- Hive 教程
- Hive - 首页
- Hive - 简介
- Hive - 安装
- Hive - 数据类型
- Hive - 创建数据库
- Hive - 删除数据库
- Hive - 创建表
- Hive - 修改表
- Hive - 删除表
- Hive - 分区
- Hive - 内置运算符
- Hive - 内置函数
- Hive - 视图和索引
- HiveQL
- HiveQL - Select Where
- HiveQL - Select Order By
- HiveQL - Select Group By
- HiveQL - Select Joins
- Hive 有用资源
- Hive - 常见问题解答
- Hive - 快速指南
- Hive - 有用资源
Hive - 简介
术语“大数据”用于指代包含海量数据、高速数据以及日益增长的各种类型数据的大型数据集集合。使用传统的数据管理系统很难处理大数据。因此,Apache 软件基金会引入了一个名为 Hadoop 的框架来解决大数据管理和处理的挑战。
Hadoop
Hadoop 是一个开源框架,用于在分布式环境中存储和处理大数据。它包含两个模块,一个是 MapReduce,另一个是 Hadoop 分布式文件系统 (HDFS)。
MapReduce:它是一种并行编程模型,用于在大型商用硬件集群上处理大量结构化、半结构化和非结构化数据。
HDFS:Hadoop 分布式文件系统是 Hadoop 框架的一部分,用于存储和处理数据集。它提供了一个容错文件系统,可在商用硬件上运行。
Hadoop 生态系统包含不同的子项目(工具),例如 Sqoop、Pig 和 Hive,这些工具用于辅助 Hadoop 模块。
Sqoop:它用于在 HDFS 和 RDBMS 之间导入和导出数据。
Pig:它是一个过程语言平台,用于开发 MapReduce 操作的脚本。
Hive:它是一个平台,用于开发 SQL 类型脚本以执行 MapReduce 操作。
注意:执行 MapReduce 操作有多种方法
- 使用 Java MapReduce 程序处理结构化、半结构化和非结构化数据的传统方法。
- 使用 Pig 处理结构化和半结构化数据的 MapReduce 脚本方法。
- 使用 Hive 处理结构化数据的 MapReduce 的 Hive 查询语言 (HiveQL 或 HQL) 方法。
什么是 Hive
Hive 是一个数据仓库基础设施工具,用于处理 Hadoop 中的结构化数据。它位于 Hadoop 之上,用于汇总大数据,并简化查询和分析。
Hive 最初由 Facebook 开发,后来 Apache 软件基金会将其接手,并在 Apache Hive 的名称下将其进一步开发为开源项目。它被不同的公司使用。例如,亚马逊将其用于 Amazon Elastic MapReduce。
Hive 不是
- 关系数据库
- 在线事务处理 (OLTP) 设计
- 用于实时查询和行级更新的语言
Hive 的特性
- 它将模式存储在数据库中,并将处理后的数据存储到 HDFS 中。
- 它专为 OLAP 设计。
- 它提供了一种名为 HiveQL 或 HQL 的 SQL 类型查询语言。
- 它熟悉、快速、可扩展且可扩展。
Hive 的架构
下图显示了 Hive 的架构图
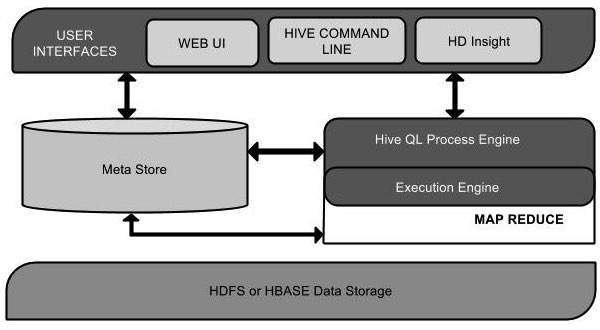
此架构图包含不同的单元。下表描述了每个单元
| 单元名称 | 操作 |
|---|---|
| 用户界面 | Hive 是一个数据仓库基础设施软件,可以创建用户和 HDFS 之间的交互。Hive 支持的用户界面包括 Hive Web UI、Hive 命令行和 Hive HD Insight(在 Windows 服务器中)。 |
| 元存储 | Hive 选择相应的数据库服务器来存储表的模式或元数据、数据库、表中的列、它们的数据类型以及 HDFS 映射。 |
| HiveQL 处理引擎 | HiveQL 类似于 SQL,用于查询元存储上的模式信息。它是传统 MapReduce 程序方法的替代方法之一。无需用 Java 编写 MapReduce 程序,我们可以编写 MapReduce 作业的查询并对其进行处理。 |
| 执行引擎 | HiveQL 处理引擎和 MapReduce 的结合部分是 Hive 执行引擎。执行引擎处理查询并生成与 MapReduce 结果相同的的结果。它使用 MapReduce 的风格。 |
| HDFS 或 HBASE | Hadoop 分布式文件系统或 HBASE 是将数据存储到文件系统中的数据存储技术。 |
Hive 的工作原理
下图显示了 Hive 和 Hadoop 之间的流程。
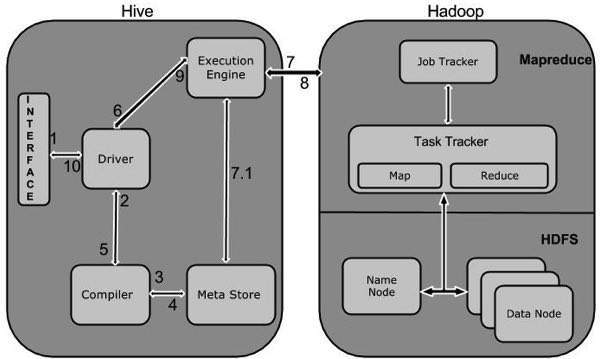
下表定义了 Hive 如何与 Hadoop 框架交互
| 步骤号 | 操作 |
|---|---|
| 1 | 执行查询
Hive 接口(例如命令行或 Web UI)将查询发送到驱动程序(任何数据库驱动程序,例如 JDBC、ODBC 等)以执行。 |
| 2 | 获取计划
驱动程序借助查询编译器来解析查询,以检查语法和查询计划或查询的需求。 |
| 3 | 获取元数据
编译器将元数据请求发送到元存储(任何数据库)。 |
| 4 | 发送元数据
元存储将元数据作为响应发送回编译器。 |
| 5 | 发送计划
编译器检查需求并将计划重新发送到驱动程序。到这里,查询的解析和编译就完成了。 |
| 6 | 执行计划
驱动程序将执行计划发送到执行引擎。 |
| 7 | 执行作业
在内部,执行作业的过程是一个 MapReduce 作业。执行引擎将作业发送到 JobTracker(位于 Name 节点),它将此作业分配给 TaskTracker(位于 Data 节点)。在这里,查询执行 MapReduce 作业。 |
| 7.1 | 元数据操作
同时在执行过程中,执行引擎可以与元存储执行元数据操作。 |
| 8 | 获取结果
执行引擎从 Data 节点接收结果。 |
| 9 | 发送结果
执行引擎将这些结果值发送到驱动程序。 |
| 10 | 发送结果
驱动程序将结果发送到 Hive 接口。 |