- HBase 教程
- HBase - 首页
- HBase - 概述
- HBase - 架构
- HBase - 安装
- HBase - Shell
- HBase - 常用命令
- HBase - 管理员 API
- HBase - 创建表
- HBase - 列出表
- HBase - 禁用表
- HBase - 启用表
- HBase - 描述和修改
- HBase - 检查表是否存在
- HBase - 删除表
- HBase - 关闭
- HBase - 客户端 API
- HBase - 创建数据
- HBase - 更新数据
- HBase - 读取数据
- HBase - 删除数据
- HBase - 扫描
- HBase - 计数和截断
- HBase - 安全性
- HBase 资源
- HBase - 问答
- HBase - 快速指南
- HBase - 有用资源
HBase - 概述
自 1970 年以来,关系型数据库管理系统 (RDBMS) 一直是解决数据存储和维护相关问题的方案。在大数据出现后,企业意识到处理大数据的益处,并开始选择 Hadoop 等解决方案。
Hadoop 使用分布式文件系统来存储大数据,并使用 MapReduce 来处理它。Hadoop 擅长存储和处理各种格式的海量数据,例如任意格式、半结构化甚至非结构化数据。
Hadoop 的局限性
Hadoop 只能执行批处理,并且只能以顺序方式访问数据。这意味着即使是最简单的任务,也必须搜索整个数据集。
当处理海量数据集时,会产生另一个海量数据集,该数据集也需要按顺序进行处理。此时,需要一个新的解决方案来在单个时间单位内访问数据的任意点(随机访问)。
Hadoop 随机访问数据库
HBase、Cassandra、CouchDB、Dynamo 和 MongoDB 等应用程序是一些存储海量数据并以随机方式访问数据的数据库。
什么是 HBase?
HBase 是一个构建在 Hadoop 文件系统之上的分布式列式数据库。它是一个开源项目,并且具有水平可扩展性。
HBase 是一种类似于 Google 的 Bigtable 的数据模型,旨在提供对海量结构化数据的快速随机访问。它利用了 Hadoop 文件系统 (HDFS) 提供的容错能力。
它是 Hadoop 生态系统的一部分,它提供对 Hadoop 文件系统中数据的随机实时读写访问。
可以将数据直接存储在 HDFS 中,也可以通过 HBase 存储。数据消费者使用 HBase 以随机方式读取/访问 HDFS 中的数据。HBase 位于 Hadoop 文件系统之上,并提供读写访问。
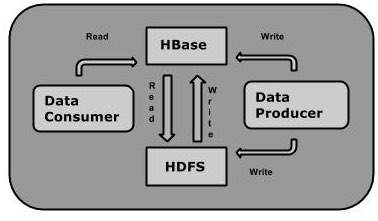
HBase 和 HDFS
| HDFS | HBase |
|---|---|
| HDFS 是一种适合存储大型文件的分布式文件系统。 | HBase 是一个构建在 HDFS 之上的数据库。 |
| HDFS 不支持快速单个记录查找。 | HBase 为更大的表提供快速查找。 |
| 它提供高延迟批处理;没有批处理的概念。 | 它提供对数十亿条记录中的单个行的低延迟访问(随机访问)。 |
| 它仅提供数据的顺序访问。 | HBase 内部使用哈希表并提供随机访问,它将数据存储在索引的 HDFS 文件中以加快查找速度。 |
HBase 中的存储机制
HBase 是一个**列式数据库**,其中的表按行排序。表模式仅定义列族,它们是键值对。一个表可以有多个列族,每个列族可以有任意数量的列。后续列值连续存储在磁盘上。表的每个单元格值都有一个时间戳。简而言之,在 HBase 中
- 表是行的集合。
- 行是列族的集合。
- 列族是列的集合。
- 列是键值对的集合。
以下是 HBase 中表的示例模式。
| 行 ID | 列族 | 列族 | 列族 | 列族 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | col1 | col2 | col3 | |
| 1 | ||||||||||||
| 2 | ||||||||||||
| 3 | ||||||||||||
列式和行式
列式数据库是指将数据表存储为数据列的部分,而不是数据行的部分。简而言之,它们将具有列族。
| 行式数据库 | 列式数据库 |
|---|---|
| 它适用于联机事务处理 (OLTP)。 | 它适用于联机分析处理 (OLAP)。 |
| 此类数据库设计用于少量行和列。 | 列式数据库设计用于大型表。 |
下图显示了列式数据库中的列族
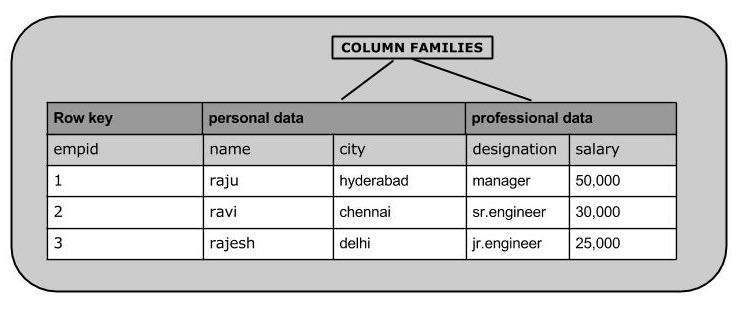
HBase 和 RDBMS
| HBase | RDBMS |
|---|---|
| HBase 是无模式的,它没有固定列模式的概念;仅定义列族。 | RDBMS 受其模式的约束,模式描述了表的整个结构。 |
| 它构建用于宽表。HBase 具有水平可扩展性。 | 它很薄,并且构建用于小型表。难以扩展。 |
| HBase 中没有事务。 | RDBMS 是事务型的。 |
| 它具有非规范化数据。 | 它将具有规范化数据。 |
| 它适用于半结构化数据和结构化数据。 | 它适用于结构化数据。 |
HBase 的特性
- HBase 具有线性可扩展性。
- 它具有自动故障支持。
- 它提供一致的读写。
- 它与 Hadoop 集成,既作为源也作为目标。
- 它具有易于使用的 Java API 供客户端使用。
- 它提供跨集群的数据复制。
在哪里使用 HBase
Apache HBase 用于对大数据进行随机、实时的读写访问。
它在商品硬件集群之上托管超大型表。
Apache HBase 是一个非关系型数据库,其模型参考了 Google 的 Bigtable。Bigtable 在 Google 文件系统上运行,类似地,Apache HBase 在 Hadoop 和 HDFS 之上运行。
HBase 的应用
- 当需要编写重量级应用程序时使用它。
- 当我们需要为可用数据提供快速的随机访问时使用 HBase。
- Facebook、Twitter、Yahoo 和 Adobe 等公司在内部使用 HBase。
HBase 历史
| 年份 | 事件 |
|---|---|
| 2006 年 11 月 | Google 发布了关于 Bigtable 的论文。 |
| 2007 年 2 月 | 创建了最初的 HBase 原型作为 Hadoop 的贡献。 |
| 2007 年 10 月 | 发布了第一个可用的 HBase 以及 Hadoop 0.15.0。 |
| 2008 年 1 月 | HBase 成为 Hadoop 的子项目。 |
| 2008 年 10 月 | 发布了 HBase 0.18.1。 |
| 2009 年 1 月 | 发布了 HBase 0.19.0。 |
| 2009 年 9 月 | 发布了 HBase 0.20.0。 |
| 2010 年 5 月 | HBase 成为 Apache 的顶级项目。 |