
 数据结构
数据结构 网络
网络 关系数据库管理系统 (RDBMS)
关系数据库管理系统 (RDBMS) 操作系统
操作系统 Java
Java iOS
iOS HTML
HTML CSS
CSS Android
Android Python
Python C 编程
C 编程 C++
C++ C#
C# MongoDB
MongoDB MySQL
MySQL Javascript
Javascript PHP
PHP使用字符字面量存储 Unicode 字符的 Java 程序
Unicode 是一种国际字符集,包含来自全球多种语言的大量字符、符号和文字。Java 编程语言作为一种平台无关的语言,内置支持 Unicode 字符,允许开发者创建能够与多种语言和文字无缝工作的应用程序。
在 Java 中,char 数据类型用于存储 Unicode 字符,字符字面量用于在源代码中表示这些字符。字符字面量是用单引号 (' ') 括起来的单个 Unicode 字符,可以直接赋值给 char 变量。
算法
步骤 1 − 声明一个 char 变量。
声明一个 char 变量,并使用合适的名称。
例如:char myChar;
步骤 2 − 将 Unicode 字符字面量赋值给变量。
将用单引号括起来的 Unicode 字符字面量赋值给 char 变量。
例如:myChar = '\u0041';(将 Unicode 字符 'A' 赋值给 myChar)
步骤 3 − (可选)执行操作或处理 Unicode 字符。
根据程序需要,对存储在 char 变量中的 Unicode 字符执行任何操作或处理。
步骤 4 − 打印存储的 Unicode 字符。
使用 System.out.println() 方法打印存储在 char 变量中的 Unicode 字符。
例如:System.out.println("Stored character: " + myChar);(在控制台中打印“Stored character: A”)
方法
在 Java 中处理 Unicode 字符有两种方法:使用 Unicode 转义序列和直接存储 Unicode 字符。
第一种方法涉及使用转义序列表示 Unicode 字符,当字符无法直接在 Java 代码中输入或显示时很有用。第二种方法涉及直接将 Unicode 字符存储在变量中,当字符可以直接输入或显示时更方便。
方法的选择取决于程序的具体要求。但是,一般来说,当字符可以直接输入或显示时,方法 2 更简单方便;而当字符无法直接输入或显示时,方法 1 是必要的。
方法 1:使用 Unicode 转义序列
在 Java 中存储 Unicode 字符的一种方法是使用 Unicode 转义序列。转义序列是一系列表示特殊字符的字符。在 Java 中,Unicode 转义序列以字符 '\u' 开头,后跟四个十六进制数字,表示所需字符的 Unicode 代码点。
public class UnicodeCharacterLiteral {
public static void main (String[]args)
{
//Unicode escape sequence
char unicodeChar = '\u0041';
// point for 'A'
System.out.println("Stored Unicode Character: " + unicodeChar);
}
}
输出
Stored Unicode Character: A
在上面的代码片段中,Unicode 转义序列 '\u0041' 代表字符 'A'。转义序列被赋值给 char 变量 unicodeChar,然后将存储的字符打印到控制台。
方法 2:直接存储 Unicode 字符
或者,您可以通过将 Unicode 字符用单引号括起来直接将其存储在 char 变量中。但是,对于无法使用键盘直接输入或不可见的字符(例如控制字符),这种方法可能不可行。
public class UnicodeCharacterLiteral {
public static void main(String[] args) { // Storing Unicode character directly
char unicodeChar = 'A';
// Directly storing the character 'A'
System.out.println("Stored Unicode Character: " + unicodeChar);
}
}
输出
Stored Unicode Character: A
在这个例子中,字符 'A' 直接用单引号括起来并赋值给 char 变量 unicodeChar。然后将存储的字符打印到控制台。
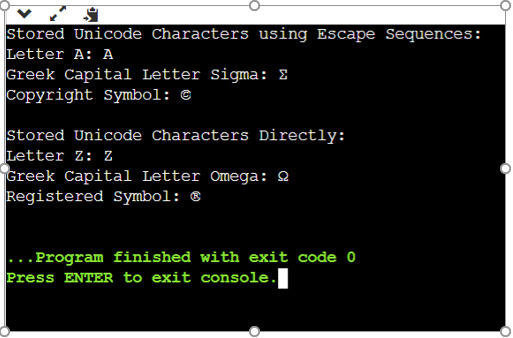
工作示例 1:存储和打印各种 Unicode 字符
public class UnicodeCharacterExamples {
public static void main(String[] args) {
// Storing Unicode characters using escape sequences
char letterA = '\u0041';
char letterSigma = '\u03A3';
char copyrightSymbol = '\u00A9';
// Storing Unicode characters directly
char letterZ = 'Z';
char letterOmega = 'Ω';
char registeredSymbol = '®';
// Printing the stored Unicode characters
System.out.println("Stored Unicode Characters using Escape Sequences:");
System.out.println("Letter A: " + letterA);
System.out.println("Greek Capital Letter Sigma: " + letterSigma);
System.out.println("Copyright Symbol: " + copyrightSymbol);
System.out.println("\nStored Unicode Characters Directly:");
System.out.println("Letter Z: " + letterZ);
System.out.println("Greek Capital Letter Omega: " + letterOmega);
System.out.println("Registered Symbol: " + registeredSymbol);
}
}
输出
Stored Unicode Characters using Escape Sequences: Letter A: A Greek Capital Letter Sigma: Σ Copyright Symbol: © Stored Unicode Characters Directly: Letter Z: Z Greek Capital Letter Omega: Ω Registered Symbol: ®
工作示例 2:处理 Unicode 字符
此示例演示如何处理存储的 Unicode 字符。它计算大写字母 'A' 和小写字母 'a' 之间的差值,并使用该差值来计算大写字母 'C'。然后,它通过向大写字母 'C' 的 Unicode 代码点添加 32 来计算小写字母 'c'。处理后的 Unicode 字符将打印到控制台。
public class UnicodeCharacterManipulation {
public static void main(String[] args) {
// Storing Unicode characters using escape sequences
char letterA = '\u0041';
char letterSmallA = '\u0061';
// Storing Unicode characters directly
char letterB = 'B';
char letterSmallB = 'b';
// Manipulating the stored Unicode characters
int difference = letterA - letterSmallA;
char letterC = (char) (letterB + difference);
char letterSmallC = (char) (letterC + 32);
// Printing the manipulated Unicode characters
System.out.println("Manipulated Unicode Characters:");
System.out.println("Difference between A and a: " + difference);
System.out.println("Calculated Letter C: " + letterC);
System.out.println("Calculated Letter c: " + letterSmallC);
}
}
输出
Manipulated Unicode Characters: Difference between A and a: -32 Calculated Letter C: C Calculated Letter c: c
结论
在 Java 中,您可以使用字符字面量来存储 Unicode 字符,方法是使用 Unicode 转义序列或直接将字符用单引号括起来。这两种方法各有优缺点。转义序列提供了一种一致的方法来表示源代码中的任何 Unicode 字符,而直接存储字符在处理易于输入或显示的字符时更方便。
本文提供了一种在 Java 中存储 Unicode 字符的算法,讨论了两种存储这些字符的不同方法,并演示了每种方法的工作示例。了解这些技术将帮助开发者创建能够与多种语言和文字无缝工作的应用程序,从而充分利用 Java 编程中 Unicode 的强大功能。

2K+ 浏览量
