
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何设计端到端推荐引擎
推荐引擎是一种有效的利用机器学习算法为消费者提供个性化建议的方法,这些建议基于他们的过往行为、偏好和其他标准。这些引擎被广泛应用于各个行业,包括电子商务、医疗保健和娱乐,并已被证明能够通过提高用户参与度和收入为组织带来价值。设计端到端推荐引擎涉及多个过程,包括数据收集和预处理、特征工程、模型训练和评估、部署和监控。通过遵循此过程,企业可以生成准确且相关的建议,从而增强用户体验并促进商业成功。在这篇博文中,我们将探讨如何从头到尾设计一个推荐引擎,从数据收集和预处理到模型训练和评估。
设计端到端推荐系统
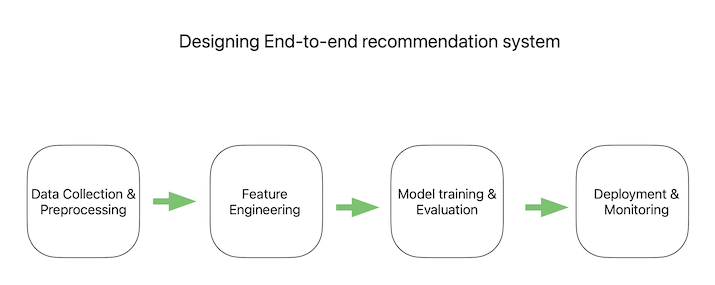
数据收集和预处理
数据收集是构建强大推荐引擎的关键步骤。收集与用户行为和偏好相关且能够反映模型准确性的相关数据至关重要。这些数据可以从各种来源收集,例如用户交互、人口统计信息和项目特征。
一旦数据收集完成,预处理数据对于确保数据质量以供模型使用至关重要。一些预处理技术包括删除重复项、处理缺失值和识别异常值。此外,可以根据数据类型应用数据转换技术,例如缩放、标准化或对分类变量进行编码。此外,预处理完成后,数据通常会被划分为训练集和测试集。训练集用于训练推荐引擎,而测试集用于评估模型的性能。
特征工程
特征工程是选择和转换数据特征以提高推荐引擎性能的过程。目标是以一种允许模型有效学习的方式来描述用户偏好和项目属性。作为特征工程的一部分,选定的相关特征会被预处理并转换为模型可以理解的表示形式。
一种常见的特征工程技术称为协同过滤,它利用用户-项目交互数据来识别相似的用户并根据用户的兴趣向用户推荐产品。相反,基于内容的过滤侧重于项目特征,以推荐与用户先前喜欢的产品相似的产品。矩阵分解是另一种技术,它利用线性代数将交互矩阵分解为用户和项目的潜在因素,然后根据潜在空间中彼此相似的项目推荐产品。测试和评估不同的特征组合对于选择最适合模型的数据格式至关重要。
模型训练与评估
模型训练和评估是推荐引擎构建中至关重要的过程。它包括选择模型架构、使用预处理和特征工程后的数据训练模型,以及使用各种指标评估模型的性能。
选择正确的模型架构对于推荐引擎的成功至关重要。一些常见的模型架构包括决策树、深度神经网络和支持向量机。将根据业务的具体需求和使用的数据类型来选择特定的架构。
在选择模型架构后,下一步是使用预处理和特征工程后的数据训练模型。在训练过程中,通过向模型提供输入数据和输出标签来调整模型的参数,以减少预期输出和实际输出之间的误差。最后,使用多种指标评估模型的性能,包括准确率、召回率和 F1 分数。
部署与监控
一旦推荐引擎构建、测试和训练完成,它就可以部署了。部署到生产环境并开始向用户提供个性化建议之前,需要将模型集成到现有系统中,例如网站、应用程序或其他平台。部署过程可能包括设置一个推荐 API,该 API 可以与系统交互以提供实时建议。
为了确保推荐引擎继续为用户提供准确且相关的建议,持续监控其性能并进行必要的调整至关重要。监控包括通过衡量各种指标(例如点击率、转化率和其他用户参与度数据)来实时评估模型的性能。监控还可能包括跟踪用户行为、偏好或其他可能影响建议的因素的变化。这些数据可用于更新特征工程技术或调整模型的输入参数,以保持建议的准确性和相关性。
结论
总之,有效的推荐引擎可以为企业带来巨大价值,并提高用户参与度、客户忠诚度和收入。通过在相关数据上进行有效训练、使用有效的特征工程技术构建以及通过实时监控进行部署,一个推荐引擎可以提供个性化和相关的建议,从而改善用户体验。

131 次浏览
