- IMS DB 基础教程
- IMS DB - 首页
- IMS DB - 概述
- IMS DB - 结构
- IMS DB - DL/I 术语
- IMS DB - DL/I 处理
- IMS DB - 控制块
- IMS DB - 编程
- IMS DB - Cobol 基础
- IMS DB - DL/I 函数
- IMS DB - PCB 掩码
- IMS DB - SSA
- IMS DB - 数据检索
- IMS DB - 数据操作
- IMS DB - 二级索引
- IMS DB - 逻辑数据库
- IMS DB - 恢复
- IMS DB 有用资源
- IMS DB - 问答
- IMS DB 快速指南
- IMS DB - 有用资源
IMS DB 快速指南
IMS DB - 概述
简要概述
数据库是相关数据项的集合。这些数据项以一种提供快速便捷访问的方式进行组织和存储。IMS 数据库是一种层次数据库,其中数据存储在不同级别,并且每个实体都依赖于更高级别的实体。使用 IMS 的应用程序系统的物理元素如下图所示。
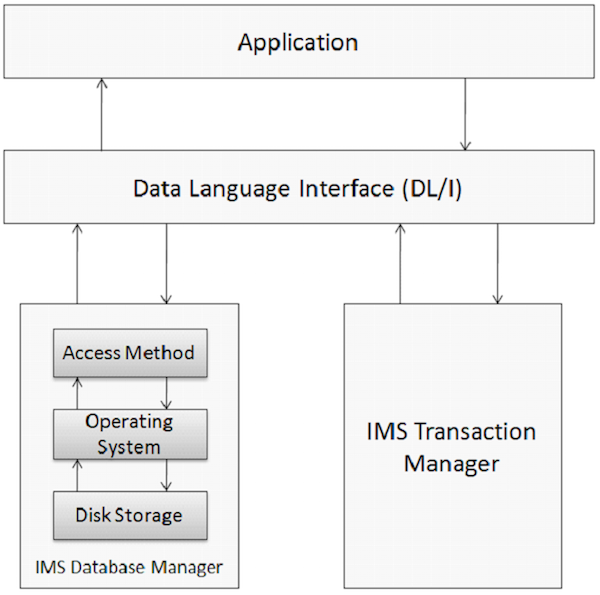
数据库管理
数据库管理系统是一组用于存储、访问和管理数据库中数据的应用程序。IMS 数据库管理系统通过以易于检索的方式组织数据来维护完整性和允许快速恢复数据。IMS 在其数据库管理系统的帮助下维护着世界上大量企业数据。
事务管理器
事务管理器的功能是在数据库和应用程序程序之间提供通信平台。IMS 充当事务管理器。事务管理器与最终用户交互,以从数据库中存储和检索数据。IMS 可以使用 IMS DB 或 DB2 作为其后端数据库来存储数据。
DL/I – 数据语言接口
DL/I 包含允许访问存储在数据库中的数据的应用程序程序。IMS DB 使用 DL/I,它充当程序员在应用程序程序中用于访问数据库的接口语言。我们将在接下来的章节中更详细地讨论这一点。
IMS 的特性
需要注意的要点 -
- IMS 支持来自不同语言(如 Java 和 XML)的应用程序。
- IMS 应用程序和数据可以通过任何平台访问。
- 与 DB2 相比,IMS DB 处理速度非常快。
IMS 的局限性
需要注意的要点 -
- IMS DB 的实现非常复杂。
- IMS 预定义的树结构降低了灵活性。
- IMS DB 难以管理。
IMS DB - 结构
层次结构
IMS 数据库是容纳物理文件的数据库的集合。在层次数据库中,最顶层包含有关实体的一般信息。当我们从顶层到层次结构的底层时,我们获得了越来越多的有关实体的信息。
层次结构中的每个级别都包含段。在标准文件中,很难实现层次结构,但 DL/I 支持层次结构。下图描绘了 IMS DB 的结构。
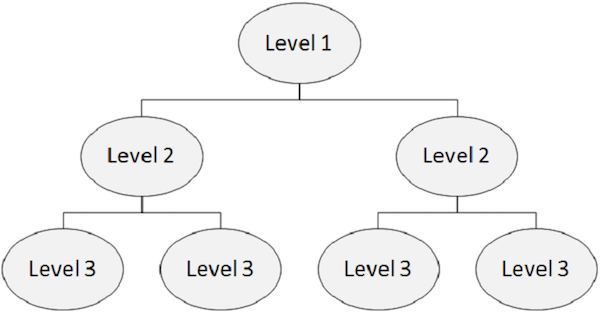
段
需要注意的要点 -
通过将类似数据组合在一起创建段。
它是 DL/I 在任何输入/输出操作期间传输到应用程序程序和从应用程序程序传输的最小的信息单元。
一个段可以包含一个或多个组合在一起的数据字段。
在下面的示例中,段 Student 有四个数据字段。
| 学生 | |||
|---|---|---|---|
| 学号 | 姓名 | 课程 | 手机号码 |
字段
需要注意的要点 -
字段是段中的单个数据片段。例如,学号、姓名、课程和手机号码是学生段中的单个字段。
一个段由相关的字段组成,以收集有关实体的信息。
字段可以用作对段进行排序的键。
字段可以用作限定符来搜索有关特定段的信息。
段类型
需要注意的要点 -
段类型是段中数据的类别。
DL/I 数据库可以有 255 种不同的段类型和 15 个层次级别。
在下图中,有三个段,即图书馆、书籍信息和学生信息。
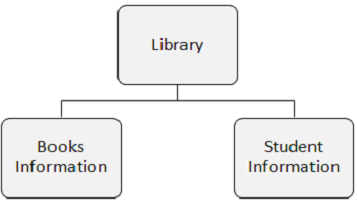
段出现
需要注意的要点 -
段出现是指包含用户数据的特定类型的单个段。在上面的示例中,书籍信息是一种段类型,它可以有任意数量的出现,因为它可以存储有关任意数量书籍的信息。
在 IMS 数据库中,每种段类型只有一个出现,但每种段类型可以有无限数量的出现。
IMS DB - DL/I 术语
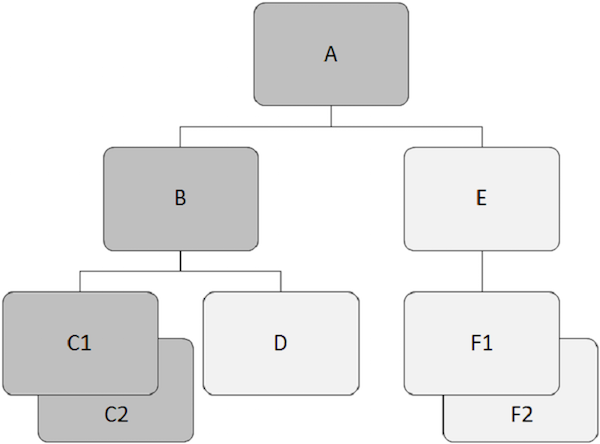
层次数据库基于两个或多个段之间的关系。以下示例显示了段如何在 IMS 数据库结构中相互关联。
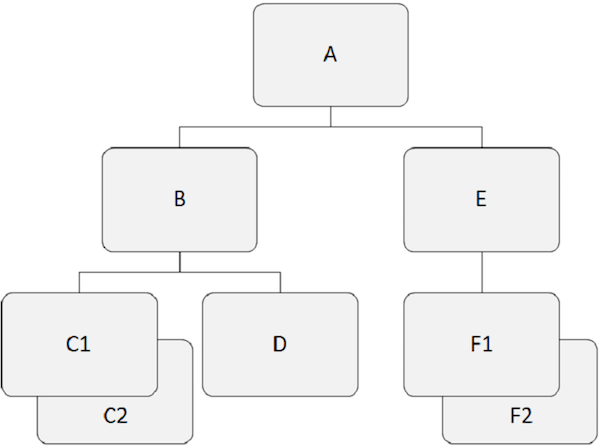
根段
需要注意的要点 -
位于层次结构顶部的段称为根段。
根段是访问所有从属段的唯一段。
根段是数据库中唯一永远不是子段的段。
IMS 数据库结构中只能有一个根段。
例如,在上面的示例中,'A' 是根段。
父段
需要注意的要点 -
父段在其下方直接具有一个或多个从属段。
例如,'A'、'B' 和 'E' 是上面示例中的父段。
从属段
需要注意的要点 -
除根段之外的所有段都称为从属段。
从属段依赖于一个或多个段来呈现完整含义。
例如,'B'、'C1'、'C2'、'D'、'E'、'F1' 和 'F2' 是我们示例中的从属段。
子段
需要注意的要点 -
在层次结构中在其上方直接具有段的任何段都称为子段。
结构中的每个从属段都是子段。
例如,'B'、'C1'、'C2'、'D'、'E'、'F1' 和 'F2' 是子段。
孪生段
需要注意的要点 -
在单个父段下特定段类型的两个或多个段出现称为孪生段。
例如,'C1' 和 'C2' 是孪生段,'F1' 和 'F2' 也是。
兄弟段
需要注意的要点 -
兄弟段是不同类型的段,并且具有相同的父段。
例如,'B' 和 'E' 是兄弟段。同样,'C1'、'C2' 和 'D' 是兄弟段。
数据库记录
需要注意的要点 -
根段的每个出现加上所有下级段出现构成一个数据库记录。
每个数据库记录只有一个根段,但它可以有任何数量的段出现。
在标准文件处理中,记录是应用程序程序用于某些操作的数据单元。在 DL/I 中,该数据单元称为段。单个数据库记录具有许多段出现。
数据库路径
需要注意的要点 -
路径是从数据库记录的根段到任何特定段出现的段序列。
层次结构中的路径不必完整到最低级别。这取决于我们需要了解实体的信息量。
路径必须是连续的,我们不能跳过结构中的中间级别。
在下图中,深灰色中的子记录显示了一条从 'A' 开始并穿过 'C2' 的路径。
IMS DB - DL/I 处理
IMS DB 在不同级别存储数据。通过从应用程序程序发出 DL/I 调用来检索和插入数据。我们将在接下来的章节中详细讨论有关 DL/I 调用的内容。数据可以通过以下两种方式处理 -
- 顺序处理
- 随机处理
顺序处理
当从数据库顺序检索段时,DL/I 会遵循预定义的模式。让我们了解 IMS DB 的顺序处理。
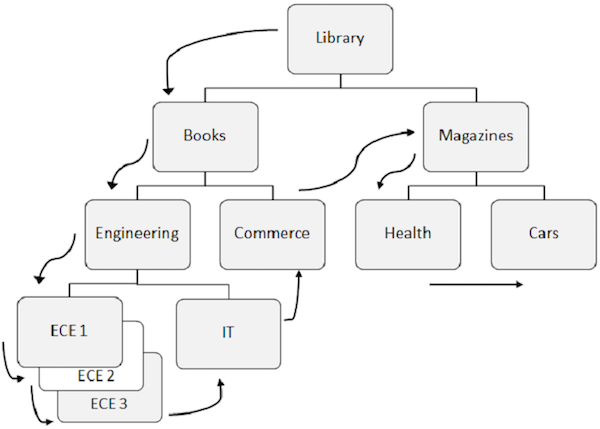
以下是有关顺序处理需要注意的要点 -
DL/I 中访问数据的预定义模式是先向下遍历层次结构,然后从左到右。
首先检索根段,然后 DL/I 移动到第一个左子段,并一直向下到最低级别。在最低级别,它检索所有孪生段的出现。然后它转到右侧段。
为了更好地理解,请观察上图中显示段访问流程的箭头。图书馆是根段,流程从那里开始,一直到汽车以访问单个记录。对所有出现重复相同的过程以获取所有数据记录。
在访问数据时,程序使用数据库中的位置,这有助于检索和插入段。
随机处理
随机处理也称为 IMS DB 中数据的直接处理。让我们举一个例子来了解 IMS DB 中的随机处理 -
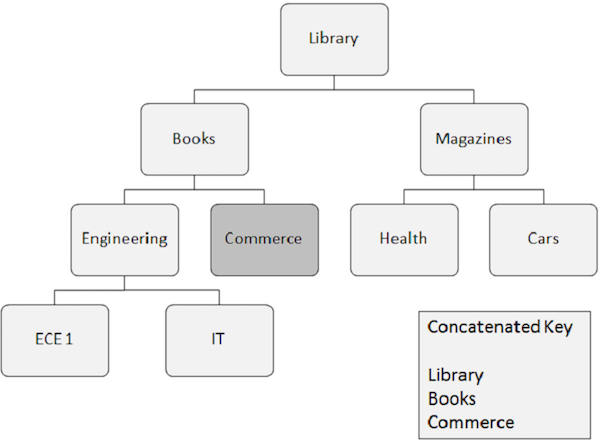
以下是关于随机处理需要注意的要点 -
需要随机检索的段出现需要它所依赖的所有段的关键字段。这些关键字段由应用程序程序提供。
连接键完全识别从根段到您要检索的段的路径。
假设您要检索商务段的出现,那么您需要提供它所依赖的段(如图书馆、书籍和商务)的连接键字段值。
随机处理比顺序处理快。在现实世界中,应用程序将顺序和随机处理方法结合在一起以获得最佳结果。
关键字段
需要注意的要点 -
关键字段也称为顺序字段。
关键字段存在于段中,并用于检索段出现。
关键字段以升序管理段出现。
在每个段中,只能使用一个字段作为关键字段或顺序字段。
搜索字段
如前所述,只能使用一个字段作为关键字段。如果要搜索不是关键字段的其他段字段的内容,则用于检索数据的字段称为搜索字段。
IMS DB - 控制块
IMS 控制块定义了 IMS 数据库的结构以及程序对它们的访问。下图显示了 IMS 控制块的结构。
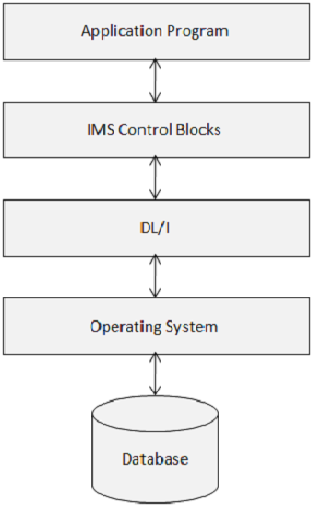
DL/I 使用以下三种类型的控制块 -
- 数据库描述符 (DBD)
- 程序规范块 (PSB)
- 访问控制块 (ACB)
数据库描述符 (DBD)
需要注意的要点 -
DBD 描述了数据库的完整物理结构,一旦所有段都已定义。
在安装 DL/I 数据库时,必须创建一个 DBD,因为它需要访问 IMS 数据库。
应用程序可以使用 DBD 的不同视图。它们称为应用程序数据结构,并在程序规范块中指定。
数据库管理员通过编码 **DBDGEN** 控制语句来创建 DBD。
DBDGEN
DBDGEN 是数据库描述符生成器。创建控制块是数据库管理员的职责。所有加载模块都存储在 IMS 库中。汇编语言宏语句用于创建控制块。下面是一个示例代码,它显示了如何使用 DBDGEN 控制语句创建 DBD -
PRINT NOGEN DBD NAME=LIBRARY,ACCESS=HIDAM DATASET DD1=LIB,DEVICE=3380 SEGM NAME=LIBSEG,PARENT=0,BYTES=10 FIELD NAME=(LIBRARY,SEQ,U),BYTES=10,START=1,TYPE=C SEGM NAME=BOOKSEG,PARENT=LIBSEG,BYTES=5 FIELD NAME=(BOOKS,SEQ,U),BYTES=10,START=1,TYPE=C SEGM NAME=MAGSEG,PARENT=LIBSEG,BYTES=9 FIELD NAME=(MAGZINES,SEQ),BYTES=8,START=1,TYPE=C DBDGEN FINISH END
让我们了解上面 DBDGEN 中使用的术语 -
当您在 **JCL** 中执行上述控制语句时,它会创建一个物理结构,其中 LIBRARY 是根段,BOOKS 和 MAGZINES 是其子段。
第一个 DBD 宏语句标识数据库。在这里,我们需要提及 NAME 和 ACCESS,DL/I 用于访问此数据库。
第二个 DATASET 宏语句标识包含数据库的文件。
段类型使用 SEGM 宏语句定义。我们需要指定该段的 PARENT。如果它是根段,则提及 PARENT=0。
下表显示了 FIELD 宏语句中使用的参数 -
| 序号 | 参数及描述 |
|---|---|
| 1 | 姓名 字段名称,通常为 1 到 8 个字符 |
| 2 | 字节 字段长度 |
| 3 | 起始位置 字段在段中的位置 |
| 4 | 类型 字段的数据类型 |
| 5 | 类型 C 字符数据类型 |
| 6 | 类型 P 压缩十进制数据类型 |
| 7 | 类型 Z 区域十进制数据类型 |
| 8 | 类型 X 十六进制数据类型 |
| 9 | 类型 H 半字二进制数据类型 |
| 10 | 类型 F 全字二进制数据类型 |
程序规范块 (PSB)
PSB 的基本原理如下:
数据库具有由 DBD 定义的单个物理结构,但处理它的应用程序可以具有数据库的不同视图。这些视图称为应用程序数据结构,并在 PSB 中定义。
一个程序在单个执行中不能使用多个 PSB。
应用程序程序有自己的 PSB,并且具有类似数据库处理需求的应用程序程序共享一个 PSB 也很常见。
PSB 由一个或多个称为程序通信块 (PCB) 的控制块组成。PSB 为应用程序程序将访问的每个 DL/I 数据库包含一个 PCB。我们将在后续模块中详细讨论 PCB。
必须执行 PSBGEN 以创建程序的 PSB。
PSBGEN
PSBGEN 称为程序规范块生成器。以下示例使用 PSBGEN 创建 PSB:
PRINT NOGEN PCB TYPE=DB,DBDNAME=LIBRARY,KEYLEN=10,PROCOPT=LS SENSEG NAME=LIBSEG SENSEG NAME=BOOKSEG,PARENT=LIBSEG SENSEG NAME=MAGSEG,PARENT=LIBSEG PSBGEN PSBNAME=LIBPSB,LANG=COBOL END
让我们了解上面 DBDGEN 中使用的术语 -
第一个宏语句是程序通信块 (PCB),它描述了数据库类型、名称、键长度和处理选项。
PCB 宏上的 DBDNAME 参数指定 DBD 的名称。KEYLEN 指定最长连接键的长度。程序可以在数据库中处理。PROCOPT 参数指定程序的处理选项。例如,LS 仅表示加载操作。
SENSEG 称为段级敏感性。它定义了程序对数据库部分的访问权限,并在段级标识。程序可以访问其敏感的所有段内的所有字段。程序也可以具有字段级敏感性。在此,我们定义一个段名和该段的父名称。
最后一个宏语句是 PCBGEN。PSBGEN 是最后一个语句,表明没有更多语句要处理。PSBNAME 定义赋予输出 PSB 模块的名称。LANG 参数指定编写应用程序程序的语言,例如 COBOL。
访问控制块 (ACB)
以下是关于访问控制块需要注意的事项:
应用程序程序的访问控制块将数据库描述符和程序规范块组合成可执行形式。
ACBGEN 称为访问控制块生成器。它用于生成 ACB。
对于联机程序,我们需要预先构建 ACB。因此,在执行应用程序程序之前执行 ACBGEN 实用程序。
对于批处理程序,也可以在执行时生成 ACB。
IMS DB - 编程
包含 DL/I 调用的应用程序程序不能直接执行。相反,需要一个 JCL 来触发 IMS DL/I 批处理模块。IMS 中的批处理初始化模块是 DFSRRC00。应用程序程序和 DL/I 模块一起执行。下图显示了包含 DL/I 调用以访问数据库的应用程序程序的结构。
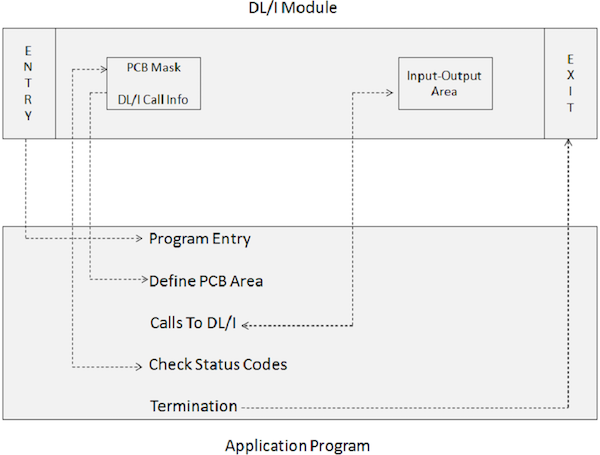
应用程序程序通过以下程序元素与 IMS DL/I 模块交互:
ENTRY 语句指定程序利用 PCB。
PCB 掩码与保存在预构建 PCB 中的信息相关联,该 PCB 从 IMS 接收返回信息。
输入/输出区域用于将数据段传递到 IMS 数据库和从 IMS 数据库传递数据段。
对 DL/I 的调用指定处理功能,例如获取、插入、删除、替换等。
检查状态代码用于检查指定的处理选项的 SQL 返回代码,以通知操作是否成功。
终止语句用于结束包含 DL/I 的应用程序程序的处理。
段布局
到目前为止,我们了解到 IMS 由段组成,这些段用于高级编程语言访问数据。考虑以下我们之前见过的库的 IMS 数据库结构,这里我们看到其段在 COBOL 中的布局:
01 LIBRARY-SEGMENT. 05 BOOK-ID PIC X(5). 05 ISSUE-DATE PIC X(10). 05 RETURN-DATE PIC X(10). 05 STUDENT-ID PIC A(25). 01 BOOK-SEGMENT. 05 BOOK-ID PIC X(5). 05 BOOK-NAME PIC A(30). 05 AUTHOR PIC A(25). 01 STUDENT-SEGMENT. 05 STUDENT-ID PIC X(5). 05 STUDENT-NAME PIC A(25). 05 DIVISION PIC X(10).
应用程序程序概述
IMS 应用程序程序的结构与非 IMS 应用程序程序的结构不同。IMS 程序不能直接执行;而是始终作为子程序调用。IMS 应用程序程序包含程序规范块以提供 IMS 数据库的视图。
当我们执行包含 IMS DL/I 模块的应用程序程序时,应用程序程序和链接到该程序的 PSB 会被加载。然后,应用程序程序触发的 CALL 请求由 IMS 模块执行。
IMS 服务
应用程序程序使用以下 IMS 服务:
- 访问数据库记录
- 发出 IMS 命令
- 发出 IMS 服务调用
- 检查点调用
- 同步调用
- 向联机用户终端发送或接收消息
IMS DB - Cobol 基础
我们在 COBOL 应用程序程序中包含 DL/I 调用以与 IMS 数据库通信。我们在 COBOL 程序中使用以下 DL/I 语句来访问数据库:
- 入口语句
- Goback 语句
- 调用语句
入口语句
它用于将控制权从 DL/I 传递到 COBOL 程序。以下是入口语句的语法:
ENTRY 'DLITCBL' USING pcb-name1
[pcb-name2]
以上语句在 COBOL 程序的过程部分中编码。让我们深入了解 COBOL 程序中入口语句的详细信息:
批处理初始化模块触发应用程序程序并在其控制下执行。
DL/I 加载所需的控制块和模块以及应用程序程序,并将控制权交给应用程序程序。
DLITCBL 代表DL/I 到 COBOL。入口语句用于定义程序中的入口点。
当我们在 COBOL 中调用子程序时,也会提供其地址。同样,当 DL/I 将控制权交给应用程序程序时,它还会提供程序 PSB 中定义的每个 PCB 的地址。
应用程序程序中使用的所有 PCB 必须在 COBOL 程序的连接段中定义,因为 PCB 位于应用程序程序外部。
连接段中的 PCB 定义称为PCB 掩码。
存储中 PCB 掩码和实际 PCB 之间的关系是通过在入口语句中列出 PCB 创建的。入口语句中列出的顺序应与它们在 PSBGEN 中出现的顺序相同。
Goback 语句
它用于将控制权传回 IMS 控制程序。以下是 Goback 语句的语法:
GOBACK
以下是关于 Goback 语句需要注意的基本事项:
GOBACK 在应用程序程序的末尾编码。它将控制权从程序返回到 DL/I。
我们不应使用 STOP RUN,因为它将控制权返回到操作系统。如果我们使用 STOP RUN,DL/I 将永远无法执行其终止功能。因此,在 DL/I 应用程序程序中,使用 Goback 语句。
在发出 Goback 语句之前,必须关闭 COBOL 应用程序程序中使用的所有非 DL/I 数据集,否则程序将异常终止。
调用语句
调用语句用于请求 DL/I 服务,例如对 IMS 数据库执行某些操作。以下是调用语句的语法:
CALL 'CBLTDLI' USING DLI Function Code
PCB Mask
Segment I/O Area
[Segment Search Arguments]
以上语法显示了您可以与调用语句一起使用的参数。我们将在下表中讨论每个参数:
| 序号 | 参数及描述 |
|---|---|
| 1 | DLI 函数代码 标识要执行的 DL/I 函数。此参数是描述 I/O 操作的四个字符字段的名称。 |
| 2 | PCB 掩码 连接段中的 PCB 定义称为 PCB 掩码。它们用于入口语句中。不需要 SELECT、ASSIGN、OPEN 或 CLOSE 语句。 |
| 3 | 段 I/O 区域 输入/输出工作区的名称。这是应用程序程序的一个区域,DL/I 将请求的段放入其中。 |
| 4 | 段搜索参数 这些是根据发出的调用的类型而定的可选参数。它们用于在 IMS 数据库中搜索数据段。 |
以下是关于调用语句需要注意的事项:
CBLTDLI 代表COBOL 到 DL/I。它是与您的程序的对象模块链接编辑的接口模块的名称。
在每次 DL/I 调用之后,DLI 将状态代码存储在 PCB 中。程序可以使用此代码来确定调用是否成功。
示例
为了更好地理解 COBOL,您可以查看我们的 COBOL 教程此处。以下示例显示了使用 IMS 数据库和 DL/I 调用的 COBOL 程序的结构。我们将在后续章节中详细讨论示例中使用的每个参数。
IDENTIFICATION DIVISION.
PROGRAM-ID. TEST1.
DATA DIVISION.
WORKING-STORAGE SECTION.
01 DLI-FUNCTIONS.
05 DLI-GU PIC X(4) VALUE 'GU '.
05 DLI-GHU PIC X(4) VALUE 'GHU '.
05 DLI-GN PIC X(4) VALUE 'GN '.
05 DLI-GHN PIC X(4) VALUE 'GHN '.
05 DLI-GNP PIC X(4) VALUE 'GNP '.
05 DLI-GHNP PIC X(4) VALUE 'GHNP'.
05 DLI-ISRT PIC X(4) VALUE 'ISRT'.
05 DLI-DLET PIC X(4) VALUE 'DLET'.
05 DLI-REPL PIC X(4) VALUE 'REPL'.
05 DLI-CHKP PIC X(4) VALUE 'CHKP'.
05 DLI-XRST PIC X(4) VALUE 'XRST'.
05 DLI-PCB PIC X(4) VALUE 'PCB '.
01 SEGMENT-I-O-AREA PIC X(150).
LINKAGE SECTION.
01 STUDENT-PCB-MASK.
05 STD-DBD-NAME PIC X(8).
05 STD-SEGMENT-LEVEL PIC XX.
05 STD-STATUS-CODE PIC XX.
05 STD-PROC-OPTIONS PIC X(4).
05 FILLER PIC S9(5) COMP.
05 STD-SEGMENT-NAME PIC X(8).
05 STD-KEY-LENGTH PIC S9(5) COMP.
05 STD-NUMB-SENS-SEGS PIC S9(5) COMP.
05 STD-KEY PIC X(11).
PROCEDURE DIVISION.
ENTRY 'DLITCBL' USING STUDENT-PCB-MASK.
A000-READ-PARA.
110-GET-INVENTORY-SEGMENT.
CALL ‘CBLTDLI’ USING DLI-GN
STUDENT-PCB-MASK
SEGMENT-I-O-AREA.
GOBACK.
IMS DB - DL/I 函数
DL/I 函数是在 DL/I 调用中使用的第一个参数。此函数指示 IMS DL/I 调用将对 IMS 数据库执行哪个操作。DL/I 函数的语法如下:
01 DLI-FUNCTIONS. 05 DLI-GU PIC X(4) VALUE 'GU '. 05 DLI-GHU PIC X(4) VALUE 'GHU '. 05 DLI-GN PIC X(4) VALUE 'GN '. 05 DLI-GHN PIC X(4) VALUE 'GHN '. 05 DLI-GNP PIC X(4) VALUE 'GNP '. 05 DLI-GHNP PIC X(4) VALUE 'GHNP'. 05 DLI-ISRT PIC X(4) VALUE 'ISRT'. 05 DLI-DLET PIC X(4) VALUE 'DLET'. 05 DLI-REPL PIC X(4) VALUE 'REPL'. 05 DLI-CHKP PIC X(4) VALUE 'CHKP'. 05 DLI-XRST PIC X(4) VALUE 'XRST'. 05 DLI-PCB PIC X(4) VALUE 'PCB '.
此语法表示以下要点:
对于此参数,我们可以提供任何四个字符的名称作为存储字段来存储函数代码。
DL/I 函数参数在 COBOL 程序的工作存储部分编码。
为了指定 DL/I 函数,程序员需要在 DL/I 调用中编码 05 级数据名称之一,例如 DLI-GU,因为 COBOL 不允许在 CALL 语句上编码文字。
DL/I 函数分为三类:获取、更新和其他函数。让我们详细讨论每个函数。
获取函数
获取函数类似于任何编程语言支持的读取操作。获取函数用于从 IMS DL/I 数据库中获取段。以下获取函数用于 IMS DB:
- 获取唯一
- 获取下一个
- 获取父级内的下一个
- 获取保持唯一
- 获取保持下一个
- 获取保持父级内的下一个
让我们考虑以下 IMS 数据库结构以了解 DL/I 函数调用:
获取唯一
'GU' 代码用于 Get Unique 函数。它的工作原理类似于 COBOL 中的随机读取语句。它用于根据字段值获取特定段的出现。可以使用段搜索参数提供字段值。GU 调用的语法如下所示:
CALL 'CBLTDLI' USING DLI-GU
PCB Mask
Segment I/O Area
[Segment Search Arguments]
如果通过在 COBOL 程序中为所有参数提供适当的值来执行上述调用语句,则可以从数据库中检索段 I/O 区域中的段。在上面的示例中,如果提供 Library、Magazines 和 Health 的字段值,则可以获取 Health 段的所需出现。
获取下一个
'GN' 代码用于 Get Next 函数。它的工作原理类似于 COBOL 中的读取下一条语句。它用于按顺序获取段的出现。访问数据段出现的预定义模式是向下遍历层次结构,然后从左到右。GN 调用的语法如下所示:
CALL 'CBLTDLI' USING DLI-GN
PCB Mask
Segment I/O Area
[Segment Search Arguments]
如果通过在 COBOL 程序中为所有参数提供适当的值来执行上述调用语句,则可以从数据库中按顺序检索段 I/O 区域中的段出现。在上面的示例中,它首先访问 Library 段,然后是 Books 段,依此类推。我们反复执行 GN 调用,直到到达我们想要的段出现。
获取父级内的下一个
'GNP' 代码用于 Get Next within Parent。此函数用于检索从属已建立的父段的段出现序列。GNP 调用的语法如下所示:
CALL 'CBLTDLI' USING DLI-GNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]
获取保持唯一
'GHU' 代码用于 Get Hold Unique。Hold 函数指定将在检索后更新段。Get Hold Unique 函数对应于 Get Unique 调用。以下是 GHU 调用的语法:
CALL 'CBLTDLI' USING DLI-GHU
PCB Mask
Segment I/O Area
[Segment Search Arguments]
获取保持下一个
'GHN' 代码用于 Get Hold Next。Hold 函数指定将在检索后更新段。Get Hold Next 函数对应于 Get Next 调用。以下是 GHN 调用的语法:
CALL 'CBLTDLI' USING DLI-GHN
PCB Mask
Segment I/O Area
[Segment Search Arguments]
获取保持父级内的下一个
'GHNP' 代码用于 Get Hold Next within Parent。Hold 函数指定将在检索后更新段。Get Hold Next within Parent 函数对应于 Get Next within Parent 调用。以下是 GHNP 调用的语法:
CALL 'CBLTDLI' USING DLI-GHNP
PCB Mask
Segment I/O Area
[Segment Search Arguments]
更新函数
更新函数类似于任何其他编程语言中的重写或插入操作。更新函数用于更新 IMS DL/I 数据库中的段。在使用更新函数之前,必须对段出现进行成功的 Hold 子句调用。IMS DB 中使用以下更新函数:
- 插入
- 删除
- 替换
插入
'ISRT' 代码用于 Insert 函数。ISRT 函数用于向数据库添加新段。它用于更改现有数据库或加载新数据库。以下是 ISRT 调用的语法:
CALL 'CBLTDLI' USING DLI-ISRT
PCB Mask
Segment I/O Area
[Segment Search Arguments]
删除
'DLET' 代码用于 Delete 函数。它用于从 IMS DL/I 数据库中删除段。以下是 DLET 调用的语法:
CALL 'CBLTDLI' USING DLI-DLET
PCB Mask
Segment I/O Area
[Segment Search Arguments]
替换
'REPL' 代码用于 Get Hold Next within Parent。Replace 函数用于替换 IMS DL/I 数据库中的段。以下是 REPL 调用的语法:
CALL 'CBLTDLI' USING DLI-REPL
PCB Mask
Segment I/O Area
[Segment Search Arguments]
其他函数
IMS DL/I 调用中使用以下其他函数:
- 检查点
- 重新启动
- PCB
检查点
'CHKP' 代码用于 Checkpoint 函数。它用于 IMS 的恢复功能。以下是 CHKP 调用的语法:
CALL 'CBLTDLI' USING DLI-CHKP
PCB Mask
Segment I/O Area
[Segment Search Arguments]
重新启动
'XRST' 代码用于 Restart 函数。它用于 IMS 的重新启动功能。以下是 XRST 调用的语法:
CALL 'CBLTDLI' USING DLI-XRST
PCB Mask
Segment I/O Area
[Segment Search Arguments]
PCB
PCB 函数用于 IMS DL/I 数据库中的 CICS 程序。以下是 PCB 调用的语法:
CALL 'CBLTDLI' USING DLI-PCB
PCB Mask
Segment I/O Area
[Segment Search Arguments]
您可以在恢复章节中找到有关这些函数的更多详细信息。
IMS DB - PCB 掩码
PCB 代表程序通信块。PCB 掩码是 DL/I 调用中使用的第二个参数。它在链接段中声明。以下是 PCB 掩码的语法:
01 PCB-NAME. 05 DBD-NAME PIC X(8). 05 SEG-LEVEL PIC XX. 05 STATUS-CODE PIC XX. 05 PROC-OPTIONS PIC X(4). 05 RESERVED-DLI PIC S9(5). 05 SEG-NAME PIC X(8). 05 LENGTH-FB-KEY PIC S9(5). 05 NUMB-SENS-SEGS PIC S9(5). 05 KEY-FB-AREA PIC X(n).
以下是需要注意的关键点:
对于每个数据库,DL/I 都维护一个存储区域,称为程序通信块。它存储有关应用程序程序内部访问的数据库的信息。
ENTRY 语句在链接段中的 PCB 掩码和程序 PSB 中的 PCB 之间建立连接。DL/I 调用中使用的 PCB 掩码指示要对哪个数据库进行操作。
您可以将其视为类似于在 COBOL READ 语句中指定文件名或在 COBOL WRITE 语句中指定记录名。不需要 SELECT、ASSIGN、OPEN 或 CLOSE 语句。
在每次 DL/I 调用之后,DL/I 会将状态代码存储在 PCB 中,程序可以使用该代码来确定调用是否成功。
PCB 名称
需要注意的要点 -
PCB 名称是引用 PCB 字段的整个结构的区域的名称。
PCB 名称用于程序语句。
PCB 名称不是 PCB 中的字段。
DBD 名称
需要注意的要点 -
DBD 名称包含字符数据。它长 8 个字节。
PCB 中的第一个字段是被处理的数据库的名称,它从与特定数据库关联的数据库描述库中提供 DBD 名称。
段级别
需要注意的要点 -
段级别称为段层次结构级别指示器。它包含字符数据,长 2 个字节。
段级别字段存储已处理段的级别。当成功检索段时,检索到的段的级别号将存储在此处。
段级别字段的值永远不会大于 15,因为这是 IMS DL/I 数据库中允许的最大级别数。
状态代码
需要注意的要点 -
状态代码字段包含 2 个字节的字符数据。
状态代码包含 DL/I 状态代码。
当 DL/I 成功完成调用的处理时,空格将移动到状态代码字段。
非空格值表示调用未成功。
状态代码 GB 表示文件结束,状态代码 GE 表示未找到请求的段。
Proc 选项
需要注意的要点 -
Proc 选项称为处理选项,包含四个字符数据字段。
处理选项字段指示程序被授权对数据库执行哪种类型的处理。
保留的 DL/I
需要注意的要点 -
保留的 DL/I 称为 IMS 的保留区域。它存储 4 个字节的二进制数据。
IMS 使用此区域进行与其应用程序程序相关的内部链接。
段名称
需要注意的要点 -
SEG 名称称为段名称反馈区域。它包含 8 个字节的字符数据。
在每次 DL/I 调用后,段的名称都存储在此字段中。
长度 FB 键
需要注意的要点 -
长度 FB 键称为键反馈区域的长度。它存储 4 个字节的二进制数据。
此字段用于报告在先前调用期间处理的最低级别段的连接键的长度。
它与键反馈区域一起使用。
灵敏度段数
需要注意的要点 -
灵敏度段数存储 4 个字节的二进制数据。
它定义了应用程序程序对哪个级别敏感。它表示逻辑数据结构中段的数量。
键反馈区域
需要注意的要点 -
键反馈区域的长度因 PCB 而异。
它包含可与程序对数据库的视图一起使用的最长的可能连接键。
在数据库操作之后,DL/I 会将在此字段中处理的最低级别段的连接键返回,并将键的长度返回到键长度反馈区域。
IMS DB - SSA
SSA 代表段搜索参数。SSA 用于识别正在访问的段出现。它是一个可选参数。我们可以根据需要包含任意数量的 SSA。SSA 有两种类型:
- 无限定 SSA
- 限定 SSA
无限定 SSA
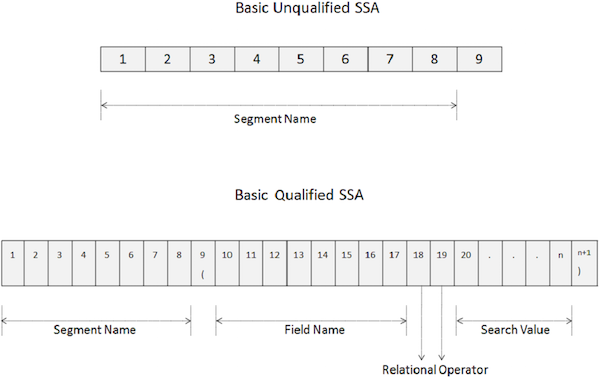
无限定 SSA 提供了在调用内部使用的段的名称。以下是无限定 SSA 的语法:
01 UNQUALIFIED-SSA. 05 SEGMENT-NAME PIC X(8). 05 FILLER PIC X VALUE SPACE.
无限定 SSA 的关键点如下:
基本的无限定 SSA 长 9 个字节。
前 8 个字节保存用于处理的段名称。
最后一个字节始终包含空格。
DL/I 使用最后一个字节来确定 SSA 的类型。
要访问特定段,请将段名称移动到 SEGMENT-NAME 字段。
以下图像显示了无限定和限定 SSA 的结构:
限定 SSA
限定 SSA 提供了段类型以及段的特定数据库出现。以下是限定 SSA 的语法:
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.
限定 SSA 的关键点如下:
限定 SSA 的前 8 个字节保存用于处理的段名称。
第九个字节是左括号'('。
从第十个位置开始的接下来的 8 个字节指定我们要搜索的字段名称。
在字段名称之后,在第 18 和 19 个位置,我们指定两个字符的关系运算符代码。
然后我们指定字段值,在最后一个字节中,有一个右括号')'。
下表显示了限定 SSA 中使用的关系运算符。
| 关系运算符 | 符号 | 描述 |
|---|---|---|
| EQ | = | 等于 |
| NE | ~= ˜ | 不等于 |
| GT | > | 大于 |
| GE | >= | 大于或等于 |
| LT | << | 小于 |
| LE | <= | 小于或等于 |
命令代码
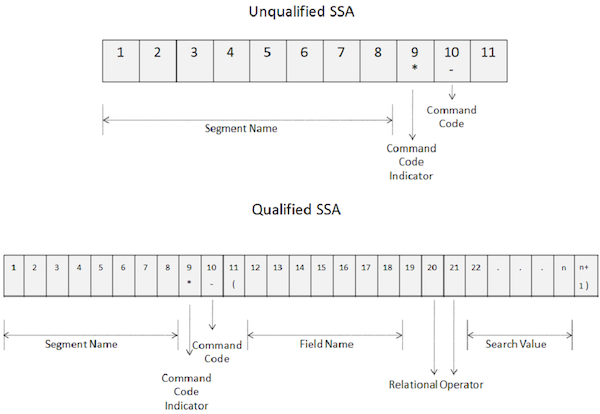
命令代码用于增强 DL/I 调用的功能。命令代码减少了 DL/I 调用的数量,使程序更简单。此外,由于调用次数减少,因此可以提高性能。下图显示了如何在无限定和限定 SSA 中使用命令代码:
命令代码的关键点如下:
要使用命令代码,请在 SSA 的第 9 个位置指定星号,如上图所示。
命令代码编码在第十个位置。
从第十个位置开始,DL/I 将所有字符视为命令代码,直到遇到无限定 SSA 的空格和限定 SSA 的左括号。
下表显示了 SSA 中使用的命令代码列表:
| 命令代码 | 描述 |
|---|---|
| C | 连接键 |
| D | 路径调用 |
| F | 第一次出现 |
| L | 最后一次出现 |
| N | 忽略路径调用 |
| P | 设置父级关系 |
| Q | 入队段 |
| U | 在此级别保持位置 |
| V | 在此级别和所有上级级别保持位置 |
| - | 空命令代码 |
多重限定
多重限定的基本要点如下:
当我们需要使用两个或多个限定或字段进行比较时,需要多重限定。
我们使用 AND 和 OR 等布尔运算符来连接两个或多个限定。
当我们想要根据单个字段的一系列可能值处理段时,可以使用多重限定。
以下是多重限定的语法:
01 QUALIFIED-SSA.
05 SEGMENT-NAME PIC X(8).
05 FILLER PIC X(01) VALUE '('.
05 FIELD-NAME1 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE1 PIC X(m).
05 MUL-QUAL PIC X VALUE '&'.
05 FIELD-NAME2 PIC X(8).
05 REL-OPR PIC X(2).
05 SEARCH-VALUE2 PIC X(n).
05 FILLER PIC X(n+1) VALUE ')'.
MUL-QUAL 是 MULtiple QUALIification 的简称,我们可以在其中提供 AND 或 OR 等布尔运算符。
IMS DB - 数据检索
IMS DL/I 调用中使用的各种数据检索方法如下:
- GU 调用
- GN 调用
- 使用命令代码
- 多重处理
让我们考虑以下 IMS 数据库结构来了解数据检索函数调用:
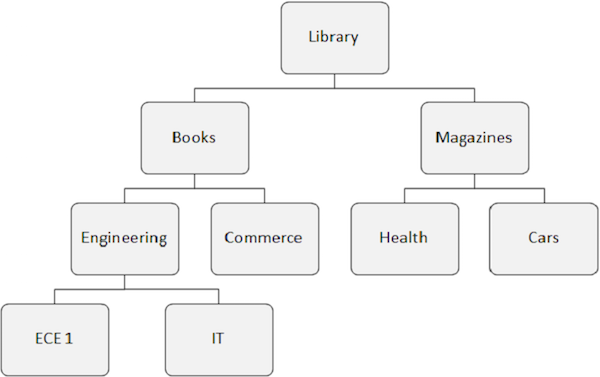
GU 调用
GU 调用的基本原理如下:
GU 调用称为 Get Unique 调用。它用于随机处理。
如果应用程序不定期更新数据库或数据库更新次数较少,则我们使用随机处理。
GU 调用用于将指针放置在特定位置,以便进一步进行顺序检索。
GU 调用独立于先前调用建立的指针位置。
GU 调用的处理基于调用语句中提供的唯一键字段。
如果我们提供的键字段不是唯一的,则 DL/I 返回该键字段的第一个段出现。
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA
上面的示例显示我们通过提供一组完整的限定 SSA 来发出 GU 调用。它包括从根级别到我们想要检索的段出现的所有键字段。
GU 调用注意事项
如果我们没有在调用中提供完整的一组限定 SSA,则 DL/I 会以以下方式工作:
当我们在 GU 调用中使用非限定 SSA 时,DL/I 会访问数据库中满足您指定条件的第一个段出现。
当我们发出没有任何 SSA 的 GU 调用时,DL/I 会返回数据库中根段的第一个出现。
如果在调用中未提及中间级别的某些 SSA,则 DL/I 会使用已建立的位置或段的非限定 SSA 的默认值。
状态代码
下表显示了 GU 调用后的相关状态代码:
| 序号 | 状态代码和描述 |
|---|---|
| 1 | 空格 调用成功 |
| 2 | GE DL/I 找不到满足调用中指定条件的段 |
GN 调用
GN 调用的基本原理如下:
GN 调用称为获取下一个调用。它用于基本的顺序处理。
数据库中指针的初始位置在第一个数据库记录的根段之前。
成功执行 GN 调用后,数据库指针位置位于序列中下一个段出现之前。
GN 调用从先前调用建立的位置开始遍历数据库。
如果 GN 调用是非限定的,则它会返回数据库中下一个段出现,而不管其类型如何,都按层次结构顺序返回。
如果 GN 调用包含 SSA,则 DL/I 仅检索满足所有指定 SSA 要求的段。
CALL 'CBLTDLI' USING DLI-GN
PCB-NAME
IO-AREA
BOOKS-SSA
上面的示例显示我们发出 GN 调用,提供起始位置以顺序读取记录。它获取 BOOKS 段的第一个出现。
状态代码
下表显示了 GN 调用后的相关状态代码:
| 序号 | 状态代码和描述 |
|---|---|
| 1 | 空格 调用成功 |
| 2 | GE DL/I 找不到满足调用中指定条件的段。 |
| 3 | GA 非限定的 GN 调用在数据库层次结构中向上移动一级以获取段。 |
| 4 | GB 到达数据库末尾且未找到段。 |
GK 非限定的 GN 调用尝试获取特定类型的段(而不是刚刚检索到的段),但保留在同一层次结构级别。 |
命令代码
命令代码用于与调用一起获取段出现。下面讨论了与调用一起使用的各种命令代码。
F 命令代码
需要注意的要点 -
当在调用中指定 F 命令代码时,该调用会处理段的第一个出现。
当我们想要顺序处理时,可以使用 F 命令代码,并且可以与 GN 调用和 GNP 调用一起使用。
如果我们在 GU 调用中指定 F 命令代码,则它没有任何意义,因为 GU 调用默认获取第一个段出现。
L 命令代码
需要注意的要点 -
当在调用中指定 L 命令代码时,该调用会处理段的最后一个出现。
当我们想要顺序处理时,可以使用 L 命令代码,并且可以与 GN 调用和 GNP 调用一起使用。
D 命令代码
需要注意的要点 -
D 命令代码用于使用单个调用获取多个段出现。
通常,DL/I 对 SSA 中指定的最低级别段进行操作,但在许多情况下,我们也希望获取其他级别的数据。在这些情况下,我们可以使用 D 命令代码。
D 命令代码简化了整个段路径的检索。
C 命令代码
需要注意的要点 -
C 命令代码用于连接键。
使用关系运算符有点复杂,因为我们需要指定字段名、关系运算符和搜索值。相反,我们可以使用 C 命令代码提供连接键。
以下示例显示了 C 命令代码的使用:
01 LOCATION-SSA.
05 FILLER PIC X(11) VALUE ‘INLOCSEG*C(‘.
05 LIBRARY-SSA PIC X(5).
05 BOOKS-SSA PIC X(4).
05 ENGINEERING-SSA PIC X(6).
05 IT-SSA PIC X(3)
05 FILLER PIC X VALUE ‘)’.
CALL 'CBLTDLI' USING DLI-GU
PCB-NAME
IO-AREA
LOCATION-SSA
P 命令代码
需要注意的要点 -
当我们发出 GU 或 GN 调用时,DL/I 会在其检索到的最低级别段处建立其父级关系。
如果我们包含 P 命令代码,则 DL/I 会在其层次路径中更高级别的段处建立其父级关系。
U 命令代码
需要注意的要点 -
当在 GN 调用中的非限定 SSA 中指定 U 命令代码时,DL/I 会限制对段的搜索。
如果将 U 命令代码与限定 SSA 一起使用,则会忽略它。
V 命令代码
需要注意的要点 -
V 命令代码的工作方式类似于 U 命令代码,但它限制了特定级别以及层次结构中所有上级级别的段的搜索。
当将 V 命令代码与限定 SSA 一起使用时,会忽略它。
Q 命令代码
需要注意的要点 -
Q 命令代码用于将段入队或保留,以供您的应用程序程序独占使用。
Q 命令代码用于交互式环境中,在该环境中,另一个程序可能会更改段。
多重处理
一个程序可以在 IMS 数据库中拥有多个位置,这称为多重处理。多重处理可以通过两种方式完成:
- 多个 PCB
- 多重定位
多个 PCB
可以为单个数据库定义多个 PCB。如果有多个 PCB,则应用程序程序可以拥有不同的视图。由于额外 PCB 带来的开销,这种实现多重处理的方法效率低下。
多重定位
程序可以使用单个 PCB 在数据库中维护多个位置。这是通过为每个层次路径维护一个不同的位置来实现的。多重定位用于同时顺序访问两种或多种类型的段。
IMS DB - 数据操作
在 IMS DL/I 调用中使用的不同数据操作方法如下:
- ISRT 调用
- 获取保持调用
- REPL 调用
- DLET 调用
让我们考虑以下 IMS 数据库结构以了解数据操作函数调用:
ISRT 调用
需要注意的要点 -
ISRT 调用称为插入调用,用于向数据库添加段出现。
ISRT 调用用于加载新的数据库。
当段描述字段加载了数据时,我们会发出 ISRT 调用。
必须在调用中指定非限定或限定 SSA,以便 DL/I 知道将段出现放置在何处。
我们可以在调用中使用非限定和限定 SSA 的组合。可以为所有上述级别指定限定 SSA。让我们考虑以下示例:
CALL 'CBLTDLI' USING DLI-ISRT
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
UNQUALIFIED-ENGINEERING-SSA
上面的示例显示我们正在通过提供限定和非限定 SSA 的组合来发出 ISRT 调用。
当我们插入的新段具有唯一键字段时,它会添加到正确的位置。如果键字段不是唯一的,则会根据数据库管理员定义的规则添加它。
当我们发出 ISRT 调用而不指定键字段时,插入规则会告诉将段相对于现有双胞胎段放置在何处。以下是插入规则:
首先 − 如果规则是 first,则新的段将添加到任何现有双胞胎之前。
最后 − 如果规则是 last,则新的段将添加到所有现有双胞胎之后。
这里 − 如果规则是 here,则它将添加到相对于现有双胞胎的当前位置,可以是 first、last 或任何位置。
状态代码
下表显示了 ISRT 调用后的相关状态代码:
| 序号 | 状态代码和描述 |
|---|---|
| 1 | 空格 调用成功 |
| 2 | GE 使用多个 SSA,并且 DL/I 无法使用指定的路径满足调用。 |
| 3 | II 尝试添加数据库中已存在的段出现。 |
| 4 | LB / LC LD / LE 在加载处理期间,我们会获得这些状态代码。在大多数情况下,它们表示您没有按精确的层次结构顺序插入段。 |
获取保持调用
需要注意的要点 -
在 DL/I 调用中,我们指定三种类型的获取保持调用
获取保持唯一 (GHU)
获取保持下一个 (GHN)
获取保持父级内部的下一个 (GHNP)
保持功能指定我们将更新检索后的段。因此,在 REPL 或 DLET 调用之前,必须发出成功的保持调用,以告知 DL/I 更新数据库的意图。
REPL 调用
需要注意的要点 -
成功执行获取保持调用后,我们会发出 REPL 调用来更新段出现。
我们不能使用 REPL 调用更改段的长度。
我们不能使用 REPL 调用更改键字段的值。
我们不能将限定 SSA 与 REPL 调用一起使用。如果我们指定限定 SSA,则调用会失败。
CALL 'CBLTDLI' USING DLI-GHU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA.
*Move the values which you want to update in IT segment occurrence*
CALL ‘CBLTDLI’ USING DLI-REPL
PCB-NAME
IO-AREA.
上面的示例使用 REPL 调用更新 IT 段出现。首先,我们发出 GHU 调用以获取我们要更新的段出现。然后,我们发出 REPL 调用以更新该段的值。
DLET 调用
需要注意的要点 -
DLET 调用的工作方式与 REPL 调用非常相似。
成功执行获取保持调用后,我们会发出 DLET 调用以删除段出现。
我们不能将限定 SSA 与 DLET 调用一起使用。如果我们指定限定 SSA,则调用会失败。
CALL 'CBLTDLI' USING DLI-GHU
PCB-NAME
IO-AREA
LIBRARY-SSA
BOOKS-SSA
ENGINEERING-SSA
IT-SSA.
CALL ‘CBLTDLI’ USING DLI-DLET
PCB-NAME
IO-AREA.
上面的示例使用 DLET 调用删除 IT 段出现。首先,我们发出 GHU 调用以获取我们要删除的段出现。然后,我们发出 DLET 调用以更新该段的值。
状态代码
下表显示了 REPL 或 DLET 调用后的相关状态代码:
| 序号 | 状态代码和描述 |
|---|---|
| 1 | 空格 调用成功 |
| 2 | AJ 在 REPL 或 DLET 调用中使用限定 SSA。 |
| 3 | DJ 程序在没有紧接其前的获取保持调用的情况下发出替换调用。 |
| 4 | DA 程序在发出 REPL 或 DLET 调用之前更改了段的键字段 |
IMS DB - 二级索引
当我们想要访问数据库而不使用完整的连接键或不想使用顺序主字段时,使用辅助索引。
索引指针段
DL/I 将指向索引数据库的段的指针存储在单独的数据库中。索引指针段是唯一类型的辅助索引。它由两部分组成:
- 前缀元素
- 数据元素
前缀元素
索引指针段的前缀部分包含指向索引目标段的指针。索引目标段是可以使用辅助索引访问的段。
数据元素
数据元素包含来自已构建索引的索引数据库中段的键值。这也被称为索引源段。
以下是关于辅助索引需要注意的关键点:
索引源段和目标源段不必相同。
当我们设置辅助索引时,它会由 DL/I 自动维护。
DBA 根据多个访问路径定义许多辅助索引。这些辅助索引存储在单独的索引数据库中。
我们不应该创建更多的二级索引,因为它们会给 DL/I 带来额外的处理开销。
辅助键
需要注意的要点 -
索引源段中构建二级索引的字段称为辅助键。
任何字段都可以用作辅助键。它不必是段的顺序字段。
辅助键可以是索引源段内单个字段的任何组合。
辅助键值不必唯一。
辅助数据结构
需要注意的要点 -
当我们构建二级索引时,数据库的表观层次结构也会发生变化。
索引目标段成为表观根段。如下图所示,即使 Engineering 段不是根段,它也成为根段。
二级索引导致的数据库结构重排称为辅助数据结构。
辅助数据结构不会对磁盘上存在的物理数据库主结构进行任何更改。它只是一种在应用程序程序前面更改数据库结构的方式。
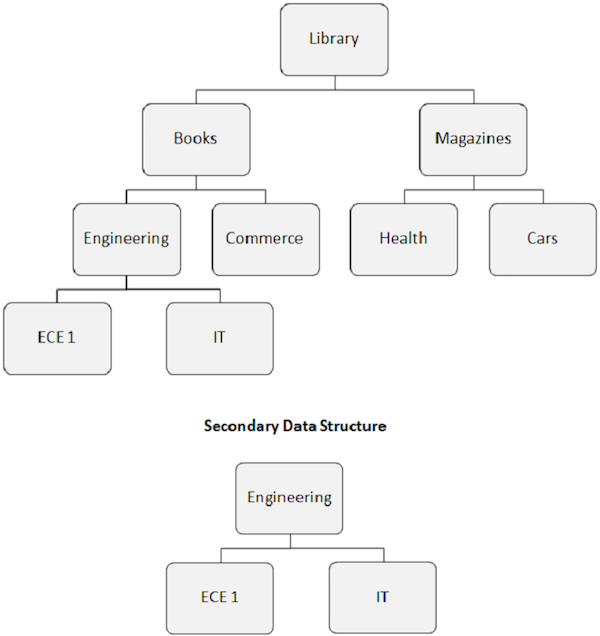
独立 AND 运算符
需要注意的要点 -
当 AND(* 或 &)运算符与二级索引一起使用时,它被称为依赖 AND 运算符。
独立 AND(#)允许我们指定依赖 AND 无法实现的限定条件。
此运算符仅可用于索引源段依赖于索引目标段的二级索引。
我们可以使用独立 AND 编码 SSA,以指定根据两个或多个依赖源段中的字段处理目标段的某个出现。
01 ITEM-SELECTION-SSA.
05 FILLER PIC X(8).
05 FILLER PIC X(1) VALUE '('.
05 FILLER PIC X(10).
05 SSA-KEY-1 PIC X(8).
05 FILLER PIC X VALUE '#'.
05 FILLER PIC X(10).
05 SSA-KEY-2 PIC X(8).
05 FILLER PIC X VALUE ')'.
稀疏排序
需要注意的要点 -
稀疏排序也称为稀疏索引。我们可以使用二级索引数据库和稀疏排序从索引中删除一些索引源段。
稀疏排序用于提高性能。当索引源段的某些出现未使用时,我们可以将其删除。
DL/I 使用抑制值或抑制例程或两者来确定是否应对段进行索引。
如果索引源段中顺序字段的值与抑制值匹配,则不建立索引关系。
抑制例程是用户编写的程序,它评估段并确定是否应对其进行索引。
当使用稀疏索引时,其功能由 DL/I 处理。我们不需要在应用程序程序中为它做特殊规定。
DBDGEN 需求
如前面模块所述,DBDGEN 用于创建 DBD。当我们创建二级索引时,会涉及两个数据库。DBA 需要使用两个 DBDGEN 创建两个 DBD,以在索引数据库和二级索引数据库之间创建关系。
PSBGEN 需求
为数据库创建二级索引后,DBA 需要创建 PSB。程序的 PSBGEN 在 PSB 宏的 PROCSEQ 参数上指定数据库的正确处理顺序。对于 PROCSEQ 参数,DBA 编码二级索引数据库的 DBD 名称。
IMS DB - 逻辑数据库
IMS 数据库有一条规则,即每种段类型只能有一个父段。这限制了物理数据库的复杂性。许多 DL/I 应用程序需要一个复杂的结构,允许一个段具有两种父段类型。为了克服此限制,DL/I 允许 DBA 实现逻辑关系,其中一个段可以同时具有物理父段和逻辑父段。我们可以在一个物理数据库内创建额外的关系。实施逻辑关系后的新数据结构称为逻辑数据库。
逻辑关系
逻辑关系具有以下属性:
逻辑关系是两个在逻辑上而不是物理上相关的段之间的路径。
通常,逻辑关系是在独立的数据库之间建立的。但也可以在一个特定数据库的段之间建立关系。
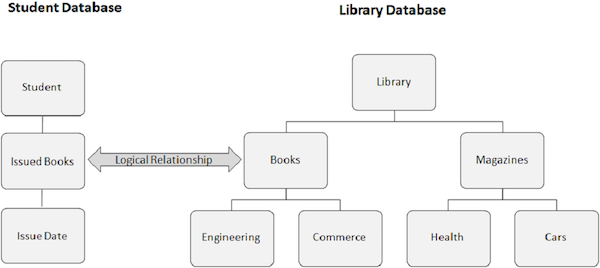
下图显示了两个不同的数据库。一个是学生数据库,另一个是图书馆数据库。我们在学生数据库的“已借书籍”段和图书馆数据库的“书籍”段之间创建逻辑关系。
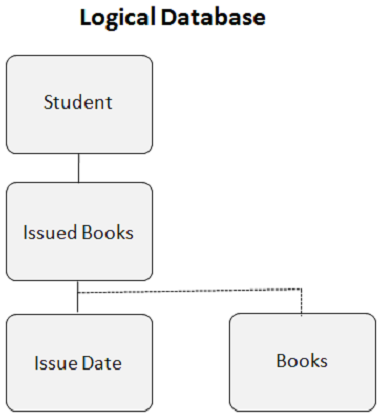
创建逻辑关系后,逻辑数据库如下所示:
逻辑子段
逻辑子段是逻辑关系的基础。它是一个物理数据段,但对于 DL/I 来说,它看起来好像有两个父段。以上示例中的“书籍”段有两个父段。“已借书籍”段是逻辑父段,“图书馆”段是物理父段。一个逻辑子段出现仅有一个逻辑父段出现,一个逻辑父段出现可以有多个逻辑子段出现。
逻辑双胞胎
逻辑双胞胎是逻辑子段类型的出现,它们都从属于逻辑父段类型的单个出现。DL/I 使逻辑子段看起来类似于实际的物理子段。这也称为虚拟逻辑子段。
逻辑关系类型
DBA 在段之间创建逻辑关系。要实现逻辑关系,DBA 必须在相关物理数据库的 DBDGEN 中指定它。逻辑关系有三种类型:
- 单向
- 双向虚拟
- 双向物理
单向
逻辑连接从逻辑子段到逻辑父段,反之则不行。
双向虚拟
它允许双向访问。逻辑子段在其物理结构中以及相应的虚拟逻辑子段可以看作是配对的段。
双向物理
逻辑子段在物理上存储为其物理和逻辑父段的从属段。对于应用程序程序,它看起来与双向虚拟逻辑子段相同。
编程注意事项
使用逻辑数据库的编程注意事项如下:
访问数据库的 DL/I 调用在逻辑数据库中也保持不变。
程序规范块指示我们在调用中使用的结构。在某些情况下,我们无法识别我们正在使用逻辑数据库。
逻辑关系为数据库编程增加了新的维度。
在使用逻辑数据库时必须小心,因为两个数据库集成在一起。如果修改一个数据库,则必须在另一个数据库中反映相同的修改。
程序规范应指示在数据库上允许哪些处理。如果违反处理规则,您将获得非空白状态代码。
连接段
逻辑子段始终以目标父段的完整连接键开头。这称为目标父段连接键 (DPCK)。对于逻辑子段,您需要始终在段 I/O 区域的开头编码 DPCK。在逻辑数据库中,连接段在不同物理数据库中定义的段之间建立连接。连接段包含以下两个部分:
- 逻辑子段
- 目标父段
逻辑子段包含以下两个部分:
- 目标父段连接键 (DPCK)
- 逻辑子段用户数据

当我们在更新期间使用连接段时,可能可以通过单个调用添加或更改逻辑子段和目标父段中的数据。这也取决于 DBA 为数据库指定的规则。对于插入,请在正确的位置提供 DPCK。对于替换或删除,请勿更改连接段任一部分中的 DPCK 或顺序字段数据。
IMS DB - 恢复
数据库管理员需要计划数据库恢复以防系统故障。故障可能有多种类型,例如应用程序崩溃、硬件错误、电源故障等。
简单方法
数据库恢复的一些简单方法如下:
定期备份重要数据集,以便保留针对数据集发布的所有事务。
如果数据集由于系统故障而损坏,则可以通过恢复备份副本来解决该问题。然后将累积的事务重新发布到备份副本以使其更新。
简单方法的缺点
简单方法进行数据库恢复的缺点如下:
重新发布累积的事务会消耗大量时间。
所有其他应用程序都需要等待执行,直到恢复完成。
如果涉及逻辑和二级索引关系,则数据库恢复比文件恢复更长。
异常终止例程
DL/I 程序崩溃的方式与标准程序崩溃的方式不同,因为标准程序由操作系统直接执行,而 DL/I 程序则不是。通过使用异常终止例程,系统会进行干预,以便在异常结束 (ABEND) 后可以进行恢复。异常终止例程执行以下操作:
- 关闭所有数据集
- 取消队列中所有挂起作业
- 创建存储转储以找出 ABEND 的根本原因
此例程的限制在于它不能确保正在使用的数据的准确性。
DL/I 日志
当应用程序程序 ABEND 时,需要恢复应用程序程序所做的更改,更正错误,然后重新运行应用程序程序。为此,需要 DL/I 日志。以下是关于 DL/I 日志的关键点:
DL/I 将应用程序程序所做的所有更改记录在一个称为日志文件的文件中。
当应用程序程序更改段时,DL/I 会创建其前映像和后映像。
如果应用程序程序崩溃,可以使用这些段映像来恢复段。
DL/I 使用一种称为提前写入日志的技术来记录数据库更改。使用提前写入日志,数据库更改会在写入实际数据集之前写入日志数据集。
由于日志始终领先于数据库,因此恢复实用程序可以确定任何数据库更改的状态。
当程序执行更改数据库段的调用时,DL/I 会处理其日志部分。
恢复 - 前向和后向
数据库恢复的两种方法是:
前向恢复 - DL/I 使用日志文件存储更改数据。使用此日志文件重新发布累积的事务。
后向恢复 - 后向恢复也称为回退恢复。程序的日志记录被反向读取,并在数据库中逆转其影响。当回退完成时,数据库处于与故障发生前相同的状态,假设在此期间没有其他应用程序程序更改数据库。
检查点
检查点是应用程序程序完成的数据库更改被认为完整且准确的阶段。下面列出了关于检查点的注意事项:
在最近检查点之前进行的数据库更改不会被后向恢复逆转。
在最近检查点之后记录的数据库更改不会在正向恢复期间应用于数据库的映像副本。
使用检查点方法,当恢复过程完成时,数据库将恢复到最近检查点的状态。
批处理程序的默认值为程序的开始是检查点。
可以使用检查点调用 (CHKP) 建立检查点。
检查点调用会导致在 DL/I 日志上写入检查点记录。
下面显示了 CHKP 调用的语法:
CALL 'CBLTDLI' USING DLI-CHKP
PCB-NAME
CHECKPOINT-ID
有两种检查点方法:
基本检查点 - 它允许程序员发出 DL/I 恢复实用程序在恢复处理期间使用的检查点调用。
符号检查点 - 它是检查点的一种高级形式,与扩展重启功能结合使用。符号检查点和扩展重启一起允许应用程序程序员对程序进行编码,以便它们可以在检查点之后的点恢复处理。