
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何构建具有可靠验证分数的机器学习模型
机器学习 (ML) 是一门引人入胜的领域,它让计算机能够从数据中学习并做出决策,而无需明确编程。如果您刚开始学习,它可能看起来有点复杂,但别担心!本文将介绍创建有效运行且最重要的是具有稳定验证分数的机器学习模型的基础知识。在本教程结束时,您将全面了解创建成功的机器学习模型中涉及的术语、关键概念和过程。
介绍
假设您正在构建一个能够预测天气的机器人。您希望它尽可能准确,对吧?为此,您需要测试它预测天气的准确性。这里就用到了验证分数。它们帮助我们评估机器学习算法的预测准确性。本文将解释机器学习,解释验证的重要性,并解释如何确保您的模型可靠。
什么是机器学习?
机器学习 是一种人工智能 (AI),其中计算机从数据中学习。与其为可能出现的每种情况创建全面的指令,不如让机器自己解决问题。例如,如果您想让计算机识别猫的图像,您不会对猫的每个特征进行编码。相反,您会向计算机提供数百张标记为“猫”或“非猫”的图像,随着时间的推移,设备将学会自己识别猫。
关键术语
在我们继续之前,让我们定义一些关键词
- 模型: 模型是对现实世界过程的数学表示。机器学习使用数据进行预测。
- 训练数据: 用于训练模型的信息称为训练数据。它类似于我们训练狗狗的过程。
- 验证数据: 这是用于检查模型学习效果的单独数据。这就像在新的环境中测试狗狗。
- 验证分数: 此分数告诉我们模型在验证数据上的表现如何。高分表示模型擅长进行预测。
为什么验证很重要?
当您训练模型时,它可能在训练数据上表现得非常好,但在面对新数据时却失败了。验证有助于确保您的模型不仅仅是记住训练数据,而是在学习能够帮助它在新数据上表现良好的模式。这对于构建可靠的模型至关重要。验证分数就像机器学习模型的成绩单。它们让您知道模型预测新数据的准确性如何。分数越高,模型做出准确预测的能力就越高。
为什么验证分数很重要?
验证分数很重要,因为它们帮助我们:
- 避免过拟合: 过拟合是指模型从训练集中学习了过多的信息,以至于无法将这些信息应用于新数据。
- 比较不同的模型: 可以使用验证分数比较不同的模型,从而选择最佳模型。
- 识别问题: 低验证分数可能表明数据或模型存在问题。
构建机器学习模型的步骤
- 收集数据
- 准备数据
- 选择模型
- 训练模型
- 测试模型
- 调整模型
- 评估模型
示例数据集:鸢尾花数据集
步骤 1:加载数据集
首先,我们需要将数据集加载到我们的环境中。
import pandas as pd # Load the Iris dataset url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data" columns = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species'] iris = pd.read_csv(url, header=None, names=columns) # Display the first few rows of the dataset print(iris.head())
步骤 2:可视化数据集
在构建模型之前,可视化数据有助于更好地理解数据。我们将为此使用 matplotlib 和 seaborn 库。
import matplotlib.pyplot as plt import seaborn as sns # Visualize the pairwise relationships in the dataset sns.pairplot(iris, hue='species') plt.show()
步骤 3:分割数据集
为了评估模型的性能,我们需要将数据集分割成训练集、验证集和测试集。
from sklearn.model_selection import train_test_split
# Split the dataset
X = iris.drop('species', axis=1)
y = iris['species']
X_train, X_temp, y_train, y_temp = train_test_split(X, y, test_size=0.3, random_state=42)
X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
步骤 4:构建和训练模型
我们将使用简单的决策树分类器,它易于理解和实现。
from sklearn.tree import DecisionTreeClassifier # Initialize the model model = DecisionTreeClassifier(random_state=42) # Train the model model.fit(X_train, y_train)
步骤 5:验证模型
现在,我们将检查模型在验证集上的表现。
from sklearn.metrics import accuracy_score
# Make predictions on the validation set
y_val_pred = model.predict(X_val)
# Calculate the accuracy score
val_score = accuracy_score(y_val, y_val_pred)
print(f"Validation Accuracy: {val_score:.2f}")
步骤 6:测试模型
最后,我们将评估测试集上的模型,看看它在现实世界中的表现如何。
# Make predictions on the test set
y_test_pred = model.predict(X_test)
# Calculate the test accuracy
test_score = accuracy_score(y_test, y_test_pred)
print(f"Test Accuracy: {test_score:.2f}")
步骤 7:可视化决策树
可视化决策树可以帮助您理解模型如何做出决策。
from sklearn import tree # Plot the decision tree plt.figure(figsize=(12,8)) tree.plot_tree(model, feature_names=columns[:-1], class_names=iris['species'].unique(), filled=True) plt.show()
输出
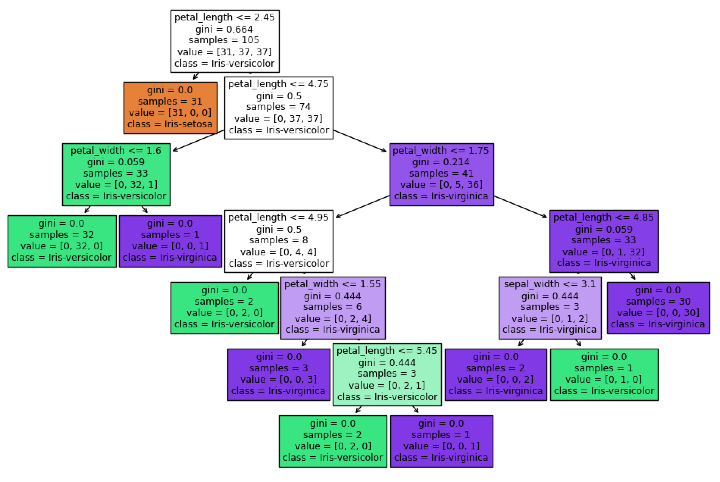
通过检查此决策树的图形表示,您可以更好地理解决策过程,该图形说明了模型在每个阶段如何划分输入。
构建可靠模型的技巧
以下建议可以帮助您创建可靠的机器学习模型
- 使用大型且多样化的数据集: 更大的数据集将提高模型的泛化性能。
- 特征工程: 创建信息量更大的新特征。
- 正则化: 此技术有助于防止过拟合。
- 交叉验证: 此技术有助于更准确地评估模型的性能。
结论
加载和可视化数据,将其分成训练集、验证集和测试集,训练模型,验证模型以及测试模型是构建机器学习模型的许多步骤。最终目标是确保您的模型在新数据上有效运行,您可以通过仔细遵循这些步骤来实现。您可以使用此代码构建和评估您自己的机器学习模型,而鸢尾花数据集是学习这些概念的好起点。
浏览量:32
