
 数据结构
数据结构 网络
网络 关系型数据库管理系统 (RDBMS)
关系型数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何使用Python获取每日新闻?
每日新闻指的是每天发布的、关注全球事件和主题的新闻。每日新闻的使命是让读者了解并及时掌握世界各地的事件。政治、体育、娱乐、科学和技术只是每日新闻涵盖的众多领域中的一小部分。
Python编程语言在数据分析和Web开发领域都有广泛的应用。它可以用来创建一个程序,从多个来源收集新闻文章,并将它们编译成每日新闻摘要。可以使用Python包,如Requests和Beautiful Soup来实现此功能。
注意 − 由于每日新闻不断更新,输出可能会有所变化
使用Python获取每日新闻的算法
以下是使用Python获取每日新闻的一些算法方法。
步骤1 − 确定可靠的新闻来源 查找提供各种主题信息(例如政治、体育、娱乐、科学和技术)的可信新闻网站。这可能包括著名的新闻机构,如CNN、BBC和《纽约时报》,以及更专业、规模较小的期刊,这些期刊专注于特定地区或问题。
步骤2 − 设置你的Python环境 在第二步中,你必须在你的计算机上设置一个Python环境,以便使用Python来抓取新闻文章。安装任何必要的库的最新版本,包括Beautiful Soup和Requests,以及Python。
步骤3 − 编写代码来抓取新闻文章 编写Python代码,使用Requests库向你已识别的新闻来源网站发出HTTP请求。使用Beautiful Soup解析HTML内容并提取相关信息,例如标题、文章文本、作者和发布时间。将此信息存储在数据库或数据文件中,以及原始文章的URL。
步骤4 − 检查文章的文本。对每篇文章的文本分析应用自然语言处理工具,以查找可能表明剽窃或改写的模式或相似之处。可以使用像NLTK(自然语言工具包)这样的工具将每篇文章的文本与其他抓取的文章进行比较。任何似乎是重复使用或剽窃的文章都应从每日新闻摘要中排除。
步骤5 − 制作每日新闻摘要。将抓取的新闻文章汇编成每日新闻摘要,其中应包含全球事件和主题。为了确保摘要公平和有帮助,请包含各种主题和观点。
步骤6 − 公开每日新闻摘要。将每日新闻摘要发布到网上或社交媒体平台上。Beautiful Soup (bs4)是一个用于从HTML和XML文件中提取数据的Python包。Python默认不包含此模块。在终端输入以下命令进行安装。以便任何人都可以访问它。包含对源文章的引用,以便读者可以访问更多细节和上下文。
你可以按照以下步骤使用Python获取每日新闻。
所需的模块
安装Beautiful Soup(bs4)的命令
bs4 − Beautiful Soup(bs4) 是一个用于从HTML和XML文件中提取数据的Python库。此模块并非Python内置。要安装它,请在终端中输入以下命令。
pip install bs4
安装Request的命令
Requests − Request 使发送HTTP/1.1请求变得非常简单。此外,Python默认不包含此模块。在终端输入以下命令进行安装。
pip install requests
使用Python获取每日新闻的方法
方法1
在这种方法中,我们首先导入模块 −
import requests from bs4 import BeautifulSoup
之后,为了轻松获取任何特定新闻的每日新闻,我们将添加 https://www.bbc.com/news的HTML内容,添加这两行代码 −
url='https://www.bbc.com/news' response = requests.get(url)
访问 https://www.bbc.com/news,并通过右键单击新闻标题并选择“检查”来检查新闻标题,以查找构成新闻标题的HTML标签 −
首先,我们将“soup”定义为BBC新闻网站的HTML。下一步是将“headlines”定义为网站上所有“
”标签的数组。最后,使用“text.strip()”方法去除每个元素的outerHTML,只显示其文本内容,脚本迭代地遍历“headlines”数组并依次显示每个项目。
第一种方法的代码实现
import requests
from bs4 import BeautifulSoup
url = 'https://www.bbc.com/news'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
headlines = soup.find('body').find_all('h3')
for x in headlines:
print(x.text.strip())
第一种方法的输出
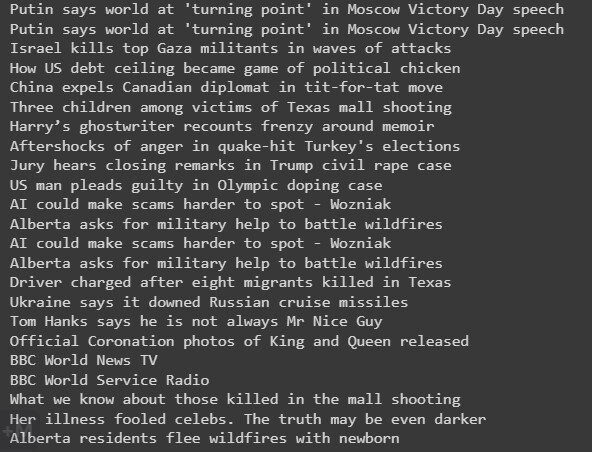
方法2
你可能已经看到你的输出包含重复的新闻标题和不是新闻标题的文本内容,在这种方法中,我们将从每日新闻数据中删除不需要的数据。
语法
unwanted = ['BBC World News TV', 'BBC World Service Radio', 'News daily newsletter', 'Mobile app', 'Get in touch']
然后,通过添加以下内容,仅在文本元素不在此列表中时打印文本元素:
第二种方法的代码实现
import requests
from bs4 import BeautifulSoup
url = 'https://www.bbc.com/news'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
headlines = soup.find('body').find_all('h3')
unwanted = ['BBC World News TV', 'BBC World Service Radio', 'News daily newsletter', 'Mobile app', 'Get in touch']
for x in headlines:
headline_text = x.text.strip()
if headline_text not in unwanted:
print(headline_text)
第二种方法的输出
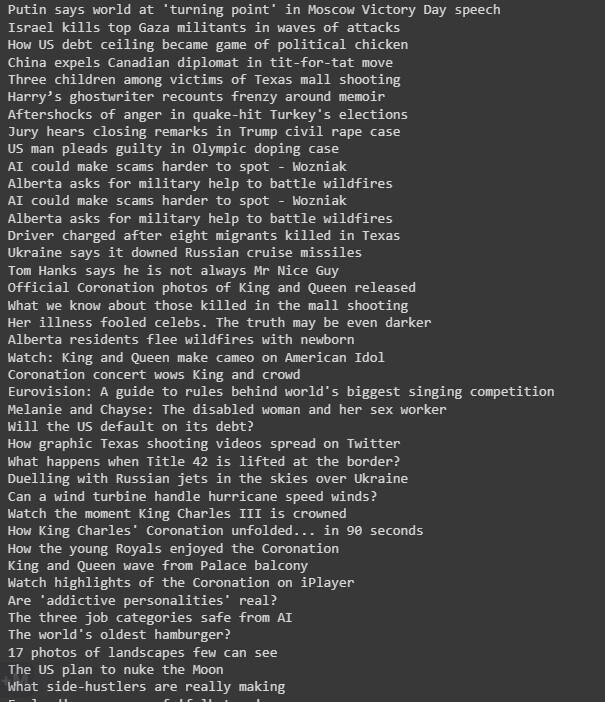
结论
Python程序员可以使用网络抓取方法和新闻机构的API来获取当天的新闻。但是,网络抓取必须符合所抓取网站的条款和条件,并且不应向其服务器发出过多的查询。使用网络抓取技术从网站收集新闻文章是另一种方法。开发人员可以使用Python的BeautifulSoup包解析HTML和XML文档来实现这一点。但是,务必注意网站的条款和条件,并避免过度占用其系统。

686 次浏览
