
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 语言编程
C 语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP在 Pandas(Python)中突出显示最后两列的最大值
在处理数据时,识别并突出显示 Pandas 数据框中特定列中的最大值通常至关重要。在 Python 中,Pandas 库广泛用于数据操作,并提供高效的内置函数。
本文重点介绍如何突出显示 Pandas 数据框最后两列中的最大值。通过使用不同的方法,我们可以快速找到并强调数据框中的最高值,这将有助于更容易地分析和理解数据集。
如何在 Pandas 中突出显示最后两列中的最大值?
为了突出显示 Pandas 数据框最后两列中的最大值,我们可以在 Python 中使用不同的方法。下面是使用代码示例解释的两种方法:
方法 1:使用 Pandas 数据框的 style 属性
一种突出显示 Pandas 数据框最后两列中的最大值的方法是利用 style 属性。通过访问数据框的 style 属性,我们可以应用 highlight_max 函数,并将子集指定为最后两列。此函数会自动识别每列中的最大值并将其突出显示。生成的样式化数据框以视觉方式强调最高值,便于更容易地分析和理解数据。
示例
import pandas as pd
# Create a sample dataframe
data = {'Column1': [10, 15, 8],
'Column2': [20, 5, 12],
'Column3': [7, 18, 9]}
df = pd.DataFrame(data)
# Highlight the maximum values in the last two columns
df_styled = df.style.highlight_max(subset=df.columns[-2:])
# Display the styled dataframe
df_styled
输出

此方法利用了 Pandas 数据框的 style 属性,特别是 highlight_max 函数。通过将子集参数传递为 df.columns[-2:],我们指定了数据框的最后两列。此函数突出显示每列中的最大值,使其在视觉上与众不同。
方法 2:使用条件格式化
突出显示 Pandas 数据框最后两列中的最大值的另一种方法是条件格式化。我们定义一个自定义函数 highlight_max,该函数将序列中的每个元素与该序列的最大值进行比较。该函数返回一个样式指令列表,指示最大值为黄色背景。通过使用 apply 方法应用此函数并将子集指定为最后两列,我们可以实现条件格式化,突出显示最高值,从而帮助进行数据分析和理解。
示例
import pandas as pd
# Create a sample dataframe
data = {'Column1': [10, 15, 8],
'Column2': [20, 5, 12],
'Column3': [7, 18, 9]}
df = pd.DataFrame(data)
# Define a function to highlight the maximum value
def highlight_max(s):
is_max = s == s.max()
return ['background-color: pink' if v else '' for v in is_max]
# Apply the function to the last two columns
df_styled = df.style.apply(highlight_max, subset=df.columns[-2:])
# Display the styled dataframe
df_styled
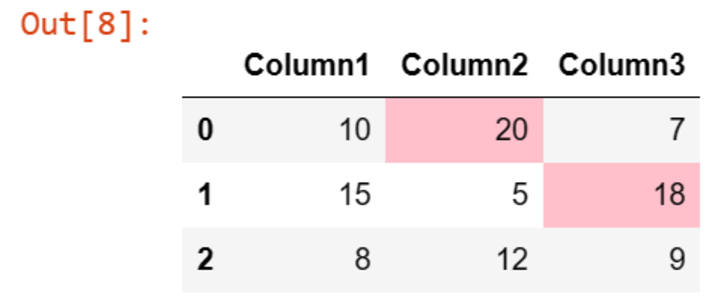
在这种方法中,我们定义了一个名为 highlight_max 的自定义函数,该函数将序列 (s) 中的每个元素与该序列的最大值进行比较。该函数返回一个样式指令列表,其中最大值以黄色背景突出显示。通过使用 apply 函数并将子集指定为 df.columns[-2:],我们将条件格式化仅应用于最后两列。
这些方法提供了不同的方法来突出显示 Pandas 数据框最后两列中的最大值。选择适合您需求和编码风格的方法。
结论
总之,突出显示 Pandas 数据框最后两列中的最大值是理解和分析数据的一种有益方法。使用style属性或条件格式化等技术,我们可以将注意力集中在最突出的数据点上。
因此,我们可以快速识别和审查数据集中关键的数据元素。无论是通过自定义格式化还是内置函数,这些方法都提供了有效的方法来强调最大值,从而有助于深入理解数据并促进数据驱动的决策过程。

613 次浏览
