
 数据结构
数据结构 网络
网络 关系型数据库管理系统
关系型数据库管理系统 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP计算机体系结构中加载/存储指令的流水线执行是什么?
加载和存储是频繁的操作,尤其是在 RISC 代码中。在执行 RISC 代码时,我们可以预期会遇到大约 25%-35% 的加载指令和大约 10% 的存储指令。因此,有效地执行加载和存储指令具有重要意义。
它可以总结在加载或存储指令期间必须执行的子任务,如图形所示。
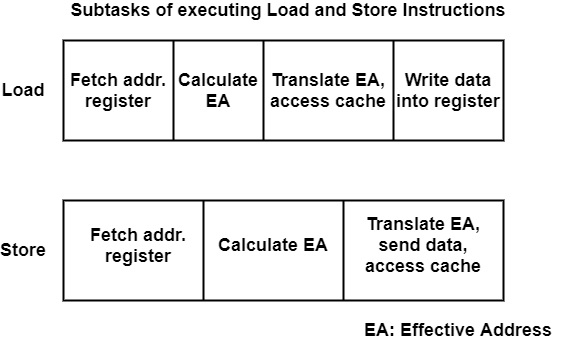
让我们首先考虑一个加载指令。它的执行始于确定要从中提取数据的有效内存地址 (EA)。在这种情况下,像 RISC 处理器一样,这可以通过两个步骤完成:获取引用的地址寄存器并计算有效地址。
在 CISC 处理器中,地址计算可能是一项困难的任务,需要多个后续寄存器获取和地址计算,例如索引、后增量、相对地址。一旦有效地址可用,下一步通常是将有效(虚拟)地址转发到 MMU 进行转换并访问数据缓存。
在传统的流水线实现中,加载和存储指令由主流水线处理。这些加载和存储与其他指令按顺序执行,如图形所示。

在这种情况下,加载/存储指令所需的地址计算可以由执行阶段的加法器执行。但是,每个加载或存储指令都需要一个指令时隙。
这种低成本实现方法的代表是 MIPS R4000、Pentium(具有两个整数单元)、PowerPC 601、Power2 和 DEC α 21164(也具有两个整数单元)。乍一看,令人惊讶的是,当前面的 α 21064 和 α 21064A 提供了一个专用的自主加载/存储单元时,α 21164 使用了顺序加载/存储处理技术。
加载/存储指令处理的一种更有效的地址技术是与数据操作并行执行,如图形所示。这种方法假设存在一个可以自行执行地址计算的自主加载/存储单元。
越来越多的超标量处理器实现了自主加载/存储单元。早期设计的示例包括 i80960 CA 或 MC 88110。最近的示例包括 DEC α 21064、DEC α 21064A、PowerPC 603、PowerPC 604、PowerPC 620 和 MIPS R8000。
自主加载/存储单元可以与其他指令的处理同步运行,也可以解耦运行。在同步运行中,对内存(缓存)的加载和存储请求按顺序发出。或者,可以将加载和存储的执行与其他指令的执行解耦以提高性能。这可以通过为挂起的加载和存储提供队列并从队列中执行这些操作来实现。

1K+ 浏览量
