
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用交叉验证技术提高模型准确率
介绍
交叉验证 (CV) 是一种训练机器学习模型的方法,其中多个模型在数据的一部分上进行训练,然后评估其性能或在独立的未见数据集中进行测试。在交叉验证技术中,我们通常迭代地将原始训练数据分成不同的部分,以便算法在数据的每个部分上进行训练和验证,在这个过程中没有一个部分被遗漏。
在本文中,让我们深入了解交叉验证技术及其在提高模型准确性方面的重要性。
交叉验证 (CV)
交叉验证是在许多情况下提高准确性的首选技术,但当数据有限时它非常有用。它通过使用数据采样的轮换方案并使用这些部分来训练多个模型并选择最佳模型,从而防止模型过拟合。原始数据被随机采样并分成不同的数据集。然后,模型在所有子集上进行测试,留下一个用于评估模型性能或简单测试的子集。在某些情况下,我们可以进行多轮交叉验证,并取最终结果的平均值。
交叉验证的重要性是什么?
交叉验证在提高模型准确性方面非常重要。当数据集较小时,这一事实通常很明显。例如,让我们考虑预测地震的概率。对于这种情况,我们需要诸如纬度、经度、发生日期、深度、深度误差、位置源、震级源、震级类型等数据。为了确定地震发生的概率,我们需要训练模型并对其进行测试。由于数据集很小,如果所有数据都用于训练,模型将学习所有变化甚至噪声并过拟合。将没有数据剩余用于测试模型性能。在实际场景中,我们在使用预测模型时可能会遇到未见数据的变化,因此在这种情况下它可能无法很好地执行。
解决此问题的方法是使用交叉验证,这是一种将数据集划分为多个子集的随机重采样技术,这些子集通常称为 k 折交叉验证,其中 k 表示子集的数量,例如 5、10 等。在交叉验证中,模型在除一个子集之外的所有子集上进行训练,该子集用于测试。测试集是完全未见的数据,可用于正确评估模型。
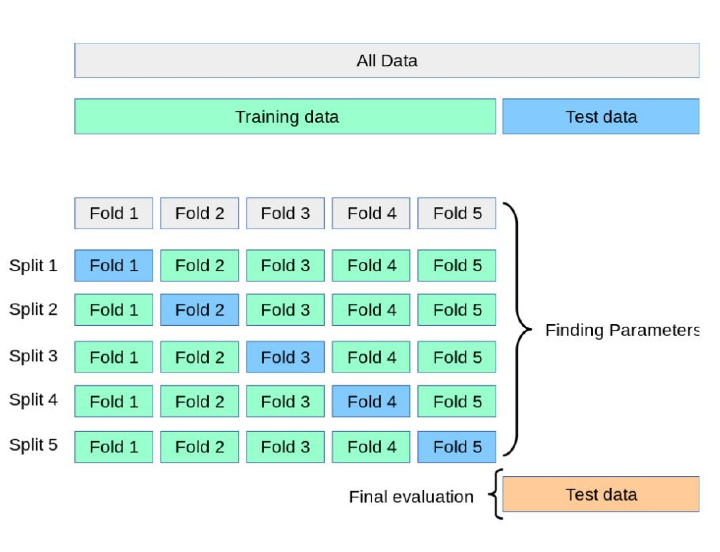
交叉验证的类型
它们分为两种类型——穷举和非穷举。在穷举策略中,所有技术都应用于通过应用所有组合将数据集划分为训练和测试子集。但是,在非穷举中,不使用创新的方法来拆分数据集。
留出法
在这种类型的交叉验证中,初始数据集仅分成两部分——训练子集和测试子集。模型在训练集上进行训练并在测试集上进行评估。这是一种非穷举方法。例如,数据集可以按 70:30 或 75:25 等比例拆分。这里,每次训练时结果可能会有所不同,因为数据点的组合会有所不同。这种方法通常用于数据集很大或存在时间限制以快速训练模型并尽快获得结果时。
K 折交叉验证
与留出法相比,这是一种更好的方法,因为它是对留出法的重大改进。它是非穷举的,并且不依赖于数据集如何拆分为训练和测试子集。K 折交叉验证中的 K 表示数据集的折数或分区数,例如 5 折、10 折等。
在 K 折交叉验证中,模型在所有 K-1 个数据集上进行训练,并在第 k 个数据集上测试性能。此过程持续进行,直到每个折数至少用作验证集一次。在 K 折迭代后,模型取模型结果的平均值。
K 折模型有助于减少偏差并提高准确性,因为每个数据集都有机会充当训练集和测试集。但是,K 折交叉验证的过程可能有点耗时。
分层 K 折交叉验证
在 K 折交叉验证中,我们可能会遇到问题,因为该方法随机抽样数据并进行混洗和拆分,并且数据集可能会变得不平衡。让我们用一个例子来理解它。
例如,假设我们必须将电子邮件分类为垃圾邮件和非垃圾邮件。在 K 折交叉验证中,可能会发生在一个折数中,我们可能会获得更多垃圾邮件类别的电子邮件,而对非垃圾邮件的表示较少,这可能会产生有偏差的评估结果。
为了解决此问题,使用了名为分层的方法,其中确保每个拆分或子集都具有相同数量的两个类别(或在多类分类的情况下为 N 个类别)。这是分层 K 折背后的理念。
交叉验证技术的实现
from sklearn import datasets
from sklearn.model_selection import KFold, cross_val_score
from sklearn.tree import DecisionTreeClassifier as DTC
x_train, y_train = datasets.load_iris(return_X_y=True)
model = DTC(random_state=1)
foldsK = KFold(n_splits = 10)
s = cross_val_score(model, x_train, y_train, cv = foldsK)
print("Scores CV", s)
print("Avg CV score: ", s.mean())
print("No of CV scores used in Avg: ", len(s))
输出
Scores CV [1. 1. 1. 0.93333333 0.93333333 0.86666667 1. 0.86666667 0.86666667 1. ] Avg CV score: 0.9466666666666667 No of CV scores used in Avg: 10
结论
交叉验证是一种用于训练机器学习模型的高效且流行的技术。它极大地提升了模型的整体性能和准确性,就像它如何有效地拆分和使用数据集一样。在每个机器学习过程中应用此技术至关重要,以确保获得具有更高准确性的更好的模型输出。

191 次查看
