- Haskell 教程
- Haskell - 首页
- Haskell - 概述
- Haskell - 环境搭建
- Haskell - 基本数据模型
- Haskell - 基本运算符
- Haskell - 决策
- Haskell - 类型和类型类
- Haskell - 函数
- Haskell - 函数详解
- Haskell - 函数组合
- Haskell - 模块
- Haskell - 输入与输出
- Haskell - Functor (函子)
- Haskell - Monad (单子)
- Haskell - Zipper (拉链)
- Haskell 有用资源
- Haskell 快速指南
- Haskell - 有用资源
- Haskell - 讨论
Haskell 快速指南
Haskell - 概述
Haskell 是一种函数式编程语言,专门设计用于处理符号计算和列表处理应用程序。函数式编程基于数学函数。除了 Haskell,其他一些遵循函数式编程范式的流行语言包括:Lisp、Python、Erlang、Racket、F#、Clojure 等。
在传统编程中,指令被视为特定语法或格式的一组声明,但在函数式编程中,所有计算都被视为单独数学函数的组合。
使用 Haskell 进行函数式编程
Haskell 是一种广泛使用的纯函数式语言。这里,我们列出了一些使 Haskell 比其他传统编程语言(如 Java、C、C++、PHP 等)更特殊的几点。
函数式语言 - 在传统编程语言中,我们指示编译器一系列任务,这仅仅是告诉你的计算机“做什么”和“如何做?”。但在 Haskell 中,我们将告诉计算机“它是什么?”
惰性求值 - Haskell 是一种惰性语言。惰性意味着 Haskell 不会无缘无故地计算任何表达式。当求值引擎发现需要计算某个表达式时,它会创建一个thunk 数据结构来收集该特定求值所需的所有信息以及指向该thunk 数据结构的指针。只有当需要计算该特定表达式时,求值引擎才会开始工作。
模块化 - Haskell 应用程序只是一系列函数。我们可以说 Haskell 应用程序是许多小型 Haskell 应用程序的集合。
静态类型 - 在传统编程语言中,我们需要定义一系列变量及其类型。相反,Haskell 是一种类型推断语言。类型推断语言意味着 Haskell 编译器足够智能,可以推断出声明的变量的类型,因此我们不需要显式提及所用变量的类型。
可维护性 - Haskell 应用程序是模块化的,因此维护它们非常容易且经济高效。
函数式程序更具并发性,并且遵循并行执行以提供更准确和更好的性能。Haskell 也不例外;它已被开发用于有效地处理多线程。
Hello World
这是一个简单的例子,用于演示 Haskell 的动态性。请看下面的代码。我们只需要一行代码就可以在控制台上打印“Hello World”。
main = putStrLn "Hello World"
一旦 Haskell 编译器遇到上述代码段,它就会立即产生以下输出:
Hello World
我们将在这个教程中提供大量的例子来展示 Haskell 的强大和简单性。
Haskell - 环境搭建
我们在以下网站上设置了在线 Haskell 编程环境:https://tutorialspoint.com/compile_haskell_online.php
这个在线编辑器有很多选项可以练习 Haskell 编程示例。转到页面的终端部分并键入“ghci”。此命令会自动加载 Haskell 编译器并启动在线 Haskell。使用ghci命令后,您将收到以下输出。
sh-4.3$ ghci GHCi,version7.8.4:http://www.haskell.org/ghc/:?forhelp Loading package ghc-prim...linking...done. Loading packageinteger gmp...linking... done. Loading package base...linking...done. Prelude>
如果您仍然想在本地系统中离线使用 Haskell,则需要从其官方网页下载可用的 Haskell 安装程序:https://www.haskell.org/downloads
市场上有三种不同类型的安装程序:
最小安装程序 - 它提供 GHC(Glasgow Haskell 编译器)、CABAL(应用程序和库的通用架构)和 Stack 工具。
Stack 安装程序 - 在此安装程序中,GHC 可以跨平台下载到受管理的工具链中。它将在全局安装您的应用程序,以便它可以在需要时更新其 API 工具。它会自动解决所有面向 Haskell 的依赖项。
Haskell 平台 - 这是安装 Haskell 的最佳方法,因为它会将整个平台安装到您的机器上,并且是从一个特定位置安装的。此安装程序不像上面两个安装程序那样是可分发的。
我们已经看到了市场上不同类型的安装程序,现在让我们看看如何在我们的机器上使用这些安装程序。在本教程中,我们将使用 Haskell 平台安装程序在我们的系统中安装 Haskell 编译器。
Windows 环境搭建
要在 Windows 计算机上设置 Haskell 环境,请访问其官方网站https://www.haskell.org/platform/windows.html并根据您的可定制架构下载安装程序。
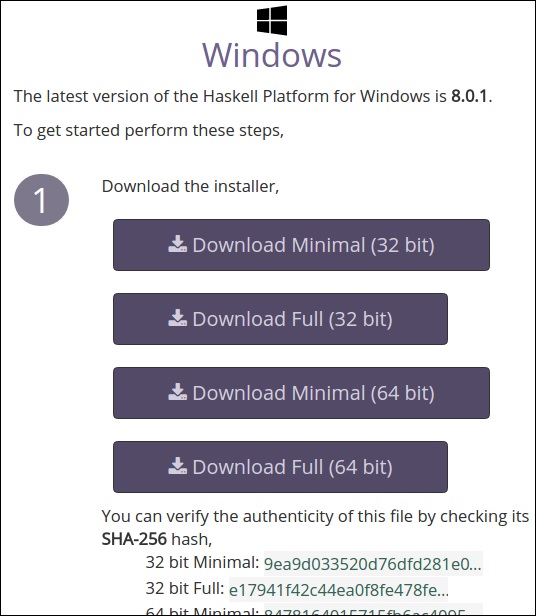
查看您系统的架构并下载相应的安装文件并运行它。它将像任何其他 Windows 应用程序一样安装。您可能需要更新系统的 CABAL 配置。
MAC 环境搭建
要在 MAC 系统上设置 Haskell 环境,请访问其官方网站https://www.haskell.org/platform/mac.html并下载 Mac 安装程序。
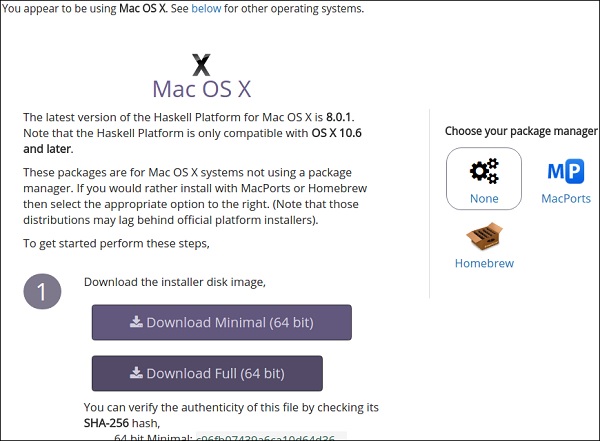
Linux 环境搭建
在基于 Linux 的系统上安装 Haskell 需要运行一些命令,这不像 MAC 和 Windows 那样容易。是的,它很费力,但它是可靠的。
您可以按照以下步骤在 Linux 系统上安装 Haskell:
步骤 1 - 要在 Linux 系统上设置 Haskell 环境,请访问官方网站https://www.haskell.org/platform/linux.html并选择您的发行版。您将在浏览器上看到以下屏幕。
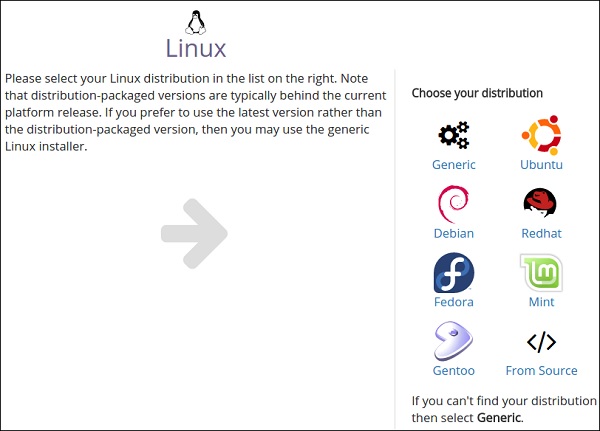
步骤 2 - 选择您的发行版。在本例中,我们使用 Ubuntu。选择此选项后,您将在屏幕上看到以下页面,其中包含在本地系统中安装 Haskell 的命令。
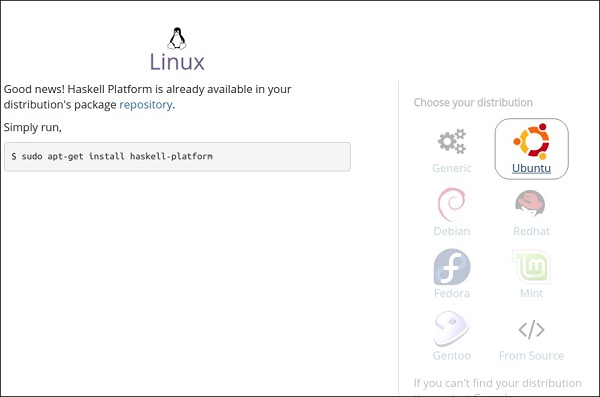
步骤 3 - 按 Ctrl + Alt + T 打开终端。运行命令“$ sudo apt-get install haskell-platform”并按 Enter。在使用 root 密码进行身份验证后,它将自动开始在您的系统上下载 Haskell。安装完成后,您将收到确认消息。
步骤 4 - 再次进入终端并运行 GHCI 命令。一旦您得到 Prelude 提示符,您就可以在本地系统上使用 Haskell 了。
要退出 GHCI 提示符,可以使用命令“:quit exit”。
Haskell - 基本数据模型
Haskell 是一种纯函数式编程语言,因此它比其他编程语言更具交互性和智能性。在本章中,我们将学习 Haskell 的基本数据模型,这些模型实际上是预定义的,或者以某种方式巧妙地解码到计算机内存中。
在本教程中,我们将使用我们网站上提供的在线 Haskell 平台(https://tutorialspoint.com/codingground.htm)。
数字
Haskell 足够智能,可以将一些数字解码为数字。因此,您不需要像在其他编程语言中通常那样从外部提及其类型。例如,转到您的 prelude 命令提示符并运行“2+2”,然后按 Enter。
sh-4.3$ ghci GHCi, version 7.6.3: http://www.haskell.org/ghc/ :? for help Loading package ghc-prim ... linking ... done. Loading package integer-gmp ... linking ... done. Loading package base ... linking ... done. Prelude> 2+2
您将收到以下输出作为结果。
4
在上面的代码中,我们只是将两个数字作为参数传递给 GHCI 编译器而没有预定义它们的类型,但编译器可以轻松地将这两个条目解码为数字。
现在,让我们尝试更复杂的数学计算,看看我们的智能编译器是否能给我们正确的输出。尝试使用“15+(5*5)-40”。
Prelude> 15+(5*5)-40
根据预期输出,上述表达式产生“0”。
0
字符
像数字一样,Haskell 可以智能地识别作为输入给它的字符。转到您的 Haskell 命令提示符并键入带双引号或单引号的任何字符。
让我们提供以下行作为输入并检查其输出。
Prelude> :t "a"
它将产生以下输出:
"a" :: [Char]
记住在提供输入时使用 (:t)。在上面的示例中,(:t) 用于包含与输入相关的特定类型。我们将在接下来的章节中更多地了解这种类型。
让我们来看下面的例子,我们将一些无效的输入作为字符传递,这反过来会导致错误。
Prelude> :t a <interactive>:1:1: Not in scope: 'a' Prelude> a <interactive>:4:1: Not in scope: 'a'
通过错误消息“<interactive>:4:1: Not in scope: `a'”,Haskell 编译器警告我们它无法识别您的输入。Haskell 是一种所有内容都使用数字表示的语言。
Haskell 遵循传统的 ASCII 编码风格。让我们来看下面的例子,以了解更多信息:
Prelude> '\97' 'a' Prelude> '\67' 'C'
看看您的输入是如何解码成 ASCII 格式的。
字符串
字符串只是一组字符。使用字符串没有具体的语法,但 Haskell 遵循用双引号表示字符串的传统风格。
让我们来看下面的例子,我们将传递字符串“Tutorialspoint.com”。
Prelude> :t "tutorialspoint.com"
它将在屏幕上产生以下输出:
"tutorialspoint.com" :: [Char]
看看整个字符串是如何被解码为仅由 Char 组成的数组的。让我们转向其他数据类型及其语法。一旦我们开始实际练习,我们将习惯所有数据类型及其用法。
布尔值
布尔数据类型与其他数据类型一样非常直接。看看下面的例子,我们将使用一些布尔输入(如“True”或“False”)使用不同的布尔运算。
Prelude> True && True True Prelude> True && False False Prelude> True || True True Prelude> True || False True
在上面的例子中,我们不需要提到“True”和“False”是布尔值。Haskell 本身可以解码它并执行相应的运算。让我们用“true”或“false”修改我们的输入。
Prelude> true
它将产生以下输出:
<interactive>:9:1: Not in scope: 'true'
在上面的例子中,Haskell 无法区分“true”和数值,因此我们的输入“true”不是数字。因此,Haskell 编译器抛出一个错误,指出我们的输入不在其范围内。
列表和列表推导
像其他数据类型一样,列表 (List) 也是 Haskell 中非常有用的数据类型。例如,[a,b,c] 是一个字符列表,因此,根据定义,列表是由逗号分隔的相同数据类型的集合。
与其他数据类型一样,您不需要声明列表为列表。Haskell 足够智能,可以根据表达式中使用的语法来解码您的输入。
让我们来看下面的例子,它展示了 Haskell 如何处理列表。
Prelude> [1,2,3,4,5]
它将产生以下输出:
[1,2,3,4,5]
Haskell 中的列表是同构的,这意味着它们不允许您声明不同类型数据的列表。任何像 [1,2,3,4,5,a,b,c,d,e,f] 这样的列表都会产生错误。
Prelude> [1,2,3,4,5,a,b,c,d,e,f]
这段代码将产生以下错误:
<interactive>:17:12: Not in scope: 'a' <interactive>:17:14: Not in scope: 'b' <interactive>:17:16: Not in scope: 'c' <interactive>:17:18: Not in scope: 'd' <interactive>:17:20: Not in scope: 'e' <interactive>:17:22: Not in scope: 'f'
列表推导式 (List Comprehension)
列表推导式是使用数学表达式生成列表的过程。看下面的例子,我们正在使用“[输出 | 范围,条件]”格式的数学表达式生成列表。
Prelude> [x*2| x<-[1..10]] [2,4,6,8,10,12,14,16,18,20] Prelude> [x*2| x<-[1..5]] [2,4,6,8,10] Prelude> [x| x<-[1..5]] [1,2,3,4,5]
这种使用数学表达式创建列表的方法称为列表推导式 (List Comprehension)。
元组 (Tuple)
Haskell 提供了另一种在单个数据类型中声明多个值的方法。它被称为元组 (Tuple)。元组可以被认为是列表,但是元组和列表之间存在一些技术差异。
元组是不可变的数据类型,我们不能在运行时修改元素的数量,而列表是可变的数据类型。
另一方面,列表是同构的数据类型,但元组是异构的,因为元组可以包含不同类型的数据。
元组由单括号表示。请看下面的例子,了解 Haskell 如何处理元组。
Prelude> (1,1,'a')
它将产生以下输出:
(1,1,'a')
在上面的例子中,我们使用了一个包含两个数字类型变量和一个字符类型变量的元组。
Haskell - 基本运算符
在本章中,我们将学习 Haskell 中使用的不同运算符。与其他编程语言一样,Haskell 智能地处理一些基本的运算,如加法、减法、乘法等。在接下来的章节中,我们将学习更多关于不同运算符及其用法的知识。
在本章中,我们将使用我们的在线平台 (https://tutorialspoint.com/codingground.htm) 中 Haskell 的不同运算符。请记住,我们只使用整数类型数字,因为我们将在后续章节中学习更多关于小数类型数字的知识。
加法运算符
顾名思义,加法运算符 (+) 用于加法运算。以下示例代码展示了如何在 Haskell 中添加两个整数:
main = do let var1 = 2 let var2 = 3 putStrLn "The addition of the two numbers is:" print(var1 + var2)
在上面的文件中,我们创建了两个单独的变量var1 和 var2。最后,我们使用加法运算符打印结果。使用编译和执行按钮运行您的代码。
这段代码将在屏幕上产生以下输出:
The addition of the two numbers is: 5
减法运算符
顾名思义,此运算符用于减法运算。以下示例代码展示了如何在 Haskell 中减去两个整数:
main = do let var1 = 10 let var2 = 6 putStrLn "The Subtraction of the two numbers is:" print(var1 - var2)
在这个例子中,我们创建了两个变量var1 和 var2。然后,我们使用减法 (-) 运算符来减去这两个值。
这段代码将在屏幕上产生以下输出:
The Subtraction of the two numbers is: 4
乘法运算符
此运算符用于乘法运算。以下代码展示了如何使用乘法运算符在 Haskell 中乘以两个数字:
main = do let var1 = 2 let var2 = 3 putStrLn "The Multiplication of the Two Numbers is:" print(var1 * var2)
当您在我们的在线平台上运行此代码时,它将产生以下输出:
The Multiplication of the Two Numbers is: 6
除法运算符
请看下面的代码。它展示了如何在 Haskell 中除以两个数字:
main = do let var1 = 12 let var2 = 3 putStrLn "The Division of the Two Numbers is:" print(var1/var2)
它将产生以下输出:
The Division of the Two Numbers is: 4.0
序列/范围运算符
序列或范围是 Haskell 中的一个特殊运算符。它用 "(..)" 表示。在声明具有值序列的列表时,可以使用此运算符。
如果您想打印从 1 到 10 的所有值,那么您可以使用类似“[1..10]”的东西。类似地,如果您想生成从“a”到“z”的所有字母,那么您只需键入“[a..z]”。
以下代码展示了如何使用序列运算符打印从 1 到 10 的所有值:
main :: IO() main = do print [1..10]
它将生成以下输出:
[1,2,3,4,5,6,7,8,9,10]
Haskell - 决策
决策机制允许程序员在代码流程中应用条件。程序员可以根据预定义的条件执行一组指令。以下流程图显示了 Haskell 的决策机制结构:
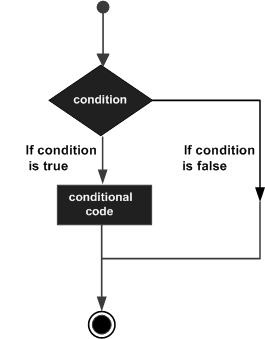
Haskell 提供以下类型的决策语句:
| 序号 | 语句及描述 |
|---|---|
| 1 | if-else 语句
一个if 语句和一个else 语句。只有当给定的布尔条件不满足时,else 块中的指令才会执行。 |
| 2 | 嵌套 if-else 语句
多个if 块后跟else 块 |
Haskell - 类型和类型类
Haskell 是一种函数式语言,它是强类型语言,这意味着整个应用程序中使用的数据类型在编译时将为编译器所知。
内置类型类
在 Haskell 中,每个语句都被视为一个数学表达式,此表达式的类别称为类型。您可以说“类型”是在编译时使用的表达式的数 据类型。
为了更多地了解类型,我们将使用“:t”命令。一般来说,类型可以被认为是一个值,而类型类可以被认为是一组类似的类型。在本章中,我们将学习不同的内置类型。
Int
Int 是表示整数类型数据的类型类。从 -2147483647 到 2147483647 之间的每个整数都属于Int 类型类。在下面的例子中,函数fType() 将根据其定义的类型进行操作。
fType :: Int -> Int -> Int fType x y = x*x + y*y main = print (fType 2 4)
在这里,我们将函数fType() 的类型设置为int。该函数接受两个int 值并返回一个int 值。如果您编译并执行这段代码,它将产生以下输出:
sh-4.3$ ghc -O2 --make *.hs -o main -threaded -rtsopts sh-4.3$ main 20
Integer
Integer 可以被认为是Int 的超集。此值不受任何数字限制,因此 Integer 可以是任意长度,没有任何限制。为了了解Int 和Integer 类型之间的基本区别,让我们修改上面的代码如下:
fType :: Int -> Int -> Int fType x y = x*x + y*y main = print (fType 212124454 44545454454554545445454544545)
如果您编译上面的代码,将抛出以下错误消息:
main.hs:3:31: Warning: Literal 44545454454554545445454544545 is out of the Int range - 9223372036854775808..9223372036854775807 Linking main ...
发生此错误是因为我们的函数 fType() 期望一个 Int 类型值,而我们正在传递一些非常大的 Int 类型值。为了避免此错误,让我们将类型“Int”修改为“Integer”并观察差异。
fType :: Integer -> Integer -> Integer fType x y = x*x + y*y main = print (fType 212124454 4454545445455454545445445454544545)
现在,它将产生以下输出:
sh-4.3$ main 1984297512562793395882644631364297686099210302577374055141
Float
请看下面的代码。它展示了 Float 类型在 Haskell 中是如何工作的:
fType :: Float -> Float -> Float fType x y = x*x + y*y main = print (fType 2.5 3.8)
该函数将两个浮点值作为输入,并产生另一个浮点值作为输出。当您编译并执行此代码时,它将产生以下输出:
sh-4.3$ main 20.689999
Double
Double 是一个浮点数,最后具有双精度。请看下面的例子:
fType :: Double -> Double -> Double fType x y = x*x + y*y main = print (fType 2.56 3.81)
当您执行上面的代码时,它将生成以下输出:
sh-4.3$ main 21.0697
Bool
Bool 是布尔类型。它可以是 True 或 False。执行以下代码以了解 Bool 类型在 Haskell 中是如何工作的:
main = do
let x = True
if x == False
then putStrLn "X matches with Bool Type"
else putStrLn "X is not a Bool Type"
在这里,我们将变量“x”定义为 Bool,并将其与另一个布尔值进行比较以检查其真伪。它将产生以下输出:
sh-4.3$ main X is not a Bool Type
Char
Char 表示字符。单引号内的任何内容都被视为字符。在下面的代码中,我们修改了之前的fType() 函数,使其接受 Char 值并返回 Char 值作为输出。
fType :: Char-> Char fType x = 'K' main = do let x = 'v' print (fType x)
上面的代码将使用 'v' 的char 值调用fType() 函数,但它返回另一个 char 值,即 'K'。这是它的输出:
sh-4.3$ main 'K'
请注意,我们不会显式地使用这些类型,因为 Haskell 足够智能,可以在声明之前捕获类型。在本教程的后续章节中,我们将看到不同的类型和类型类是如何使 Haskell 成为一种强类型语言的。
EQ 类型类
EQ 类型类是一个接口,它提供测试表达式相等性的功能。任何想要检查表达式相等性的类型类都应该属于此 EQ 类型类。
上面提到的所有标准类型类都是此EQ 类的一部分。每当我们使用上面提到的任何类型检查任何相等性时,实际上我们都在调用EQ 类型类。
在下面的例子中,我们使用“==”或“/=”运算内部使用EQ 类型。
main = do
if 8 /= 8
then putStrLn "The values are Equal"
else putStrLn "The values are not Equal"
它将产生以下输出:
sh-4.3$ main The values are not Equal
Ord 类型类
Ord 是另一个接口类,它为我们提供了排序的功能。到目前为止我们使用过的所有类型都是此Ord 接口的一部分。像 EQ 接口一样,Ord 接口可以使用“>”、“<”、“<=”、“>=”、“compare”来调用。
请参见下面的示例,我们使用了此类型类的“compare”功能。
main = print (4 <= 2)
在这里,Haskell 编译器将检查 4 是否小于或等于 2。由于它不是,代码将产生以下输出:
sh-4.3$ main False
Show
Show 的功能是将其参数打印为字符串。无论其参数是什么,它总是将结果打印为字符串。在下面的示例中,我们将使用此接口打印整个列表。“show”可用于调用此接口。
main = print (show [1..10])
它将在控制台上产生以下输出。这里,双引号表示它是一个字符串类型的值。
sh-4.3$ main "[1,2,3,4,5,6,7,8,9,10]"
Read
Read 接口与 Show 做相同的事情,但它不会以字符串格式打印结果。在下面的代码中,我们使用了read 接口来读取字符串值并将相同的值转换为 Int 值。
main = print (readInt "12") readInt :: String -> Int readInt = read
在这里,我们将字符串变量(“12”)传递给readInt 方法,该方法在转换后返回 12(一个 Int 值)。这是它的输出:
sh-4.3$ main 12
Enum
Enum 是另一种类型的类型类,它在 Haskell 中启用顺序功能。此类型类可以通过Succ、Pred、Bool、Char 等命令访问。
以下代码展示了如何查找 12 的后继值。
main = print (succ 12)
它将产生以下输出:
sh-4.3$ main 13
Bounded
所有具有上限和下限的类型都属于此类型类。例如,Int 类型数据具有“9223372036854775807”的最大边界和“-9223372036854775808”的最小边界。
以下代码展示了 Haskell 如何确定 Int 类型的最大和最小边界。
main = do print (maxBound :: Int) print (minBound :: Int)
它将产生以下输出:
sh-4.3$ main 9223372036854775807 -9223372036854775808
现在,尝试查找 Char、Float 和 Bool 类型的最大和最小边界。
Num
此类型类用于数值运算。Int、Integer、Float 和 Double 等类型属于此类型类。请看下面的代码:
main = do print(2 :: Int) print(2 :: Float)
它将产生以下输出:
sh-4.3$ main 2 2.0
Integral
Integral 可以被认为是 Num 类型类的子类。Num 类型类包含所有类型的数字,而 Integral 类型类仅用于整数。Int 和 Integer 是此类型类下的类型。
Floating
与 Integral 一样,Floating 也是 Num 类型类的一部分,但它只包含浮点数。因此,Float 和Double 属于此类型类。
自定义类型类
像任何其他编程语言一样,Haskell 允许开发人员定义用户定义的类型。在下面的示例中,我们将创建一个用户定义的类型并使用它。
data Area = Circle Float Float Float surface :: Area -> Float surface (Circle _ _ r) = pi * r ^ 2 main = print (surface $ Circle 10 20 10 )
这里,我们创建了一个名为Area的新类型。接下来,我们将使用此类型来计算圆的面积。在上面的示例中,“surface”是一个函数,它以Area作为输入,并产生Float作为输出。
请记住,“data”在这里是一个关键字,所有 Haskell 中的用户定义类型都以大写字母开头。
它将产生以下输出:
sh-4.3$ main 314.15927
Haskell - 函数
函数在 Haskell 中扮演着重要角色,因为它是一种函数式编程语言。与其他语言一样,Haskell 也有自己的函数定义和声明。
函数声明包括函数名及其参数列表以及其输出。
函数定义是在你实际定义函数的地方。
让我们以add函数为例,详细了解这个概念。
add :: Integer -> Integer -> Integer --function declaration add x y = x + y --function definition main = do putStrLn "The addition of the two numbers is:" print(add 2 5) --calling a function
在这里,我们在第一行声明了我们的函数,在第二行,我们编写了实际的函数,它将接受两个参数并产生一个整型输出。
与大多数其他语言一样,Haskell 从main方法开始编译代码。我们的代码将生成以下输出:
The addition of the two numbers is: 7
模式匹配
模式匹配是匹配特定类型表达式的过程。它只是一种简化代码的技术。这种技术可以实现到任何类型的类型类中。可以使用 If-Else 作为模式匹配的替代选项。
模式匹配可以被认为是动态多态性的一种变体,在运行时,可以根据参数列表执行不同的方法。
请看下面的代码块。在这里,我们使用了模式匹配技术来计算一个数的阶乘。
fact :: Int -> Int fact 0 = 1 fact n = n * fact ( n - 1 ) main = do putStrLn "The factorial of 5 is:" print (fact 5)
我们都知道如何计算一个数的阶乘。编译器将开始搜索一个名为“fact”且带有一个参数的函数。如果参数不等于 0,则该数字将继续调用具有比实际参数少 1 的相同函数。
当参数的模式与 0 完全匹配时,它将调用我们的模式“fact 0 = 1”。我们的代码将产生以下输出:
The factorial of 5 is: 120
守卫(Guards)
守卫是一个与模式匹配非常相似的概念。在模式匹配中,我们通常匹配一个或多个表达式,但我们使用守卫来测试表达式的某些属性。
虽然建议使用模式匹配而不是守卫,但从开发者的角度来看,守卫更易读且更简单。对于第一次使用的用户来说,守卫可能看起来与 If-Else 语句非常相似,但它们在功能上是不同的。
在下面的代码中,我们使用守卫的概念修改了我们的阶乘程序。
fact :: Integer -> Integer
fact n | n == 0 = 1
| n /= 0 = n * fact (n-1)
main = do
putStrLn "The factorial of 5 is:"
print (fact 5)
在这里,我们声明了两个守卫,用 "|" 分隔,并从main调用fact函数。在内部,编译器的工作方式与模式匹配的情况相同,以产生以下输出:
The factorial of 5 is: 120
Where 子句
Where是一个关键字或内置函数,可以在运行时使用以生成所需的输出。当函数计算变得复杂时,它非常有用。
考虑这样一种情况:你的输入是一个包含多个参数的复杂表达式。在这种情况下,可以使用“where”子句将整个表达式分解成小的部分。
在下面的示例中,我们采用了一个复杂的数学表达式。我们将展示如何使用 Haskell 求解多项式方程 [x^2 - 8x + 6] 的根。
roots :: (Float, Float, Float) -> (Float, Float) roots (a,b,c) = (x1, x2) where x1 = e + sqrt d / (2 * a) x2 = e - sqrt d / (2 * a) d = b * b - 4 * a * c e = - b / (2 * a) main = do putStrLn "The roots of our Polynomial equation are:" print (roots(1,-8,6))
注意我们计算给定多项式函数的根的表达式的复杂性。它相当复杂。因此,我们使用where子句来分解表达式。上面的代码将生成以下输出:
The roots of our Polynomial equation are: (7.1622777,0.8377223)
递归函数
递归是一种函数反复调用自身的情况。Haskell 并没有提供任何循环任何表达式超过一次的机制。相反,Haskell 希望你将你的整个功能分解成一系列不同的函数,并使用递归技术来实现你的功能。
让我们再次考虑我们的模式匹配示例,其中我们计算了一个数的阶乘。寻找一个数的阶乘是使用递归的经典案例。在这里,你可能会问:“模式匹配与递归有什么不同?”这两者之间的区别在于它们的使用方式。模式匹配用于设置终端约束,而递归是一个函数调用。
在下面的示例中,我们同时使用了模式匹配和递归来计算 5 的阶乘。
fact :: Int -> Int fact 0 = 1 fact n = n * fact ( n - 1 ) main = do putStrLn "The factorial of 5 is:" print (fact 5)
它将产生以下输出:
The factorial of 5 is: 120
高阶函数
到目前为止,我们看到的是 Haskell 函数将一个类型作为输入,并产生另一个类型作为输出,这与其他命令式语言非常相似。高阶函数是 Haskell 的一个独特特性,你可以在其中使用函数作为输入或输出参数。
虽然这是一个虚拟概念,但在实际程序中,我们在 Haskell 中定义的每个函数都使用高阶机制来提供输出。如果你有机会查看 Haskell 的库函数,你会发现大多数库函数都是以高阶方式编写的。
让我们举一个例子,我们将导入一个内置的高阶函数 map 并使用它来根据我们的选择实现另一个高阶函数。
import Data.Char import Prelude hiding (map) map :: (a -> b) -> [a] -> [b] map _ [] = [] map func (x : abc) = func x : map func abc main = print $ map toUpper "tutorialspoint.com"
在上面的示例中,我们使用了Char类型类的toUpper函数将我们的输入转换为大写。在这里,“map”方法将一个函数作为参数,并返回所需的输出。这是它的输出:
sh-4.3$ ghc -O2 --make *.hs -o main -threaded -rtsopts sh-4.3$ main "TUTORIALSPOINT.COM"
Lambda 表达式
有时我们必须编写一个函数,该函数在应用程序的整个生命周期中只会被使用一次。为了处理这种情况,Haskell 开发人员使用另一个称为lambda 表达式或lambda 函数的匿名块。
没有定义的函数称为 lambda 函数。lambda 函数用 "\" 字符表示。让我们看下面的例子,我们将输入值增加 1,而无需创建任何函数。
main = do putStrLn "The successor of 4 is:" print ((\x -> x + 1) 4)
在这里,我们创建了一个没有名称的匿名函数。它以整数 4 作为参数并打印输出值。我们基本上是在操作一个函数,甚至没有正确声明它。这就是 lambda 表达式的魅力。
我们的 lambda 表达式将产生以下输出:
sh-4.3$ main The successor of 4 is: 5
Haskell - 函数详解
到目前为止,我们已经讨论了许多类型的 Haskell 函数,并使用了不同的方法来调用这些函数。在本章中,我们将学习一些基本的函数,这些函数可以很容易地在 Haskell 中使用,而无需导入任何特殊的类型类。大多数这些函数都是其他高阶函数的一部分。
Head 函数
Head函数作用于列表。它返回输入参数的第一个元素,该参数基本上是一个列表。在下面的示例中,我们传递一个包含 10 个值的列表,并且我们使用head函数生成该列表的第一个元素。
main = do let x = [1..10] putStrLn "Our list is:" print (x) putStrLn "The first element of the list is:" print (head x)
它将产生以下输出:
Our list is: [1,2,3,4,5,6,7,8,9,10] The first element of the list is: 1
Tail 函数
Tail是补充head函数的函数。它以列表作为输入,并产生整个列表,但不包括头部部分。这意味着tail函数返回整个列表,但不包括第一个元素。请看下面的示例:
main = do let x = [1..10] putStrLn "Our list is:" print (x) putStrLn "The tail of our list is:" print (tail x)
它将产生以下输出:
Our list is: [1,2,3,4,5,6,7,8,9,10] The tail of our list is: [2,3,4,5,6,7,8,9,10]
Last 函数
顾名思义,它产生作为输入提供的列表的最后一个元素。查看下面的示例。
main = do let x = [1..10] putStrLn "Our list is:" print (x) putStrLn "The last element of our list is:" print (last x)
它将产生以下输出:
Our list is: [1,2,3,4,5,6,7,8,9,10] The last element of our list is: 10
Init 函数
Init的作用与tail函数恰好相反。它以列表作为参数,并返回整个列表,但不包括最后一个条目。
main = do let x = [1..10] putStrLn "Our list is:" print (x) putStrLn "Our list without the last entry:" print (init x)
现在,观察它的输出:
Our list is: [1,2,3,4,5,6,7,8,9,10] Our list without the last entry: [1,2,3,4,5,6,7,8,9]
Null 函数
Null是一个布尔检查函数,它作用于字符串,只有当给定的列表为空时才返回True,否则返回False。下面的代码检查提供的列表是否为空。
main = do let x = [1..10] putStrLn "Our list is:" print (x) putStrLn "Is our list empty?" print (null x)
它将产生以下输出:
Our list is: [1,2,3,4,5,6,7,8,9,10] Is our list empty? False
Reverse 函数
它作用于字符串输入,并将整个输入转换为反向顺序,并给出一个输出作为结果。以下是此函数的代码库。
main = do let x = [1..10] putStrLn "Our list is:" print (x) putStrLn "The list in Reverse Order is:" print (reverse x)
它将产生以下输出:
Our list is: [1,2,3,4,5,6,7,8,9,10] The list in Reverse Order is: [10,9,8,7,6,5,4,3,2,1]
Length 函数
此函数用于计算作为参数给定的列表的长度。请看下面的示例:
main = do let x = [1..10] putStrLn "Our list is:" print (x) putStrLn "The length of this list is:" print (length x)
我们的列表中有 10 个元素,因此我们的代码将产生 10 作为输出。
Our list is: [1,2,3,4,5,6,7,8,9,10] The length of this list is: 10
Take 函数
Take函数用于从另一个字符串创建子字符串。下面的代码展示了如何在 Haskell 中使用 take 函数:
main = print(take 5 ([1 .. 10]))
该代码从提供的列表中生成一个包含 5 个元素的子字符串:
[1,2,3,4,5]
Drop 函数
此函数也用于生成子字符串。它的功能与take函数相反。查看下面的代码:
main = print(drop 5 ([1 .. 10]))
该代码从提供的列表中删除前 5 个元素,并打印其余 5 个元素。它将产生以下输出:
[6,7,8,9,10]
Maximum 函数
此函数用于从提供的列表中查找具有最大值的元素。让我们看看如何在实践中使用它:
main = do let x = [1,45,565,1245,02,2] putStrLn "The maximum value element of the list is:" print (maximum x)
上面的代码将生成以下输出:
The maximum value element of the list is: 1245
Minimum 函数
此函数用于从提供的列表中查找具有最小值的元素。它只是maximum函数的反义词。
main = do let x = [1,45,565,1245,02,2] putStrLn "The minimum value element of the list is:" print (minimum x)
上面代码的输出是:
The minimum value element of the list is: 1
Sum 函数
顾名思义,此函数返回提供的列表中所有元素的总和。下面的代码接受一个包含 5 个元素的列表,并将其总和作为输出返回。
main = do let x = [1..5] putStrLn "Our list is:" print (x) putStrLn "The summation of the list elements is:" print (sum x)
它将产生以下输出:
Our list is: [1,2,3,4,5] The summation of the list elements is: 15
Product 函数
您可以使用此函数将列表中的所有元素相乘并打印其值。
main = do let x = [1..5] putStrLn "Our list is:" print (x) putStrLn "The multiplication of the list elements is:" print (product x)
我们的代码将产生以下输出:
Our list is: [1,2,3,4,5] The multiplication of the list elements is: 120
Elem 函数
此函数用于检查提供的列表是否包含特定元素。相应地,它返回true或false。
下面的代码检查提供的元素列表是否包含值 786。
main = do let x = [1,45,155,1785] putStrLn "Our list is:" print (x) putStrLn "Does it contain 786?" print (elem 786 (x))
它将产生以下输出:
Our list is: [1,45,155,1785] Does it contain 786? False
使用相同的代码检查提供的列表是否包含值 1785。
Haskell - 函数组合
函数组合是将一个函数的输出用作另一个函数的输入的过程。如果我们学习组合背后的数学原理会更好。在数学中,组合用f{g(x)}表示,其中g()是一个函数,其输出用作另一个函数的输入,即f()。
函数组合可以使用任何两个函数实现,前提是其中一个函数的输出类型与第二个函数的输入类型匹配。我们在 Haskell 中使用点运算符 (.) 来实现函数组合。
请看下面的示例代码。在这里,我们使用了函数组合来计算输入数字是偶数还是奇数。
eveno :: Int -> Bool noto :: Bool -> String eveno x = if x `rem` 2 == 0 then True else False noto x = if x == True then "This is an even Number" else "This is an ODD number" main = do putStrLn "Example of Haskell Function composition" print ((noto.eveno)(16))
在这里,在主函数中,我们同时调用了两个函数,noto 和 eveno。编译器将首先调用函数"eveno()",参数为16。此后,编译器将使用eveno方法的输出作为noto()方法的输入。
其输出如下所示:
Example of Haskell Function composition "This is an even Number"
由于我们提供的是数字 16 作为输入(这是一个偶数),eveno()函数返回true,这成为noto()函数的输入并返回输出:“这是一个偶数”。
Haskell - 模块
如果您使用过 Java,那么您就会知道所有类是如何绑定到名为package的文件夹中的。类似地,Haskell 可以被认为是模块的集合。
Haskell 是一种函数式语言,所有内容都表示为表达式,因此模块可以称为类似或相关类型函数的集合。
您可以从一个模块导入一个函数到另一个模块。所有“import”语句都应该在您开始定义其他函数之前出现。在本章中,我们将学习 Haskell 模块的不同特性。
List 模块
List 提供了一些用于处理列表类型数据的出色函数。导入 List 模块后,您可以使用各种各样的函数。
在下面的示例中,我们使用了一些 List 模块中提供的重要的函数。
import Data.List
main = do
putStrLn("Different methods of List Module")
print(intersperse '.' "Tutorialspoint.com")
print(intercalate " " ["Lets","Start","with","Haskell"])
print(splitAt 7 "HaskellTutorial")
print (sort [8,5,3,2,1,6,4,2])
这里,我们有很多函数,甚至没有定义它们。这是因为这些函数在 List 模块中可用。导入 List 模块后,Haskell 编译器使所有这些函数在全局命名空间中可用。因此,我们可以使用这些函数。
我们的代码将产生以下输出:
Different methods of List Module
"T.u.t.o.r.i.a.l.s.p.o.i.n.t...c.o.m"
"Lets Start with Haskell"
("Haskell","Tutorial")
[1,2,2,3,4,5,6,8]
Char 模块
Char 模块有很多预定义函数可用于处理字符类型。请查看以下代码块:
import Data.Char
main = do
putStrLn("Different methods of Char Module")
print(toUpper 'a')
print(words "Let us study tonight")
print(toLower 'A')
这里,函数toUpper 和 toLower 已经在Char 模块中定义。它将产生以下输出:
Different methods of Char Module 'A' ["Let","us","study","tonight"] 'a'
Map 模块
Map 是一种未排序的增值对类型数据类型。它是一个广泛使用的模块,具有许多有用的函数。以下示例显示了如何使用 Map 模块中提供的预定义函数。
import Data.Map (Map) import qualified Data.Map as Map --required for GHCI myMap :: Integer -> Map Integer [Integer] myMap n = Map.fromList (map makePair [1..n]) where makePair x = (x, [x]) main = print(myMap 3)
它将产生以下输出:
fromList [(1,[1]),(2,[2]),(3,[3])]
Set 模块
Set 模块有一些非常有用的预定义函数来操作数学数据。集合实现为二叉树,因此集合中的所有元素都必须唯一。
请查看以下示例代码
import qualified Data.Set as Set
text1 = "Hey buddy"
text2 = "This tutorial is for Haskell"
main = do
let set1 = Set.fromList text1
set2 = Set.fromList text2
print(set1)
print(set2)
这里,我们将字符串修改为集合。它将产生以下输出。注意,输出集合中没有字符重复。
fromList " Hbdeuy" fromList " HTaefhiklorstu"
自定义模块
让我们看看如何创建一个可以在其他程序中调用的自定义模块。要实现这个自定义模块,我们将创建一个名为"custom.hs" 的单独文件以及我们的"main.hs"。
让我们创建自定义模块并在其中定义一些函数。
custom.hs
module Custom ( showEven, showBoolean ) where showEven:: Int-> Bool showEven x = do if x 'rem' 2 == 0 then True else False showBoolean :: Bool->Int showBoolean c = do if c == True then 1 else 0
我们的自定义模块已准备就绪。现在,让我们将其导入程序。
main.hs
import Custom main = do print(showEven 4) print(showBoolean True)
我们的代码将生成以下输出:
True 1
showEven 函数返回True,因为“4”是一个偶数。showBoolean 函数返回“1”,因为我们传递给函数的布尔函数是“True”。
Haskell - 输入与输出
到目前为止,我们讨论的所有示例本质上都是静态的。在本章中,我们将学习如何与用户动态通信。我们将学习 Haskell 中使用的不同输入和输出技术。
文件和流
到目前为止,我们已经在程序本身中对所有输入进行了硬编码。我们一直在从静态变量获取输入。现在,让我们学习如何从外部文件读取和写入。
让我们创建一个文件并将其命名为“abc.txt”。接下来,在此文本文件中输入以下几行:“欢迎来到 Tutorialspoint。在这里,您将获得学习 Haskell 的最佳资源。”
接下来,我们将编写以下代码,该代码将在控制台上显示此文件的内容。这里,我们使用函数 readFile(),它读取文件直到找到 EOF 字符。
main = do let file = "abc.txt" contents <- readFile file putStrLn contents
上面的代码段将读取“abc.txt”文件作为一个字符串,直到遇到任何文件结尾字符。这段代码将生成以下输出。
Welcome to Tutorialspoint Here, you will get the best resource to learn Haskell.
注意,它在终端上打印的内容都写入该文件中。
命令行参数
Haskell 还提供了通过命令提示符操作文件的工具。让我们回到终端并键入“ghci”。然后,键入以下命令集:
let file = "abc.txt" writeFile file "I am just experimenting here." readFile file
这里,我们创建了一个名为“abc.txt”的文本文件。接下来,我们使用命令writeFile在文件中插入了一个语句。最后,我们使用命令readFile在控制台上打印文件的内容。我们的代码将产生以下输出:
I am just experimenting here.
异常
异常可以被认为是代码中的错误。在这种情况下,编译器在运行时无法获得预期的输出。与任何其他良好的编程语言一样,Haskell 提供了一种实现异常处理的方法。
如果您熟悉 Java,那么您可能知道 Try-Catch 块,我们通常在其中抛出错误并在catch块中捕获相同的错误。在 Haskell 中,我们也有相同的函数来捕获运行时错误。
try 的函数定义如下所示:“try :: Exception e => IO a -> IO (Either e a)” 请查看以下示例代码。它显示了如何捕获“除以零”异常。
import Control.Exception
main = do
result <- try (evaluate (5 `div` 0)) :: IO (Either SomeException Int)
case result of
Left ex -> putStrLn $ "Caught exception: " ++ show ex
Right val -> putStrLn $ "The answer was: " ++ show val
在上面的示例中,我们使用了Control.Exception模块的内置try函数,因此我们提前捕获了异常。上面的代码段将在屏幕上产生以下输出。
Caught exception: divide by zero
Haskell - Functor (函子)
Haskell 中的Functor是一种对不同类型进行映射的函数式表示。它是实现多态性的高级概念。根据 Haskell 开发人员的说法,所有类型,例如 List、Map、Tree 等,都是 Haskell Functor 的实例。
Functor是一个内置类,其函数定义如下:
class Functor f where fmap :: (a -> b) -> f a -> f b
根据此定义,我们可以得出结论,Functor是一个函数,它接受一个函数,例如fmap(),并返回另一个函数。在上面的示例中,fmap()是函数map()的广义表示。
在下面的示例中,我们将看到 Haskell Functor 的工作方式。
main = do print(map (subtract 1) [2,4,8,16]) print(fmap (subtract 1) [2,4,8,16])
在这里,我们对列表使用了map()和fmap()进行减法运算。您可以观察到这两个语句都将产生相同的包含元素 [1,3,7,15] 的列表结果。
这两个函数都调用了另一个名为subtract()的函数来产生结果。
[1,3,7,15] [1,3,7,15]
那么,map和fmap有什么区别呢?区别在于它们的用法。Functor使我们能够在不同的数据类型中实现更多函数式方法,例如“just”和“Nothing”。
main = do print (fmap (+7)(Just 10)) print (fmap (+7) Nothing)
上面的代码段将在终端上产生以下输出:
Just 17 Nothing
Applicative Functor
Applicative Functor 是一个普通的 Functor,具有 Applicative 类型类提供的额外功能。
使用 Functor,我们通常将现有的函数与其中定义的另一个函数映射。但是,没有办法将 Functor 内部定义的函数与另一个 Functor 映射。这就是为什么我们有另一个名为Applicative Functor的功能。此映射功能由Control模块下定义的 Applicative 类型类实现。此类只给我们提供两种方法:一种是pure,另一种是<*>。
以下是 Applicative Functor 的类定义。
class (Functor f) => Applicative f where pure :: a -> f a (<*>) :: f (a -> b) -> f a -> f b
根据实现,我们可以使用两种方法映射另一个 Functor:“Pure”和“<*>”。“Pure”方法应该接受任何类型的值,它将始终返回该值的 Applicative Functor。
以下示例显示了 Applicative Functor 的工作方式:
import Control.Applicative f1:: Int -> Int -> Int f1 x y = 2*x+y main = do print(show $ f1 <$> (Just 1) <*> (Just 2) )
在这里,我们在函数f1的函数调用中实现了应用函子。我们的程序将产生以下输出。
"Just 4"
Monoid
我们都知道 Haskell 将所有内容定义为函数的形式。在函数中,我们可以选择将输入作为函数的输出。这就是Monoid。
Monoid是一组函数和运算符,其中输出与其输入无关。让我们以函数 (*) 和整数 (1) 为例。现在,无论输入是什么,其输出都将保持相同的数字。也就是说,如果将一个数字乘以 1,您将得到相同的数字。
这是一个 monoid 的类型类定义。
class Monoid m where mempty :: m mappend :: m -> m -> m mconcat :: [m] -> m mconcat = foldr mappend mempty
请查看以下示例以了解 Monoid 在 Haskell 中的用法。
multi:: Int->Int multi x = x * 1 add :: Int->Int add x = x + 0 main = do print(multi 9) print (add 7)
我们的代码将产生以下输出:
9 7
这里,函数“multi”将输入乘以“1”。类似地,函数“add”将输入与“0”相加。在这两种情况下,输出都将与输入相同。因此,函数{(*),1}和{(+),0}是 monoid 的完美示例。
Haskell - Monad (单子)
Monad只不过是一种具有额外功能的 Applicative Functor。它是一个类型类,它遵循三个称为monadic 规则的基本规则。
所有这三个规则都严格适用于 Monad 声明,如下所示:
class Monad m where return :: a -> m a (>>=) :: m a -> (a -> m b) -> m b (>>) :: m a -> m b -> m b x >> y = x >>= \_ -> y fail :: String -> m a fail msg = error msg
适用于 Monad 声明的三个基本定律是:
左恒等律 - return函数不会更改值,并且它不应该更改 Monad 中的任何内容。它可以表示为“return >>= mf = mf”。
右恒等律 - return函数不会更改值,并且它不应该更改 Monad 中的任何内容。它可以表示为“mf >>= return = mf”。
结合律 - 根据此定律,Functor 和 Monad 实例应该以相同的方式工作。它可以用数学表达式表示为“(f >>= g) >>= h = f >>= (g >>= h)”。
前两个定律迭代相同的点,即return应该在bind运算符的两侧具有恒等行为。
在我们之前的示例中,我们已经使用了许多 Monad,而没有意识到它们是 Monad。考虑以下示例,我们使用 List Monad 来生成特定列表。
main = do print([1..10] >>= (\x -> if odd x then [x*2] else []))
此代码将产生以下输出:
[2,6,10,14,18]
Haskell - Zipper (拉链)
Haskell 中的Zipper基本上是指向数据结构(例如树)的特定位置的指针。
让我们考虑一个具有 5 个元素[45,7,55,120,56]的树,它可以表示为一个完美的二叉树。如果我想更新此列表的最后一个元素,那么我需要遍历所有元素才能到达最后一个元素才能更新它,对吧?
但是,如果我们可以以这样的方式构建我们的树,即具有N个元素的树是[(N-1),N]的集合。然后,我们不需要遍历所有不需要的(N-1)个元素。我们可以直接更新第 N 个元素。这正是 Zipper 的概念。它专注于或指向树的特定位置,我们可以在其中更新该值而无需遍历整棵树。
在下面的示例中,我们在列表中实现了 Zipper 的概念。同样,可以在树或文件数据结构中实现 Zipper。
data List a = Empty | Cons a (List a) deriving (Show, Read, Eq, Ord) type Zipper_List a = ([a],[a]) go_Forward :: Zipper_List a -> Zipper_List a go_Forward (x:xs, bs) = (xs, x:bs) go_Back :: Zipper_List a -> Zipper_List a go_Back (xs, b:bs) = (b:xs, bs) main = do let list_Ex = [1,2,3,4] print(go_Forward (list_Ex,[])) print(go_Back([4],[3,2,1]))
编译并执行上述程序时,它将产生以下输出:
([2,3,4],[1]) ([3,4],[2,1])
这里我们关注的是整个字符串中的一个元素,无论是向前还是向后。