
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C语言编程
C语言编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP如何在计算机体系结构中消除负载使用延迟?
处理器的流水线布局会影响负载使用延迟。下图显示了传统的 RISC、MIPS 和 CISC 流水线布局以及相关的负载使用延迟。


对于传统的四阶段 RISC 流水线,首先,在 D 阶段访问寄存器以获取地址计算的组成部分,例如指定基址或索引寄存器的内容。接下来,在 E 阶段,使用 FX 加法器计算有效(虚拟)地址。在本周期结束时,虚拟地址可以发送到 MMU 和/或缓存。假设使用高性能缓存,数据将在下一个流水线周期结束时可用,从而导致一个周期的负载延迟。
对于传统的 MIPS 流水线,虚拟地址再次在 E 阶段结束时发出。再次假设单周期缓存延迟,请求的数据将在 C 周期结束时从缓存到达。因此,传统的 MIPS 流水线也具有一个周期的负载使用延迟。
另一方面,传统的 CISC 流水线设计用于处理寄存器-内存指令。因此,它的布局使得即使在同一指令的 E 阶段也可以使用引用的内存数据,如下图所示。
因此,布局根本不会导致负载使用延迟。但是,由于流水线阶段数量较多,因此并行执行的指令更多,因此与四阶段或五阶段流水线相比,可以预期出现更多相关的指令。这一事实可能会不利地影响性能。
它可以假设一个高性能缓存,能够在一个周期内访问数据,包括地址转换和假设缓存命中。对于较慢的缓存,如果未采取任何特殊措施,则负载使用延迟会更长。接下来,我们将展示减少较慢缓存负载使用延迟的技术。通过将地址计算过程提前半个或整个流水线周期来匹配较慢的缓存到流水线布局中,如下图所示。

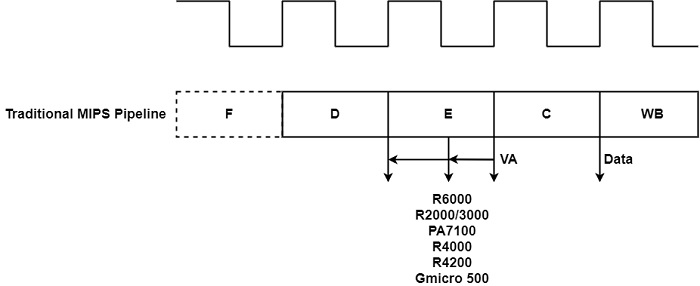
例如,在 R2000 和 R3000 处理器中,地址计算发生在 E 周期的前半部分。高性能 HP 7100 也同样适用。该处理器是独特的,因为它使用片外缓存,这解释了需要转发地址计算子任务的原因。
一些处理器,例如 Am 29000 或 R6000,甚至将地址计算移到解码 (D) 阶段的最后阶段。

263 次查看
