装。
步骤 1 - Name Node 设置
使用命令“hdfs namenode -format”设置 namenode,如下所示。
$ cd ~ $ hdfs namenode -format
预期结果如下。
10/24/14 21:30:55 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = localhost/192.168.1.11 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.4.1 ... ... 10/24/14 21:30:56 INFO common.Storage: Storage directory /home/hadoop/hadoopinfra/hdfs/namenode has been successfully formatted. 10/24/14 21:30:56 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 10/24/14 21:30:56 INFO util.ExitUtil: Exiting with status 0 10/24/14 21:30:56 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at localhost/192.168.1.11 ************************************************************/
步骤 2 - 验证 Hadoop dfs
以下命令用于启动 dfs。执行此命令将启动您的 Hadoop 文件系统。
$ start-dfs.sh
预期输出如下:
10/24/14 21:37:56 Starting namenodes on [localhost] localhost: starting namenode, logging to /home/hadoop/hadoop 2.4.1/logs/hadoop-hadoop-namenode-localhost.out localhost: starting datanode, logging to /home/hadoop/hadoop 2.4.1/logs/hadoop-hadoop-datanode-localhost.out Starting secondary namenodes [0.0.0.0]
步骤 3 - 验证 Yarn 脚本
以下命令用于启动 yarn 脚本。执行此命令将启动您的 yarn 守护程序。
$ start-yarn.sh
预期输出如下:
starting yarn daemons starting resourcemanager, logging to /home/hadoop/hadoop 2.4.1/logs/yarn-hadoop-resourcemanager-localhost.out localhost: starting nodemanager, logging to /home/hadoop/hadoop 2.4.1/logs/yarn-hadoop-nodemanager-localhost.out
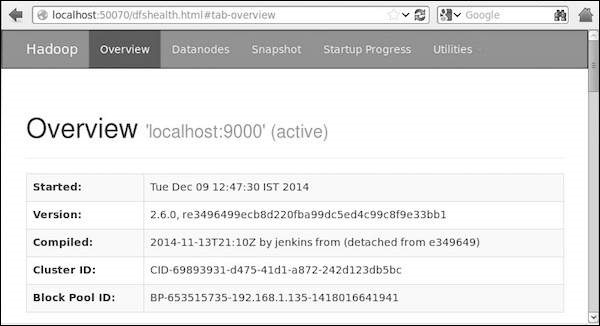
步骤 4 - 在浏览器上访问 Hadoop
访问 Hadoop 的默认端口号为 50070。使用以下网址在浏览器上获取 Hadoop 服务。
https://:50070/
步骤 5 - 验证集群的所有应用程序
访问集群所有应用程序的默认端口号为 8088。使用以下网址访问此服务。
https://:8088/
Hadoop - HDFS 概述
Hadoop 文件系统是使用分布式文件系统设计开发的。它运行在商用硬件上。与其他分布式系统不同,HDFS 具有高度容错性,并使用低成本硬件进行设计。
HDFS 存储海量数据,并提供更轻松的访问。为了存储如此庞大的数据,文件存储在多台机器上。这些文件以冗余方式存储,以在发生故障时保护系统免受可能的数据丢失的影响。HDFS 还使应用程序能够进行并行处理。
HDFS 的特点
- 它适用于分布式存储和处理。
- Hadoop 提供命令界面与 HDFS 交互。
- namenode 和 datanode 的内置服务器帮助用户轻松检查集群状态。
- 流式访问文件系统数据。
- HDFS 提供文件权限和身份验证。
HDFS 架构
以下是 Hadoop 文件系统的架构。
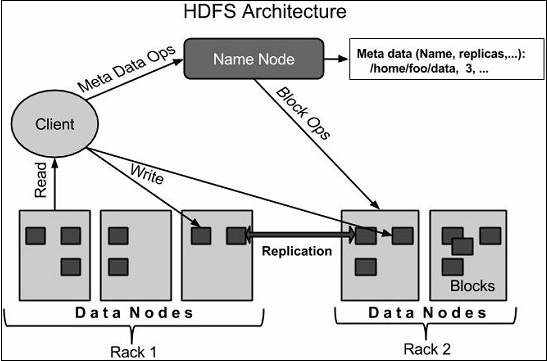
HDFS 遵循主从架构,它具有以下元素。
Namenode
namenode 是包含 GNU/Linux 操作系统和 namenode 软件的商用硬件。它是一种可以在商用硬件上运行的软件。拥有 namenode 的系统充当主服务器,它执行以下任务:
管理文件系统命名空间。
规范客户端对文件的访问。
它还执行文件系统操作,例如重命名、关闭和打开文件和目录。
Datanode
datanode 是一种具有 GNU/Linux 操作系统和 datanode 软件的商用硬件。对于集群中的每个节点(商用硬件/系统),都将有一个 datanode。这些节点管理其系统的数据存储。
根据客户端请求,Datanode 对文件系统执行读写操作。
它们还根据 namenode 的指令执行诸如块创建、删除和复制等操作。
块
通常,用户数据存储在 HDFS 的文件中。文件系统中的文件将被分成一个或多个段,并/或存储在各个数据节点中。这些文件段称为块。换句话说,HDFS 可以读取或写入的最小数据量称为块。默认块大小为 64MB,但可以根据需要更改 HDFS 配置来增加。
HDFS 的目标
故障检测和恢复 − 由于HDFS包含大量商用硬件,组件故障频繁发生。因此,HDFS应该具有快速自动故障检测和恢复机制。
海量数据集 − HDFS应该拥有每集群数百个节点来管理具有海量数据集的应用程序。
数据本地化 − 当计算发生在数据附近时,可以高效地完成请求的任务。尤其是在涉及海量数据集的情况下,它可以减少网络流量并提高吞吐量。
Hadoop - HDFS 操作
启动HDFS
最初,您必须格式化已配置的HDFS文件系统,打开namenode(HDFS服务器)并执行以下命令。
$ hadoop namenode -format
格式化HDFS后,启动分布式文件系统。以下命令将启动namenode以及数据节点作为集群。
$ start-dfs.sh
列出HDFS中的文件
在服务器中加载信息后,我们可以使用‘ls’查找目录中的文件列表和文件状态。下面是您可以将目录或文件名作为参数传递给ls的语法。
$ $HADOOP_HOME/bin/hadoop fs -ls <args>
将数据插入HDFS
假设我们在本地系统中有一个名为file.txt的文件,需要将其保存到hdfs文件系统中。请按照以下步骤将所需文件插入Hadoop文件系统。
步骤 1
您必须创建一个输入目录。
$ $HADOOP_HOME/bin/hadoop fs -mkdir /user/input
步骤 2
使用put命令将数据文件从本地系统传输并存储到Hadoop文件系统中。
$ $HADOOP_HOME/bin/hadoop fs -put /home/file.txt /user/input
步骤 3
您可以使用ls命令验证文件。
$ $HADOOP_HOME/bin/hadoop fs -ls /user/input
从HDFS检索数据
假设我们在HDFS中有一个名为outfile的文件。下面是从小Hadoop文件系统检索所需文件的简单演示。
步骤 1
首先,使用cat命令查看HDFS中的数据。
$ $HADOOP_HOME/bin/hadoop fs -cat /user/output/outfile
步骤 2
使用get命令将文件从HDFS获取到本地文件系统。
$ $HADOOP_HOME/bin/hadoop fs -get /user/output/ /home/hadoop_tp/
关闭HDFS
您可以使用以下命令关闭HDFS。
$ stop-dfs.sh
Hadoop - 命令参考
"$HADOOP_HOME/bin/hadoop fs" 中还有许多在此处未演示的命令,尽管这些基本操作可以帮助您入门。运行 ./bin/hadoop dfs 而不添加任何参数将列出可以使用FsShell系统运行的所有命令。此外,如果您遇到问题,$HADOOP_HOME/bin/hadoop fs -help commandName 命令将显示有关该操作的简短用法摘要。
下面显示所有操作的表格。参数使用以下约定:
"<path>" means any file or directory name. "<path>..." means one or more file or directory names. "<file>" means any filename. "<src>" and "<dest>" are path names in a directed operation. "<localSrc>" and "<localDest>" are paths as above, but on the local file system.
所有其他文件和路径名都指HDFS内部的对象。
| 序号 | 命令和描述 |
|---|---|
| 1 | -ls <path> 列出path指定目录的内容,显示每个条目的名称、权限、所有者、大小和修改日期。 |
| 2 | -lsr <path> 类似于-ls,但递归地显示path所有子目录中的条目。 |
| 3 | -du <path> 显示与path匹配的所有文件的磁盘使用情况(以字节为单位);文件名将使用完整的HDFS协议前缀报告。 |
| 4 | -dus <path> 类似于-du,但打印path中所有文件/目录的磁盘使用情况摘要。 |
| 5 | -mv <src><dest> 将src指示的文件或目录移动到HDFS中的dest。 |
| 6 | -cp <src> <dest> 将src标识的文件或目录复制到HDFS中的dest。 |
| 7 | -rm <path> 删除path标识的文件或空目录。 |
| 8 | -rmr <path> 删除path标识的文件或目录。递归删除任何子条目(即path的文件或子目录)。 |
| 9 | -put <localSrc> <dest> 将本地文件系统中由localSrc标识的文件或目录复制到DFS中的dest。 |
| 10 | -copyFromLocal <localSrc> <dest> 与-put相同 |
| 11 | -moveFromLocal <localSrc> <dest> 将本地文件系统中由localSrc标识的文件或目录复制到HDFS中的dest,然后在成功后删除本地副本。 |
| 12 | -get [-crc] <src> <localDest> 将HDFS中由src标识的文件或目录复制到由localDest标识的本地文件系统路径。 |
| 13 | -getmerge <src> <localDest> 检索HDFS中与路径src匹配的所有文件,并将它们复制到本地文件系统中由localDest标识的单个合并文件中。 |
| 14 | -cat <filen-ame> 在stdout上显示filename的内容。 |
| 15 | -copyToLocal <src> <localDest> 与-get相同 |
| 16 | -moveToLocal <src> <localDest> 类似于-get,但在成功后删除HDFS副本。 |
| 17 | -mkdir <path> 在HDFS中创建名为path的目录。 创建path中任何缺少的父目录(例如,Linux中的mkdir -p)。 |
| 18 | -setrep [-R] [-w] rep <path> 将path标识的文件的目标副本数设置为rep。(实际副本数将随着时间的推移向目标移动) |
| 19 | -touchz <path> 在path处创建一个文件,其中包含当前时间作为时间戳。如果path处已存在文件,则失败,除非文件大小已为0。 |
| 20 | -test -[ezd] <path> 如果path存在;长度为零;或者是一个目录,则返回1;否则返回0。 |
| 21 | -stat [format] <path> 打印有关path的信息。format是一个字符串,它接受以块为单位的文件大小(%b)、文件名(%n)、块大小(%o)、副本数(%r)和修改日期(%y,%Y)。 |
| 22 | -tail [-f] <file2name> 在stdout上显示文件的最后1KB。 |
| 23 | -chmod [-R] mode,mode,... <path>... 更改path…标识的一个或多个对象关联的文件权限。使用R递归执行更改。mode是3位八进制模式,或{augo}+/-{rwxX}。假设如果没有指定范围并且不应用umask。 |
| 24 | -chown [-R] [owner][:[group]] <path>... 设置path…标识的文件或目录的所有者用户和/或组。如果指定-R,则递归设置所有者。 |
| 25 | -chgrp [-R] group <path>... 设置path…标识的文件或目录的所有者组。如果指定-R,则递归设置组。 |
| 26 | -help <cmd-name> 返回上面列出的命令之一的用法信息。您必须省略cmd开头的'-'字符。 |
Hadoop - MapReduce
MapReduce是一个框架,我们可以使用它编写应用程序来并行处理大量数据,在大规模商用硬件集群上可靠地运行。
什么是MapReduce?
MapReduce是一种基于Java的分布式计算处理技术和程序模型。MapReduce算法包含两个重要的任务,即Map和Reduce。Map接收一组数据并将其转换为另一组数据,其中单个元素被分解成元组(键/值对)。其次,reduce任务将map的输出作为输入,并将这些数据元组组合成更小的元组集。正如MapReduce名称的顺序所示,reduce任务总是在map作业之后执行。
MapReduce的主要优势在于它易于跨多个计算节点扩展数据处理。在MapReduce模型下,数据处理原语称为mapper和reducer。将数据处理应用程序分解成mapper和reducer有时并非易事。但是,一旦我们以MapReduce的形式编写应用程序,将应用程序扩展到在集群中的数百、数千甚至数万台机器上运行仅仅是配置更改的问题。这种简单的可扩展性吸引了许多程序员使用MapReduce模型。
算法
通常,MapReduce范例基于将计算发送到数据所在的位置!
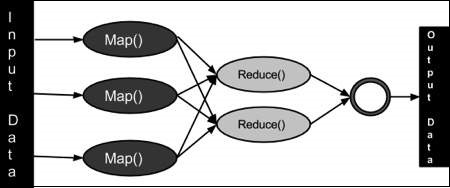
MapReduce程序分三个阶段执行,即map阶段、shuffle阶段和reduce阶段。
Map阶段 − map或mapper的任务是处理输入数据。通常,输入数据是文件或目录的形式,并存储在Hadoop文件系统(HDFS)中。输入文件逐行传递给mapper函数。mapper处理数据并创建多个小的数据块。
Reduce阶段 − 此阶段是Shuffle阶段和Reduce阶段的组合。Reducer的任务是处理来自mapper的数据。处理后,它会生成一组新的输出,这些输出将存储在HDFS中。
在MapReduce作业期间,Hadoop将Map和Reduce任务发送到集群中的相应服务器。
该框架管理所有数据传递细节,例如发出任务、验证任务完成以及在节点之间复制数据。
大部分计算发生在本地磁盘上有数据的节点上,从而减少了网络流量。
给定任务完成后,集群收集并减少数据以形成适当的结果,并将其发送回Hadoop服务器。
输入和输出(Java视角)
MapReduce框架操作于<key, value>对,也就是说,该框架将作业的输入视为一组<key, value>对,并生成一组<key, value>对作为作业的输出,这些对可能属于不同的类型。
键和值类应该以序列化的方式由框架处理,因此需要实现Writable接口。此外,键类必须实现Writable-Comparable接口,以方便框架进行排序。MapReduce作业的输入和输出类型 − (输入) <k1, v1> → map → <k2, v2> → reduce → <k3, v3>(输出)。
| 输入 | 输出 | |
|---|---|---|
| Map | <k1, v1> | 列表 (<k2, v2>) |
| Reduce | <k2, 列表(v2)> | 列表 (<k3, v3>) |
术语
有效载荷 − 应用程序实现Map和Reduce函数,构成作业的核心。
Mapper − Mapper将输入键/值对映射到一组中间键/值对。
NamedNode − 管理Hadoop分布式文件系统(HDFS)的节点。
DataNode − 在任何处理发生之前提前呈现数据的节点。
主节点 (MasterNode) − JobTracker运行的节点,接收来自客户端的作业请求。
从节点 (SlaveNode) − Map和Reduce程序运行的节点。
JobTracker − 调度作业并将分配的作业跟踪到Task tracker。
Task Tracker − 跟踪任务并将状态报告给JobTracker。
作业 (Job) − 程序是在数据集上执行Mapper和Reducer。
任务 (Task) − 在数据片上执行Mapper或Reducer。
任务尝试 (Task Attempt) − 在SlaveNode上执行任务尝试的特定实例。
示例场景
下面是关于某组织电力消耗的数据。它包含各个年份的月度电力消耗和年度平均值。
| 一月 | 二月 | 三月 | 四月 | 五月 | 六月 | 七月 | 八月 | 九月 | 十月 | 十一月 | 十二月 | 平均值 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1979 | 23 | 23 | 2 | 43 | 24 | 25 | 26 | 26 | 26 | 26 | 25 | 26 | 25 |
| 1980 | 26 | 27 | 28 | 28 | 28 | 30 | 31 | 31 | 31 | 30 | 30 | 30 | 29 |
| 1981 | 31 | 32 | 32 | 32 | 33 | 34 | 35 | 36 | 36 | 34 | 34 | 34 | 34 |
| 1984 | 39 | 38 | 39 | 39 | 39 | 41 | 42 | 43 | 40 | 39 | 38 | 38 | 40 |
| 1985 | 38 | 39 | 39 | 39 | 39 | 41 | 41 | 41 | 00 | 40 | 39 | 39 | 45 |
如果以上数据作为输入给出,我们必须编写应用程序来处理它并生成结果,例如查找最大使用量年份、最小使用量年份等等。对于具有有限记录数的程序员来说,这是一个简单的任务。他们只需编写逻辑来生成所需的输出,并将数据传递给编写的应用程序。
但是,考虑一下表示某个州自成立以来所有大型工业的电力消耗的数据。
当我们编写应用程序来处理此类海量数据时,
它们将花费大量时间来执行。
当我们将数据从源移动到网络服务器等等时,将会有大量的网络流量。
为了解决这些问题,我们有MapReduce框架。
输入数据
以上数据保存为sample.txt并作为输入提供。输入文件如下所示。
1979 23 23 2 43 24 25 26 26 26 26 25 26 25 1980 26 27 28 28 28 30 31 31 31 30 30 30 29 1981 31 32 32 32 33 34 35 36 36 34 34 34 34 1984 39 38 39 39 39 41 42 43 40 39 38 38 40 1985 38 39 39 39 39 41 41 41 00 40 39 39 45
示例程序
下面是使用MapReduce框架对示例数据进行处理的程序。
package hadoop;
import java.util.*;
import java.io.IOException;
import java.io.IOException;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
public class ProcessUnits {
//Mapper class
public static class E_EMapper extends MapReduceBase implements
Mapper<LongWritable ,/*Input key Type */
Text, /*Input value Type*/
Text, /*Output key Type*/
IntWritable> /*Output value Type*/
{
//Map function
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
String line = value.toString();
String lasttoken = null;
StringTokenizer s = new StringTokenizer(line,"\t");
String year = s.nextToken();
while(s.hasMoreTokens()) {
lasttoken = s.nextToken();
}
int avgprice = Integer.parseInt(lasttoken);
output.collect(new Text(year), new IntWritable(avgprice));
}
}
//Reducer class
public static class E_EReduce extends MapReduceBase implements Reducer< Text, IntWritable, Text, IntWritable > {
//Reduce function
public void reduce( Text key, Iterator <IntWritable> values,
OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int maxavg = 30;
int val = Integer.MIN_VALUE;
while (values.hasNext()) {
if((val = values.next().get())>maxavg) {
output.collect(key, new IntWritable(val));
}
}
}
}
//Main function
public static void main(String args[])throws Exception {
JobConf conf = new JobConf(ProcessUnits.class);
conf.setJobName("max_eletricityunits");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(E_EMapper.class);
conf.setCombinerClass(E_EReduce.class);
conf.setReducerClass(E_EReduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
将上述程序保存为ProcessUnits.java。程序的编译和执行解释如下。
Process Units程序的编译和执行
让我们假设我们在Hadoop用户的home目录中(例如 /home/hadoop)。
按照以下步骤编译并执行上述程序。
步骤 1
以下命令用于创建一个目录来存储编译后的Java类。
$ mkdir units
步骤 2
下载**Hadoop-core-1.2.1.jar**,该文件用于编译和执行MapReduce程序。访问以下链接mvnrepository.com下载jar包。假设下载后的文件夹路径为** /home/hadoop/。**
步骤 3
以下命令用于编译**ProcessUnits.java**程序并为该程序创建一个jar包。
$ javac -classpath hadoop-core-1.2.1.jar -d units ProcessUnits.java $ jar -cvf units.jar -C units/ .
步骤 4
以下命令用于在HDFS中创建一个输入目录。
$HADOOP_HOME/bin/hadoop fs -mkdir input_dir
步骤 5
以下命令用于将名为**sample.txt**的输入文件复制到HDFS的输入目录中。
$HADOOP_HOME/bin/hadoop fs -put /home/hadoop/sample.txt input_dir
步骤6
以下命令用于验证输入目录中的文件。
$HADOOP_HOME/bin/hadoop fs -ls input_dir/
步骤7
以下命令用于运行Eleunit_max应用程序,并从输入目录读取输入文件。
$HADOOP_HOME/bin/hadoop jar units.jar hadoop.ProcessUnits input_dir output_dir
等待一段时间直到文件执行完毕。执行完毕后,如下所示,输出将包含输入分片数、Map任务数、Reducer任务数等信息。
INFO mapreduce.Job: Job job_1414748220717_0002
completed successfully
14/10/31 06:02:52
INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read = 61
FILE: Number of bytes written = 279400
FILE: Number of read operations = 0
FILE: Number of large read operations = 0
FILE: Number of write operations = 0
HDFS: Number of bytes read = 546
HDFS: Number of bytes written = 40
HDFS: Number of read operations = 9
HDFS: Number of large read operations = 0
HDFS: Number of write operations = 2 Job Counters
Launched map tasks = 2
Launched reduce tasks = 1
Data-local map tasks = 2
Total time spent by all maps in occupied slots (ms) = 146137
Total time spent by all reduces in occupied slots (ms) = 441
Total time spent by all map tasks (ms) = 14613
Total time spent by all reduce tasks (ms) = 44120
Total vcore-seconds taken by all map tasks = 146137
Total vcore-seconds taken by all reduce tasks = 44120
Total megabyte-seconds taken by all map tasks = 149644288
Total megabyte-seconds taken by all reduce tasks = 45178880
Map-Reduce Framework
Map input records = 5
Map output records = 5
Map output bytes = 45
Map output materialized bytes = 67
Input split bytes = 208
Combine input records = 5
Combine output records = 5
Reduce input groups = 5
Reduce shuffle bytes = 6
Reduce input records = 5
Reduce output records = 5
Spilled Records = 10
Shuffled Maps = 2
Failed Shuffles = 0
Merged Map outputs = 2
GC time elapsed (ms) = 948
CPU time spent (ms) = 5160
Physical memory (bytes) snapshot = 47749120
Virtual memory (bytes) snapshot = 2899349504
Total committed heap usage (bytes) = 277684224
File Output Format Counters
Bytes Written = 40
步骤8
以下命令用于验证输出文件夹中的结果文件。
$HADOOP_HOME/bin/hadoop fs -ls output_dir/
步骤9
以下命令用于查看**Part-00000**文件中的输出。此文件由HDFS生成。
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000
以下是MapReduce程序生成的输出。
1981 34 1984 40 1985 45
步骤10
以下命令用于将输出文件夹从HDFS复制到本地文件系统以进行分析。
$HADOOP_HOME/bin/hadoop fs -cat output_dir/part-00000/bin/hadoop dfs get output_dir /home/hadoop
重要命令
所有Hadoop命令都通过**$HADOOP_HOME/bin/hadoop**命令调用。运行Hadoop脚本而不带任何参数将打印所有命令的描述。
**用法** − hadoop [--config confdir] COMMAND
下表列出了可用的选项及其描述。
| 序号 | 选项和描述 |
|---|---|
| 1 | namenode -format 格式化DFS文件系统。 |
| 2 | secondarynamenode 运行DFS辅助NameNode。 |
| 3 | namenode 运行DFS NameNode。 |
| 4 | datanode 运行DFS DataNode。 |
| 5 | dfsadmin 运行DFS管理客户端。 |
| 6 | mradmin 运行Map-Reduce管理客户端。 |
| 7 | fsck 运行DFS文件系统检查实用程序。 |
| 8 | fs 运行通用文件系统用户客户端。 |
| 9 | balancer 运行集群平衡实用程序。 |
| 10 | oiv 将离线fsimage查看器应用于fsimage。 |
| 11 | fetchdt 从NameNode获取委托令牌。 |
| 12 | jobtracker 运行MapReduce JobTracker节点。 |
| 13 | pipes 运行Pipes作业。 |
| 14 | tasktracker 运行MapReduce TaskTracker节点。 |
| 15 | historyserver 作为独立守护进程运行作业历史服务器。 |
| 16 | job 操作MapReduce作业。 |
| 17 | queue 获取有关JobQueue的信息。 |
| 18 | version 打印版本。 |
| 19 | jar <jar> 运行jar文件。 |
| 20 | distcp <srcurl> <desturl> 递归复制文件或目录。 |
| 21 | distcp2 <srcurl> <desturl> DistCp版本2。 |
| 22 | archive -archiveName NAME -p <parent path> <src>* <dest> 创建Hadoop归档。 |
| 23 | classpath 打印获取Hadoop jar和所需库所需的类路径。 |
| 24 | daemonlog 获取/设置每个守护程序的日志级别 |
如何与MapReduce作业交互
用法 − hadoop job [GENERIC_OPTIONS]
以下是Hadoop作业中可用的通用选项。
| 序号 | GENERIC_OPTION和描述 |
|---|---|
| 1 | -submit <job-file> 提交作业。 |
| 2 | -status <job-id> 打印映射和归并完成百分比以及所有作业计数器。 |
| 3 | -counter <job-id> <group-name> <countername> 打印计数器值。 |
| 4 | -kill <job-id> 杀死作业。 |
| 5 | -events <job-id> <fromevent-#> <#-of-events> 打印JobTracker在给定范围内接收的事件详细信息。 |
| 6 | -history [all] <jobOutputDir> - history < jobOutputDir> 打印作业详细信息、失败和被杀死的提示详细信息。通过指定[all]选项,可以查看有关作业的更多详细信息,例如每个任务成功完成的任务和任务尝试次数。 |
| 7 | -list[all] 显示所有作业。-list仅显示尚未完成的作业。 |
| 8 | -kill-task <task-id> 杀死任务。被杀死的任务不计入失败的尝试次数。 |
| 9 | -fail-task <task-id> 使任务失败。失败的任务计入失败的尝试次数。 |
| 10 | -set-priority <job-id> <priority> 更改作业的优先级。允许的优先级值为VERY_HIGH、HIGH、NORMAL、LOW、VERY_LOW |
查看作业状态
$ $HADOOP_HOME/bin/hadoop job -status <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -status job_201310191043_0004
查看作业输出目录的历史记录
$ $HADOOP_HOME/bin/hadoop job -history <DIR-NAME> e.g. $ $HADOOP_HOME/bin/hadoop job -history /user/expert/output
杀死作业
$ $HADOOP_HOME/bin/hadoop job -kill <JOB-ID> e.g. $ $HADOOP_HOME/bin/hadoop job -kill job_201310191043_0004
Hadoop - 流处理 (Streaming)
Hadoop streaming是Hadoop发行版中自带的一个实用程序。此实用程序允许您使用任何可执行文件或脚本作为mapper和/或reducer来创建和运行Map/Reduce作业。
使用Python的示例
对于Hadoop streaming,我们考虑单词计数问题。Hadoop中的任何作业都必须包含两个阶段:mapper和reducer。我们已经用python脚本编写了mapper和reducer的代码,以便在Hadoop下运行它。也可以用Perl和Ruby编写相同的代码。
Mapper阶段代码
!/usr/bin/python
import sys
# Input takes from standard input for myline in sys.stdin:
# Remove whitespace either side
myline = myline.strip()
# Break the line into words
words = myline.split()
# Iterate the words list
for myword in words:
# Write the results to standard output
print '%s\t%s' % (myword, 1)
确保此文件具有执行权限(chmod +x /home/expert/hadoop-1.2.1/mapper.py)。
Reducer阶段代码
#!/usr/bin/python
from operator import itemgetter
import sys
current_word = ""
current_count = 0
word = ""
# Input takes from standard input for myline in sys.stdin:
# Remove whitespace either side
myline = myline.strip()
# Split the input we got from mapper.py word,
count = myline.split('\t', 1)
# Convert count variable to integer
try:
count = int(count)
except ValueError:
# Count was not a number, so silently ignore this line continue
if current_word == word:
current_count += count
else:
if current_word:
# Write result to standard output print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# Do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)
将mapper和reducer代码保存在Hadoop主目录下的mapper.py和reducer.py中。确保这些文件具有执行权限(chmod +x mapper.py和chmod +x reducer.py)。由于python对缩进敏感,因此可以从以下链接下载相同的代码。
WordCount程序的执行
$ $HADOOP_HOME/bin/hadoop jar contrib/streaming/hadoop-streaming-1. 2.1.jar \ -input input_dirs \ -output output_dir \ -mapper <path/mapper.py \ -reducer <path/reducer.py
其中“\”用于换行,以便清晰易读。
例如:
./bin/hadoop jar contrib/streaming/hadoop-streaming-1.2.1.jar -input myinput -output myoutput -mapper /home/expert/hadoop-1.2.1/mapper.py -reducer /home/expert/hadoop-1.2.1/reducer.py
Streaming的工作原理
在上面的示例中,mapper和reducer都是python脚本,它们从标准输入读取输入,并将输出发送到标准输出。该实用程序将创建一个Map/Reduce作业,将作业提交到合适的集群,并监视作业的进度,直到它完成。
当为mapper指定脚本时,在初始化mapper时,每个mapper任务都会将脚本作为单独的进程启动。当mapper任务运行时,它会将其输入转换为行,并将行馈送到进程的标准输入(STDIN)。同时,mapper会从进程的标准输出(STDOUT)收集面向行的输出,并将每一行转换为键/值对,这些键/值对作为mapper的输出收集。默认情况下,一行中第一个制表符之前的部分是键,其余部分(不包括制表符)是值。如果行中没有制表符,则整行都被视为键,而值为空。但是,可以根据需要自定义此设置。
当为reducer指定脚本时,在初始化reducer时,每个reducer任务都会将脚本作为单独的进程启动。当reducer任务运行时,它会将其输入键/值对转换为行,并将行馈送到进程的标准输入(STDIN)。同时,reducer会从进程的标准输出(STDOUT)收集面向行的输出,并将每一行转换为键/值对,这些键/值对作为reducer的输出收集。默认情况下,一行中第一个制表符之前的部分是键,其余部分(不包括制表符)是值。但是,可以根据特定需求自定义此设置。
重要命令
| 参数 | 选项 | 描述 |
|---|---|---|
| -input directory/file-name | 必需 | mapper的输入位置。 |
| -output directory-name | 必需 | reducer的输出位置。 |
| -mapper 可执行文件或脚本或JavaClassName | 必需 | Mapper可执行文件。 |
| -reducer 可执行文件或脚本或JavaClassName | 必需 | Reducer可执行文件。 |
| -file file-name | 可选 | 使mapper、reducer或combiner可执行文件在计算节点上本地可用。 |
| -inputformat JavaClassName | 可选 | 您提供的类应返回Text类的键/值对。如果未指定,则使用TextInputFormat作为默认值。 |
| -outputformat JavaClassName | 可选 | 您提供的类应采用Text类的键/值对。如果未指定,则使用TextOutputformat作为默认值。 |
| -partitioner JavaClassName | 可选 | 确定将哪个键发送到哪个reduce的类。 |
| -combiner streamingCommand 或 JavaClassName | 可选 | map输出的Combiner可执行文件。 |
| -cmdenv name=value | 可选 | 将环境变量传递给streaming命令。 |
| -inputreader | 可选 | 为了向后兼容性:指定记录读取器类(而不是输入格式类)。 |
| -verbose | 可选 | 详细输出。 |
| -lazyOutput | 可选 | 延迟创建输出。例如,如果输出格式基于FileOutputFormat,则只有在第一次调用output.collect(或Context.write)时才会创建输出文件。 |
| -numReduceTasks | 可选 | 指定reducer的数量。 |
| -mapdebug | 可选 | map任务失败时要调用的脚本。 |
| -reducedebug | 可选 | reduce任务失败时要调用的脚本。 |
Hadoop - 多节点集群
本章介绍在分布式环境中设置Hadoop多节点集群。
由于无法演示整个集群,我们将使用三个系统(一个主节点和两个从节点)来解释Hadoop集群环境;以下是它们的IP地址。
- Hadoop主节点:192.168.1.15 (hadoop-master)
- Hadoop从节点:192.168.1.16 (hadoop-slave-1)
- Hadoop从节点:192.168.1.17 (hadoop-slave-2)
按照以下步骤设置Hadoop多节点集群。
安装 Java
Java是Hadoop的主要前提条件。首先,您应该使用“java -version”验证系统中是否存在java。java版本命令的语法如下所示。
$ java -version
如果一切正常,它将为您提供以下输出。
java version "1.7.0_71" Java(TM) SE Runtime Environment (build 1.7.0_71-b13) Java HotSpot(TM) Client VM (build 25.0-b02, mixed mode)
如果您的系统中未安装java,请按照给定的步骤安装java。
步骤 1
访问以下链接下载java(JDK <最新版本> - X64.tar.gz)www.oracle.com
然后jdk-7u71-linux-x64.tar.gz 将下载到您的系统中。
步骤 2
通常,您会在 Downloads 文件夹中找到下载的 java 文件。验证它并使用以下命令解压jdk-7u71-linux-x64.gz 文件。
$ cd Downloads/ $ ls jdk-7u71-Linux-x64.gz $ tar zxf jdk-7u71-Linux-x64.gz $ ls jdk1.7.0_71 jdk-7u71-Linux-x64.gz
步骤 3
要使所有用户都能使用java,您必须将其移动到“/usr/local/”位置。打开root用户,然后输入以下命令。
$ su password: # mv jdk1.7.0_71 /usr/local/ # exit
步骤 4
要设置PATH 和JAVA_HOME 变量,请将以下命令添加到~/.bashrc 文件中。
export JAVA_HOME=/usr/local/jdk1.7.0_71 export PATH=PATH:$JAVA_HOME/bin
现在,如上所述,从终端验证**java -version**命令。按照上述过程,在所有集群节点上安装java。
创建用户帐户
在主节点和从节点上创建一个系统用户帐户来使用Hadoop安装。
# useradd hadoop # passwd hadoop
映射节点
您必须在所有节点上的**/etc/**文件夹中编辑**hosts**文件,指定每个系统的IP地址及其主机名。
# vi /etc/hosts enter the following lines in the /etc/hosts file. 192.168.1.109 hadoop-master 192.168.1.145 hadoop-slave-1 192.168.56.1 hadoop-slave-2
配置基于密钥的登录
在每个节点上设置ssh,以便它们可以相互通信,而无需任何密码提示。
# su hadoop $ ssh-keygen -t rsa $ ssh-copy-id -i ~/.ssh/id_rsa.pub tutorialspoint@hadoop-master $ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp1@hadoop-slave-1 $ ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop_tp2@hadoop-slave-2 $ chmod 0600 ~/.ssh/authorized_keys $ exit
安装Hadoop
在主服务器中,使用以下命令下载并安装Hadoop。
# mkdir /opt/hadoop # cd /opt/hadoop/ # wget http://apache.mesi.com.ar/hadoop/common/hadoop-1.2.1/hadoop-1.2.0.tar.gz # tar -xzf hadoop-1.2.0.tar.gz # mv hadoop-1.2.0 hadoop # chown -R hadoop /opt/hadoop # cd /opt/hadoop/hadoop/
配置Hadoop
您必须通过进行以下更改来配置Hadoop服务器,如下所示。
core-site.xml
打开**core-site.xml**文件并按如下所示进行编辑。
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://hadoop-master:9000/</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
hdfs-site.xml
打开**hdfs-site.xml**文件并按如下所示进行编辑。
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/opt/hadoop/hadoop/dfs/name/data</value>
<final>true</final>
</property>
<property>
<name>dfs.name.dir</name>
<value>/opt/hadoop/hadoop/dfs/name</value>
<final>true</final>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
mapred-site.xml
打开**mapred-site.xml**文件并按如下所示进行编辑。
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop-master:9001</value>
</property>
</configuration>
hadoop-env.sh
打开**hadoop-env.sh**文件并按如下所示编辑JAVA_HOME、HADOOP_CONF_DIR和HADOOP_OPTS。
**注意** − 根据您的系统配置设置JAVA_HOME。
export JAVA_HOME=/opt/jdk1.7.0_17 export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true export HADOOP_CONF_DIR=/opt/hadoop/hadoop/conf
在从服务器上安装Hadoop
按照以下命令在所有从服务器上安装 Hadoop。
# su hadoop $ cd /opt/hadoop $ scp -r hadoop hadoop-slave-1:/opt/hadoop $ scp -r hadoop hadoop-slave-2:/opt/hadoop
在主服务器上配置 Hadoop
打开主服务器并按照以下命令进行配置。
# su hadoop $ cd /opt/hadoop/hadoop
配置主节点
$ vi etc/hadoop/masters hadoop-master
配置从节点
$ vi etc/hadoop/slaves hadoop-slave-1 hadoop-slave-2
格式化 Hadoop 主服务器上的 Name Node
# su hadoop $ cd /opt/hadoop/hadoop $ bin/hadoop namenode –format 11/10/14 10:58:07 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = hadoop-master/192.168.1.109 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 1.2.0 STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-1.2 -r 1479473; compiled by 'hortonfo' on Mon May 6 06:59:37 UTC 2013 STARTUP_MSG: java = 1.7.0_71 ************************************************************/ 11/10/14 10:58:08 INFO util.GSet: Computing capacity for map BlocksMap editlog=/opt/hadoop/hadoop/dfs/name/current/edits …………………………………………………. …………………………………………………. …………………………………………………. 11/10/14 10:58:08 INFO common.Storage: Storage directory /opt/hadoop/hadoop/dfs/name has been successfully formatted. 11/10/14 10:58:08 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop-master/192.168.1.15 ************************************************************/
启动 Hadoop 服务
以下命令用于在 Hadoop-Master 上启动所有 Hadoop 服务。
$ cd $HADOOP_HOME/sbin $ start-all.sh
在 Hadoop 集群中添加新的 DataNode
以下是将新节点添加到 Hadoop 集群的步骤。
网络
使用一些适当的网络配置将新节点添加到现有的 Hadoop 集群。假设以下网络配置。
对于新节点配置 -
IP address : 192.168.1.103 netmask : 255.255.255.0 hostname : slave3.in
添加用户和 SSH 访问
添加用户
在新节点上,添加“hadoop”用户,并使用以下命令将 Hadoop 用户的密码设置为“hadoop123”或任何您想要的密码。
useradd hadoop passwd hadoop
设置从主服务器到新从服务器的无密码连接。
在主服务器上执行以下操作
mkdir -p $HOME/.ssh chmod 700 $HOME/.ssh ssh-keygen -t rsa -P '' -f $HOME/.ssh/id_rsa cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys chmod 644 $HOME/.ssh/authorized_keys Copy the public key to new slave node in hadoop user $HOME directory scp $HOME/.ssh/id_rsa.pub hadoop@192.168.1.103:/home/hadoop/
在从服务器上执行以下操作
登录到 hadoop。如果没有,请登录到 hadoop 用户。
su hadoop ssh -X hadoop@192.168.1.103
将公钥的内容复制到文件"$HOME/.ssh/authorized_keys"中,然后通过执行以下命令更改其权限。
cd $HOME mkdir -p $HOME/.ssh chmod 700 $HOME/.ssh cat id_rsa.pub >>$HOME/.ssh/authorized_keys chmod 644 $HOME/.ssh/authorized_keys
检查来自主机的 ssh 登录。现在检查是否可以从主服务器无密码 ssh 到新节点。
ssh hadoop@192.168.1.103 or hadoop@slave3
设置新节点的主机名
您可以在文件/etc/sysconfig/network中设置主机名
On new slave3 machine NETWORKING = yes HOSTNAME = slave3.in
要使更改生效,请重新启动机器或使用相应的主机名运行主机名命令到新机器(重新启动是一个不错的选择)。
在 slave3 节点机器上 -
hostname slave3.in
使用以下行更新集群所有机器上的/etc/hosts -
192.168.1.102 slave3.in slave3
现在尝试使用主机名 ping 机器,以检查它是否解析为 IP。
在新节点机器上 -
ping master.in
启动新节点上的 DataNode
使用$HADOOP_HOME/bin/hadoop-daemon.sh 脚本手动启动 datanode 守护进程。它将自动联系主服务器 (NameNode) 并加入集群。我们还应该将新节点添加到主服务器中的 conf/slaves 文件中。基于脚本的命令将识别新节点。
登录到新节点
su hadoop or ssh -X hadoop@192.168.1.103
使用以下命令在新添加的从节点上启动 HDFS
./bin/hadoop-daemon.sh start datanode
检查新节点上 jps 命令的输出。它如下所示。
$ jps 7141 DataNode 10312 Jps
从 Hadoop 集群中删除 DataNode
我们可以在集群运行时随时删除节点,而不会丢失任何数据。HDFS 提供了一个退役功能,确保安全地执行节点删除。要使用它,请按照以下步骤操作 -
步骤 1 - 登录到主服务器
登录到安装了 Hadoop 的主服务器用户。
$ su hadoop
步骤 2 - 更改集群配置
必须在启动集群之前配置排除文件。在我们的$HADOOP_HOME/etc/hadoop/hdfs-site.xml文件中添加一个名为 dfs.hosts.exclude 的键。与此键关联的值提供了 NameNode 本地文件系统上文件的完整路径,该文件包含不允许连接到 HDFS 的机器列表。
例如,将这些行添加到etc/hadoop/hdfs-site.xml文件中。
<property> <name>dfs.hosts.exclude</name> <value>/home/hadoop/hadoop-1.2.1/hdfs_exclude.txt</value> <description>DFS exclude</description> </property>
步骤 3 - 确定要退役的主机
每个要退役的机器都应添加到 hdfs_exclude.txt 文件中,每行一个域名。这将阻止它们连接到 NameNode。如果您想删除 DataNode2,则显示"/home/hadoop/hadoop-1.2.1/hdfs_exclude.txt"文件的内容如下所示。
slave2.in
步骤 4 - 强制重新加载配置
运行命令"$HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes"(无需引号)。
$ $HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes
这将强制 NameNode 重新读取其配置,包括新更新的“排除”文件。它将在一段时间内退役这些节点,从而为将每个节点的块复制到计划保持活动的机器上留出时间。
在slave2.in上,检查 jps 命令的输出。一段时间后,您将看到 DataNode 进程自动关闭。
步骤 5 - 关闭节点
退役过程完成后,可以安全地关闭退役的硬件以进行维护。运行 dfsadmin 的 report 命令以检查退役的状态。以下命令将描述退役节点和连接到集群的节点的状态。
$ $HADOOP_HOME/bin/hadoop dfsadmin -report
步骤 6 - 再次编辑排除文件
退役机器后,可以将其从“排除”文件中删除。再次运行"$HADOOP_HOME/bin/hadoop dfsadmin -refreshNodes"将把排除文件重新读入 NameNode;允许 DataNode 在维护完成后或集群再次需要额外容量时重新加入集群等。
特别说明 - 如果按照上述步骤操作,并且节点上仍然运行 tasktracker 进程,则需要将其关闭。一种方法是像我们在上述步骤中所做的那样断开机器的连接。主服务器将自动识别该进程并将其声明为已死。无需遵循相同的过程来删除 tasktracker,因为它与 DataNode 相比并不那么重要。DataNode 包含您想要安全删除的数据,而不会丢失任何数据。
tasktracker 可以随时通过以下命令运行/关闭。
$ $HADOOP_HOME/bin/hadoop-daemon.sh stop tasktracker $HADOOP_HOME/bin/hadoop-daemon.sh start tasktracker