
- JCL 教程
- JCL 首页
- JCL - 概述
- JCL - 环境
- JCL - JOB 语句
- JCL - EXEC 语句
- JCL - DD 语句
- JCL - 基本库
- JCL - 过程
- JCL - 条件处理
- JCL - 定义数据集
- JCL - 输入/输出方法
- JCL - 运行 COBOL 程序
- JCL - 实用程序
- JCL - 基本排序技巧
- JCL 有用资源
- JCL - 问题与解答
- JCL 快速指南
- JCL - 有用资源
- JCL - 讨论
JCL 快速指南
JCL - 概述
何时使用 JCL
JCL 用于大型机环境中,作为程序(例如:COBOL、汇编程序或 PL/I)与操作系统之间的通信手段。在大型机环境中,程序可以以批处理和联机模式执行。批处理系统的示例可以通过 VSAM(虚拟存储访问方法)文件处理银行交易并将其应用于相应的账户。联机系统的示例可以是银行员工用来开户的后端屏幕。在批处理模式下,程序作为作业通过 JCL 提交给操作系统。
批处理和联机处理在输入、输出和程序执行请求方面有所不同。在批处理中,这些方面被输入到 JCL 中,JCL 又被操作系统接收。
作业处理
作业是工作单元,可以由多个作业步骤组成。每个作业步骤都通过一组作业控制语句在作业控制语言 (JCL) 中指定。
操作系统使用作业输入系统 (JES) 将作业接收进入操作系统、安排作业进行处理并控制输出。
作业处理经历以下一系列步骤
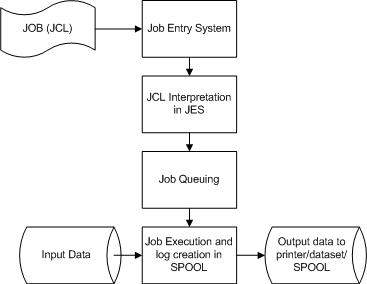
作业提交 - 将 JCL 提交给 JES。
作业转换 - JCL 以及 PROC 被转换为 JES 可以理解的解释文本,并存储到一个数据集(我们称之为 SPOOL)中。
作业排队 - JES 根据 JOB 语句中的 CLASS 和 PRTY 参数(在JCL - JOB 语句章节中解释)确定作业的优先级。检查 JCL 错误,如果无错误,则将作业调度到作业队列中。
作业执行 - 当作业达到最高优先级时,它将从作业队列中取出执行。从 SPOOL 中读取 JCL,执行程序,并将输出重定向到 JCL 中指定的相应输出目标。
清除 - 作业完成后,释放分配的资源和 JES SPOOL 空间。为了存储作业日志,我们需要在它从 SPOOL 中释放之前将作业日志复制到另一个数据集。
JCL - 环境设置
在 Windows/Linux 上安装 JCL
有许多可用于 Windows 的免费大型机仿真器,可用于编写和学习 JCL 示例。
其中一个仿真器是 Hercules,可以通过以下几个简单的步骤轻松安装在 Windows 上
下载并安装 Hercules 仿真器,可从 Hercules 的主页获取:www.hercules-390.eu
在 Windows 机器上安装软件包后,它将创建一个名为C:\Mainframes的文件夹。
运行命令提示符 (CMD) 并在 CMD 中到达 C:\Mainframes 目录。
有关编写和执行 JCL 的各种命令的完整指南可以在 URL www.jaymoseley.com/hercules/installmvs/instmvs2.htm 上找到。
Hercules 是大型机 System/370 和 ESA/390 架构以及最新的 64 位 z/Architecture 的开源软件实现。Hercules 在 Linux、Windows、Solaris、FreeBSD 和 Mac OS X 上运行。
在大型机上运行 JCL
用户可以通过多种方式连接到大型机服务器,例如瘦客户端、虚拟终端、虚拟客户端系统 (VCS) 或虚拟桌面系统 (VDS)。
每个有效用户都会获得一个登录 ID,用于输入 Z/OS 接口(TSO/E 或 ISPF)。在 Z/OS 接口中,可以对 JCL 进行编码并将其存储为分区数据集 (PDS) 中的一个成员。提交 JCL 后,它将被执行,并根据上一章的作业处理部分中所述接收输出。
JCL 的结构
下面给出了包含常用语句的 JCL 的基本结构
//SAMPJCL JOB 1,CLASS=6,MSGCLASS=0,NOTIFY=&SYSUID (1) //* (2) //STEP010 EXEC PGM=SORT (3) //SORTIN DD DSN=JCL.SAMPLE.INPUT,DISP=SHR (4) //SORTOUT DD DSN=JCL.SAMPLE.OUTPUT, (5) // DISP=(NEW,CATLG,CATLG),DATACLAS=DSIZE50 //SYSOUT DD SYSOUT=* (6) //SYSUDUMP DD SYSOUT=C (6) //SYSPRINT DD SYSOUT=* (6) //SYSIN DD * (6) SORT FIELDS=COPY INCLUDE COND=(28,3,CH,EQ,C'XXX') /* (7)
程序描述
下面解释了编号的 JCL 语句
(1) JOB 语句 - 指定 SPOOL 作业所需的信息,例如作业 ID、执行优先级、作业完成后要通知的用户 ID。
(2) //* 语句 - 这是一个注释语句。
(3) EXEC 语句 - 指定要执行的 PROC/程序。在上面的示例中,正在执行 SORT 程序(即,按特定顺序对输入数据进行排序)
(4) 输入 DD 语句 - 指定要传递给 (3) 中提到的程序的输入类型。在上面的示例中,物理顺序 (PS) 文件以共享模式 (DISP = SHR) 作为输入传递。
(5) 输出 DD 语句 - 指定程序执行后要产生的输出类型。在上面的示例中,创建了一个 PS 文件。如果语句超过一行中的第 70 个位置,则在下一行继续,下一行应以“//”后跟一个或多个空格开头。
(6) 可以有其他类型的 DD 语句来向程序指定其他信息(在上面的示例中:SYSIN DD 语句中指定了排序条件)并指定错误/执行日志的目标(示例:SYSUDUMP/SYSPRINT)。DD 语句可以包含在数据集(大型机文件)中,也可以作为流数据(硬编码在 JCL 中的信息)包含在上面示例中。
(7) /* 标记流数据结束。
除流数据外,所有 JCL 语句都以 // 开头。JOB、EXEC 和 DD 关键字前后至少应有一个空格,其余语句中不应有空格。
JOB 参数类型
每个 JCL 语句都带有一组参数,以帮助操作系统完成程序执行。参数可以分为两种类型
位置参数
出现在语句中预定义的位置和顺序。示例:会计信息参数只能出现在JOB关键字之后,程序员名称参数和关键字参数之前。如果省略位置参数,则必须用逗号替换。
位置参数存在于 JOB 和 EXEC 语句中。在上面的示例中,PGM 是在EXEC关键字之后编码的位置参数。
关键字参数
它们编码在位置参数之后,但可以按任何顺序出现。如果不需要,可以省略关键字参数。通用语法为 KEYWORD= value。示例:MSGCLASS=X,即作业完成后作业日志重定向到输出 SPOOL。
在上面的示例中,CLASS、MSGCLASS 和 NOTIFY 是 JOB 语句的关键字参数。EXEC 语句中也可以有关键字参数。
这些参数将在后续章节中结合相应的示例进行详细说明。
JCL - JOB 语句
JOB 语句是 JCL 中的第一个控制语句。它向操作系统 (OS)、SPOOL 和调度程序提供作业的标识。JOB 语句中的参数帮助操作系统分配正确的调度程序、所需的 CPU 时间并向用户发出通知。
语法
以下是 JCL JOB 语句的基本语法
//Job-name JOB Positional-param, Keyword-param
描述
让我们看看上面 JOB 语句语法中使用的术语的描述。
作业名
在将作业提交到 OS 时,这将为作业提供一个 ID。它的长度可以为 1 到 8 个字母数字字符,并且紧跟在 // 之后。
JOB
这是识别它为 JOB 语句的关键字。
位置参数
有位置参数,可以分为两种类型
| 位置参数 | 描述 |
|---|---|
| 账户信息 | 这指的是拥有 CPU 时间的人或组。它根据拥有大型机的公司的规则进行设置。如果将其指定为 (*),则它采用当前登录到大型机终端的用户 ID。 |
| 程序员姓名 | 这标识负责 JCL 的人员或组。这不是必填参数,可以用逗号替换。 |
关键字参数
以下是可以在 JOB 语句中使用的各种关键字参数。您可以根据需要使用一个或多个参数,并且它们用逗号分隔
| 关键字参数 | 描述 |
|---|---|
| CLASS | 根据作业所需的时间长度和资源数量,公司分配不同的作业类别。这些可以被视为 OS 用于接收作业的单个调度程序。将作业放入正确的调度程序中将有助于轻松执行作业。一些公司在测试和生产环境中为作业设置不同的类别。 CLASS 参数的有效值为 A 到 Z 字符和 0 到 9 数字(长度为 1)。以下是语法 CLASS=0 到 9 | A 到 Z |
| PRTY | 指定作业在作业类别中的优先级。如果未指定此参数,则作业将添加到指定 CLASS 中队列的末尾。以下是语法 PRTY=N 其中 N 是 0 到 15 之间的数字,数字越大,优先级越高。 |
| NOTIFY | 系统将成功或失败消息(最大条件代码)发送到此参数中指定的用户。以下是语法 NOTIFY="userid | &SYSUID" 在这里,系统将消息发送到用户“userid”,但如果我们使用 NOTIFY = &SYSUID,则消息将发送到提交 JCL 的用户。 |
| MSGCLASS | 指定作业完成后系统和作业消息的输出目标。以下是语法 MSGCLASS=CLASS CLASS 的有效值可以是“A”到“Z”和“0”到“9”。可以将 MSGCLASS = Y 设置为一个类别,以将作业日志发送到 JMR(JOBLOG 管理和检索:大型机内用于存储作业统计信息的存储库)。 |
| MSGLEVEL | 指定要写入 MSGCLASS 中指定的输出目标的消息类型。以下是语法 MSGLEVEL=(ST, MSG) ST = 写入输出日志的语句类型
MSG = 写入输出日志的消息类型。
|
| TYPRUN | 指定作业的特殊处理。以下是语法 TYPRUN = SCAN | HOLD 其中 SCAN 和 HOLD 具有以下描述
|
| TIME | 指定处理器执行作业所需的时间跨度。以下是语法 TIME=(mm, ss) 或 TIME=ss 其中 mm = 分钟,ss = 秒 此参数在测试新编写的程序时很有用。为了确保程序不会因循环错误而长时间运行,可以编写时间参数,以便在达到指定的 CPU 时间时程序异常终止。 |
| REGION | 指定作业内作业步骤运行所需的地址空间。以下是语法 REGION=nK | nM 这里,region 可以指定为 nK 或 nM,其中 n 是一个数字,K 是千字节,M 是兆字节。 当 REGION = 0K 或 0M 时,将提供最大的地址空间进行执行。在关键应用程序中,禁止编码 0K 或 0M 以避免浪费地址空间。 |
示例
//URMISAMP JOB (*),"tutpoint",CLASS=6,PRTY=10,NOTIFY=&SYSUID, // MSGCLASS=X,MSGLEVEL=(1,1),TYPRUN=SCAN, // TIME=(3,0),REGION=10K
这里,JOB 语句在一行中扩展到第 70 位之后,因此我们在下一行继续,下一行应以“//”后跟一个或多个空格开头。
其他参数
还有其他一些参数可以与 JOB 语句一起使用,但它们不常使用
| ADDRSPC | 使用的存储类型:虚拟或真实 |
| BYTES | 要写入输出日志的数据大小以及超过该大小时要采取的操作。 |
| LINES | 要打印到输出日志的最大行数。 |
| PAGES | 要打印到输出日志的最大页数。 |
| USER | 用于提交作业的用户 ID。 |
| PASSWORD | USER 参数中指定的用户 ID 的密码。 |
| COND 和 RESTART | 这些用于条件作业步骤处理,在讨论条件处理时将详细解释。 |
JCL - EXEC 语句
每个 JCL 可以由许多作业步骤组成。每个作业步骤可以直接执行程序或调用过程,该过程依次执行一个或多个程序(作业步骤)。包含作业步骤程序/过程信息的语句是EXEC 语句。
EXEC 语句的目的是为在作业步骤中执行的程序/过程提供必要的信息。在此语句中编码的参数可以将数据传递给正在执行的程序,可以覆盖 JOB 语句的某些参数,并且如果 EXEC 语句调用过程而不是直接执行程序,则可以将参数传递给该过程。
语法
以下是 JCL EXEC 语句的基本语法
//Step-name EXEC Positional-param, Keyword-param
描述
让我们看看上面 EXEC 语句语法中使用的术语的描述。
STEP-NAME
这标识 JCL 中的作业步骤。它可以是长度为 1 到 8 的字母数字字符。
EXEC
这是识别它是 EXEC 语句的关键字。
POSITIONAL-PARAM
这些是位置参数,可以分为两种类型
| 位置参数 | 描述 |
|---|---|
| PGM | 这指的是要在作业步骤中执行的程序名称。 |
| PROC | 这指的是要在作业步骤中执行的过程名称。我们将在单独的章节中讨论它。 |
KEYWORD-PARAM
以下是 EXEC 语句的各种关键字参数。您可以根据需要使用一个或多个参数,并且它们用逗号分隔
| 关键字参数 | 描述 |
|---|---|
| PARM | 用于向作业步骤中正在执行的程序提供参数化数据。这是一个程序相关的字段,没有明确的规则,除非 PARM 值在包含特殊字符的情况下必须包含在引号中。 例如,以下给出的值“CUST1000”作为字母数字值传递给程序。如果程序在 COBOL 中,则通过 JCL 中的 PARM 参数传递的值将在程序的 LINKAGE SECTION 中接收。 |
| ADDRSPC | 这用于指定作业步骤是否需要虚拟或真实存储来执行。虚拟存储是可分页的,而真实存储不可分页,并且放置在主内存中以供执行。需要更快执行的作业步骤可以放置在真实存储中。以下是语法 ADDRSPC=VIRT | REAL 当未编码 ADDRSPC 时,VIRT 是默认值。 |
| ACCT | 这指定作业步骤的会计信息。以下是语法 ACCT=(userid) 这类似于 JOB 语句中的位置参数会计信息。如果它在 JOB 和 EXEC 语句中都进行了编码,则 JOB 语句中的会计信息将应用于所有未编码 ACCT 参数的作业步骤。EXEC 语句中的 ACCT 参数将仅覆盖该作业步骤中存在的 JOB 语句中的参数。 |
EXEC 和 JOB 语句的常用关键字参数
| 关键字参数 | 描述 |
|---|---|
| ADDRSPC | JOB 语句中编码的 ADDRSPC 覆盖任何作业步骤的 EXEC 语句中编码的 ADDRSPC。 |
| TIME | 如果在 EXEC 语句中编码了 TIME,则它仅适用于该作业步骤。如果它在 JOB 和 EXEC 语句中都指定,则两者都将生效,并且可能由于其中任何一个导致超时错误。不建议同时在 JOB 和 EXEC 语句中一起使用 TIME 参数。 |
| REGION | 如果在 EXEC 语句中编码了 REGION,则它仅适用于该作业步骤。 JOB 语句中编码的 REGION 覆盖任何作业步骤的 EXEC 语句中编码的 REGION。 |
| COND | 用于根据上一步的返回码控制作业步骤的执行。 如果在作业步骤的 EXEC 语句中编码了 COND 参数,则忽略 JOB 语句(如果存在)的 COND 参数。可以使用 COND 参数执行的各种测试将在条件处理中解释。 |
示例
以下是一个简单的 JCL 脚本示例,以及 JOB 和 EXEC 语句
//TTYYSAMP JOB 'TUTO',CLASS=6,MSGCLASS=X,REGION=8K, // NOTIFY=&SYSUID //* //STEP010 EXEC PGM=MYCOBOL,PARAM=CUST1000, // ACCT=(XXXX),REGION=8K,ADDRSPC=REAL,TIME=1440
JCL - DD 语句
数据集是具有以特定格式组织的记录的主机文件。数据集存储在主机系统的直接访问存储设备 (DASD) 或磁带上,并且是基本的数据存储区域。如果需要在批处理程序中使用/创建这些数据,则文件(即数据集)物理名称以及文件格式和组织将在 JCL 中进行编码。
使用DD 语句给出 JCL 中使用的每个数据集的定义。作业步骤所需的输入和输出资源需要在 DD 语句中进行描述,其中包含数据集组织、存储需求和记录长度等信息。
语法
以下是 JCL DD 语句的基本语法
//DD-name DD Parameters
描述
让我们看看上面 DD 语句语法中使用的术语的描述。
DD-NAME
DD-NAME 标识数据集或输入/输出资源。如果这是 COBOL/汇编程序使用的输入/输出文件,则程序在程序中引用该文件。
DD
这是识别它是 DD 语句的关键字。
PARAMETERS
以下是 DD 语句的各种参数。您可以根据需要使用一个或多个参数,并且它们用逗号分隔
| 参数 | 描述 |
|---|---|
| DSN | DSN 参数指的是新创建或现有数据集的物理数据集名称。DSN 值可以由每个长度为 1 到 8 个字符的子名称组成,用句点分隔,总长度为 44 个字符(字母数字)。以下是语法 DSN=物理数据集名称 临时数据集仅在作业持续时间内需要存储,并在作业完成时删除。此类数据集表示为DSN=&name或根本不指定 DSN。 如果作业步骤创建的临时数据集要在下一个作业步骤中使用,则将其引用为DSN=*.stepname.ddname。这称为后向引用。 |
| DISP | DISP 参数用于描述数据集的状态,以及在作业步骤正常和异常完成时结束时的处理方式。仅当数据集在同一作业步骤中创建和删除(如临时数据集)时,DD 语句中不需要 DISP。以下是语法 DISP=(status, normal-disposition, abnormal-disposition) 以下是status的有效值
normal-disposition参数可以取以下值之一
abnormal-disposition参数可以取以下值之一
以下是 CATLG、UNCATLG、DELETE、PASS 和 KEEP 参数的描述
当 DISP 的任何子参数未指定时,默认值如下所示
|
| DCB | 数据控制块 (DCB) 参数详细说明了数据集的物理特征。此参数对于在作业步骤中新创建的数据集是必需的。 LRECL 是数据集内每个记录的长度。 RECFM 是数据集的记录格式。RECFM 可以保存 FB、V 或 VB 值。FB 是固定块组织,其中一个或多个逻辑记录分组在一个块内。V 是可变组织,其中一个可变长度的逻辑记录放置在一个物理块内。VB 是可变块组织,其中一个或多个可变长度的逻辑记录放置在一个物理块内。 BLKSIZE 是物理块的大小。块越大,FB 或 VB 文件的记录数量就越多。 DSORG 是数据集组织的类型。DSORG 可以保存 PS(物理顺序)、PO(分区组织)和 DA(直接组织)值。 当需要将一个数据集的 DCB 值复制到同一作业步骤或 JCL 中的另一个数据集时,则将其指定为 DCB=*.stepname.ddname,其中 stepname 是作业步骤的名称,ddname 是复制 DCB 的数据集。 请查看以下示例,其中 RECFM=FB、LRECL=80 构成数据集 OUTPUT1 的 DCB。 |
| SPACE | SPACE 参数指定数据集在 DASD(直接访问存储磁盘)中所需的存储空间。以下是语法 SPACE=(spcunits, (pri, sec, dir), RLSE) 以下是所有使用参数的说明
|
| UNIT | UNIT 和 VOL 参数列在系统目录中以供编目数据集使用,因此只需使用物理 DSN 名称即可访问它们。但是对于未编目的数据集,DD 语句应包含这些参数。对于要创建的新数据集,可以指定 UNIT/VOL 参数,或者 Z/OS 分配合适的设备和卷。 UNIT 参数指定存储数据集的设备类型。可以使用硬件地址或设备类型组识别设备类型。以下是语法 UNIT=DASD | SYSDA 其中 DASD 代表直接访问存储设备,SYSDA 代表系统直接访问,并指下一个可用的磁盘存储设备。 |
| VOL | VOL 参数指定由 UNIT 参数标识的设备上的卷号。以下是语法 VOL=SER=(v1,v2) 其中 v1、v2 是卷序列号。您也可以使用以下语法 VOL=REF=*.DDNAME 其中 REF 是对 JCL 中任何先前作业步骤中的数据集的卷序列号的反向引用。 |
| SYSOUT | 到目前为止讨论的 DD 语句参数对应于存储在数据集中的数据。SYSOUT 参数根据指定的类将数据定向到输出设备。以下是语法 SYSOUT=class 其中,如果 class 为 A,则将其输出定向到打印机,如果 class 为 *,则将其输出定向到与 JOB 语句中的 MSGCLASS 参数相同的目标。 |
示例
以下是一个示例,它使用 DD 语句以及上面解释的各种参数
//TTYYSAMP JOB 'TUTO',CLASS=6,MSGCLASS=X,REGION=8K, // NOTIFY=&SYSUID //* //STEP010 EXEC PGM=ICETOOL,ADDRSPC=REAL //* //INPUT1 DD DSN=TUTO.SORT.INPUT1,DISP=SHR //INPUT2 DD DSN=TUTO.SORT.INPUT2,DISP=SHR,UNIT=SYSDA, // VOL=SER=(1243,1244) //OUTPUT1 DD DSN=MYFILES.SAMPLE.OUTPUT1,DISP=(,CATLG,DELETE), // RECFM=FB,LRECL=80,SPACE=(CYL,(10,20)) //OUTPUT2 DD SYSOUT=*
JCL - 基本库
基本库是分区数据集 (PDS),它保存要在 JCL 中执行的程序的加载模块或在程序中调用的编目过程。基本库可以在整个 JCL 中的 JOBLIB 库中指定,或者在特定作业步骤的 STEPLIB 语句中指定。
JOBLIB 语句
JOBLIB 语句用于识别要在 JCL 中执行的程序的位置。JOBLIB 语句在 JOB 语句之后和 EXEC 语句之前指定。这只能用于流内过程和程序。
语法
以下是 JCL JOBLIB 语句的基本语法
//JOBLIB DD DSN=dsnname,DISP=SHR
JOBLIB 语句适用于 JCL 中的所有 EXEC 语句。EXEC 语句中指定的程序将在 JOBLIB 库中搜索,然后在系统库中搜索。
例如,如果 EXEC 语句正在执行 COBOL 程序,则 COBOL 程序的加载模块应放置在 JOBLIB 库中。
STEPLIB 语句
STEPLIB 语句用于识别要在作业步骤内执行的程序的位置。STEPLIB 语句在 EXEC 语句之后和作业步骤的 DD 语句之前指定。
语法
以下是 JCL STEPLIB 语句的基本语法
//STEPLIB DD DSN=dsnname,DISP=SHR
EXEC 语句中指定的程序将在 STEPLIB 库中搜索,然后在系统库中搜索。在作业步骤中编码的 STEPLIB 覆盖 JOBLIB 语句。
示例
以下示例显示了 JOBLIB 和 STEPLIB 语句的用法
//MYJCL JOB ,,CLASS=6,NOTIFY=&SYSUID //* //JOBLIB DD DSN=MYPROC.BASE.LIB1,DISP=SHR //* //STEP1 EXEC PGM=MYPROG1 //INPUT1 DD DSN=MYFILE.SAMPLE.INPUT1,DISP=SHR //OUTPUT1 DD DSN=MYFILES.SAMPLE.OUTPUT1,DISP=(,CATLG,DELETE), // RECFM=FB,LRECL=80 //* //STEP2 EXEC PGM=MYPROG2 //STEPLIB DD DSN=MYPROC.BASE.LIB2,DISP=SHR //INPUT2 DD DSN=MYFILE.SAMPLE.INPUT2,DISP=SHR //OUTPUT2 DD DSN=MYFILES.SAMPLE.OUTPUT2,DISP=(,CATLG,DELETE), // RECFM=FB,LRECL=80
此处,程序 MYPROG1(在 STEP1 中)的加载模块在 MYPROC.SAMPLE.LIB1 中搜索。如果未找到,则在系统库中搜索。在 STEP2 中,STEPLIB 覆盖 JOBLIB,程序 MYPROG2 的加载模块在 MYPROC.SAMPLE.LIB2 中搜索,然后在系统库中搜索。
INCLUDE 语句
使用 INCLUDE 语句可以将编码在 PDS 成员中的 JCL 语句集包含到 JCL 中。当 JES 解释 JCL 时,INCLUDE 成员中的 JCL 语句集将替换 INCLUDE 语句。
语法
以下是 JCL INCLUDE 语句的基本语法
//name INCLUDE MEMBER=member-name
INCLUDE 语句的主要目的是可重用性。例如,要在许多 JCL 中使用的公共文件可以作为 DD 语句编码在 INCLUDE 成员中,并在 JCL 中使用。
虚拟 DD 语句、数据卡规范、PROC、JOB、PROC 语句不能编码在 INCLUDE 成员中。INCLUDE 语句可以编码在 INCLUDE 成员中,并且可以进一步嵌套最多 15 层。
JCLLIB 语句
JCLLIB 语句用于识别作业中使用的私有库。它可以与流内过程和编目过程一起使用。
语法
以下是 JCL JCLLIB 语句的基本语法
//name JCLLIB ORDER=(library1, library2....)
JCLLIB 语句中指定的库将按给定顺序搜索,以找到作业中使用的程序、过程和 INCLUDE 成员。JCL 中只能有一个 JCLLIB 语句;在 JOB 语句之后和 EXEC 和 INCLUDE 语句之前指定,但不能在 INCLUDE 成员中编码。
示例
在以下示例中,程序 MYPROG3 和 INCLUDE 成员 MYINCL 按 MYPROC.BASE.LIB1、MYPROC.BASE.LIB2、系统库的顺序搜索。
//MYJCL JOB ,,CLASS=6,NOTIFY=&SYSUID //* //MYLIB JCLLIB ORDER=(MYPROC.BASE.LIB1,MYPROC.BASE.LIB2) //* //STEP1 EXEC PGM=MYPROG3 //INC INCLUDE MEMBER=MYINCL //OUTPUT1 DD DSN=MYFILES.SAMPLE.OUTPUT1,DISP=(,CATLG,DELETE), // RECFM=FB,LRECL=80 //*
JCL - 过程
JCL 过程是 JCL 内的一组语句,它们组合在一起以执行特定功能。通常,JCL 的固定部分编码在过程中。作业的可变部分编码在 JCL 中。
您可以使用过程来实现使用多个输入文件的程序的并行执行。可以为每个输入文件创建一个 JCL,并且可以通过将输入文件名作为符号参数传递来同时调用单个过程。
语法
以下是 JCL 过程定义的基本语法
//* //Step-name EXEC procedure name
对于流内过程,过程的内容保存在 JCL 中。对于编目过程,内容保存在基本库的不同成员中。本章将解释 JCL 中可用的两种过程类型,然后我们将了解如何嵌套各种过程。
流内过程
当过程编码在同一 JCL 成员中时,称为流内过程。它应以 PROC 语句开头,以 PEND 语句结尾。
//SAMPINST JOB 1,CLASS=6,MSGCLASS=Y,NOTIFY=&SYSUID //* //INSTPROC PROC //*START OF PROCEDURE //PROC1 EXEC PGM=SORT //SORTIN DD DSN=&DSNAME,DISP=SHR //SORTOUT DD SYSOUT=*MYINCL //SYSOUT DD SYSOUT=* //SYSIN DD DSN=&DATAC LRECL=80 // PEND //*END OF PROCEDURE //* //STEP1 EXEC INSTPROC,DSNME=MYDATA.URMI.INPUT1, // DATAC=MYDATA.BASE.LIB1(DATA1) //* //STEP2 EXEC INSTPROC,DSNME=MYDATA.URMI.INPUT2 // DATAC=MYDATA.BASE.LIB1(DATA1) //*
在上面的示例中,过程 INSTPROC 在 STEP1 和 STEP2 中使用不同的输入文件调用。参数 DSNAME 和 DATAC 可以使用不同的值进行编码,并在调用过程时使用,这些称为 符号参数。JCL 的可变输入(如文件名、数据卡、PARM 值等)作为符号参数传递给过程。
在编码符号参数时,不要使用 KEYWORDS、PARAMETERS 或 SUB-PARAMETERS 作为符号名称。例如:不要使用 TIME=&TIME,但可以使用 TIME=&TM,并且假定这是正确的符号编码方式。
用户定义的符号参数称为 JCL 符号。有一些称为 系统符号的符号,用于登录作业执行。普通用户在批处理作业中使用的唯一系统符号是 &SYSUID,它用于 JOB 语句中的 NOTIFY 参数。
编目过程
当过程与 JCL 分开并编码在不同的数据存储中时,称为 编目过程。编目过程中不需要强制编码 PROC 语句。以下是在 JCL 中调用 CATLPROC 过程的示例
//SAMPINST JOB 1,CLASS=6,MSGCLASS=Y,NOTIFY=&SYSUID //* //STEP EXEC CATLPROC,PROG=CATPRC1,DSNME=MYDATA.URMI.INPUT // DATAC=MYDATA.BASE.LIB1(DATA1)
此处,过程 CATLPROC 编目在 MYCOBOL.BASE.LIB1 中。PROG、DATAC 和 DSNAME 作为符号参数传递给过程 CATLPROC。
//CATLPROC PROC PROG=,BASELB=MYCOBOL.BASE.LIB1 //* //PROC1 EXEC PGM=&PROG //STEPLIB DD DSN=&BASELB,DISP=SHR //IN1 DD DSN=&DSNAME,DISP=SHR //OUT1 DD SYSOUT=* //SYSOUT DD SYSOUT=* //SYSIN DD DSN=&DATAC //*
在过程中,编码了符号参数 PROG 和 BASELB。请注意,过程中的 PROG 参数被 JCL 中的值覆盖,因此 PGM 在执行期间取值为 CATPRC1。
嵌套过程
从过程内部调用过程称为 嵌套过程。过程可以嵌套最多 15 层。嵌套可以完全是流内的或编目的。我们不能在编目过程中编码流内过程。
//SAMPINST JOB 1,CLASS=6,MSGCLASS=Y,NOTIFY=&SYSUID //* //SETNM SET DSNM1=INPUT1,DSNM2=OUTPUT1 //INSTPRC1 PROC //* START OF PROCEDURE 1 //STEP1 EXEC PGM=SORT,DISP=SHR //SORTIN DD DSN=&DSNM1,DISP=SHR //SORTOUT DD DSN=&DSNM2,DISP=(,PASS) //SYSOUT DD SYSOUT=* //SYSIN DD DSN=&DATAC //* //STEP2 EXEC PROC=INSTPRC2,DSNM2=MYDATA.URMI.OUTPUT2 // PEND //* END OF PROCEDURE 1 //* //INSTPRC2 PROC //* START OF PROCEDURE 2 //STEP1 EXEC PGM=SORT //SORTIN DD DSN=*.INSTPRC1.STEP1.SORTOUT //SORTOUT DD DSN=&DSNM2,DISP=OLD //SYSOUT DD SYSOUT=* //SYSIN DD DSN=&DATAC // PEND //* END OF PROCEDURE 2 //* //JSTEP1 EXEC INSTPRC1,DSNM1=MYDATA.URMI.INPUT1, // DATAC=MYDATA.BASE.LIB1(DATA1) //*
在上面的示例中,JCL 在 JSTEP1 中调用过程 INSTPRC1,过程 INSTPRC2 在过程 INSTPRC1 中被调用。此处,INSTPRC1 的输出 (SORTOUT) 作为输入 (SORTIN) 传递给 INSTPRC2。
SET 语句用于在作业步骤或过程之间定义常用符号。它初始化符号名称中的先前值。它必须在 JCL 中首次使用符号名称之前定义。
让我们看一下下面的描述,以便更多地了解上述程序。
SET 参数初始化 DSNM1=INPUT1 和 DSNM2=OUTPUT1。
当在 JCL 的 JSTEP1 中调用 INSTPRC1 时,DSNM1=MYDATA.URMI.INPUT1 且 DSNM2=OUTPUT1.,即 SET 语句中初始化的值将重置为在任何作业步骤/过程中设置的值。
当在 INSTPRC1 的 STEP2 中调用 INSTPRC2 时,DSNM1=MYDATA.URMI.INPUT1 且 DSNM2=MYDATA.URMI.OUTPUT2。
JCL - 条件处理
作业输入系统使用两种方法在 JCL 中执行条件处理。作业完成后,会根据执行状态设置返回码。返回码可以是 0(执行成功)到 4095(非零表示错误条件)之间的数字。最常见的常规值是
0 = 正常 - 一切正常
4 = 警告 - 次要错误或问题。
8 = 错误 - 严重错误或问题。
12 = 严重错误 - 重大错误或问题,结果不可信。
16 = 终止错误 - 非常严重的问题,请勿使用结果。
可以使用COND参数和IF-THEN-ELSE结构控制作业步骤的执行,该结构基于前一步/步骤的返回码,本教程已对此进行了说明。
COND 参数
COND参数可以在 JCL 的 JOB 或 EXEC 语句中编码。它对前面作业步骤的返回码进行测试。如果测试结果为真,则当前作业步骤的执行将被绕过。绕过只是省略作业步骤,而不是异常终止。单个测试中最多可以组合八个条件。
语法
以下是 JCL COND 参数的基本语法
COND=(rc,logical-operator) or COND=(rc,logical-operator,stepname) or COND=EVEN or COND=ONLY
以下是所用参数的描述
rc:这是返回码
逻辑运算符:可以是 GT(大于)、GE(大于或等于)、EQ(等于)、LT(小于)、LE(小于或等于)或 NE(不等于)。
stepname:这是用于测试的作业步骤的返回码。
最后两个条件 (a) COND=EVEN 和 (b) COND=ONLY 已在本教程后面进行了说明。
COND 可以编码在 JOB 语句或 EXEC 语句中,并且在这两种情况下,其行为都不同,如下所述
JOB 语句中的 COND
当 COND 编码在 JOB 语句中时,会对每个作业步骤进行条件测试。当在任何特定作业步骤中条件为真时,它将被绕过,以及随后的作业步骤。以下是一个示例
//CNDSAMP JOB CLASS=6,NOTIFY=&SYSUID,COND=(5,LE) //* //STEP10 EXEC PGM=FIRSTP //* STEP10 executes without any test being performed. //STEP20 EXEC PGM=SECONDP //* STEP20 is bypassed, if RC of STEP10 is 5 or above. //* Say STEP10 ends with RC4 and hence test is false. //* So STEP20 executes and lets say it ends with RC16. //STEP30 EXEC PGM=SORT //* STEP30 is bypassed since 5 <= 16.
EXEC 语句中的 COND
当 COND 编码在作业步骤的 EXEC 语句中并发现为真时,只会绕过该作业步骤,并且从下一个作业步骤继续执行。
//CNDSAMP JOB CLASS=6,NOTIFY=&SYSUID //* //STP01 EXEC PGM=SORT //* Assuming STP01 ends with RC0. //STP02 EXEC PGM=MYCOBB,COND=(0,EQ,STP01) //* In STP02, condition evaluates to TRUE and step bypassed. //STP03 EXEC PGM=IEBGENER,COND=((10,LT,STP01),(10,GT,STP02)) //* In STP03, first condition fails and hence STP03 executes. //* Since STP02 is bypassed, the condition (10,GT,STP02) in //* STP03 is not tested.
COND=EVEN
当编码 COND=EVEN 时,即使任何先前的步骤异常终止,当前作业步骤也会执行。如果与 COND=EVEN 一起编码了任何其他 RC 条件,则如果没有任何 RC 条件为真,则作业步骤将执行。
//CNDSAMP JOB CLASS=6,NOTIFY=&SYSUID //* //STP01 EXEC PGM=SORT //* Assuming STP01 ends with RC0. //STP02 EXEC PGM=MYCOBB,COND=(0,EQ,STP01) //* In STP02, condition evaluates to TRUE and step bypassed. //STP03 EXEC PGM=IEBGENER,COND=((10,LT,STP01),EVEN) //* In STP03, condition (10,LT,STP01) evaluates to true, //* hence the step is bypassed.
COND=ONLY
当编码 COND=ONLY 时,只有当任何先前的步骤异常终止时,才会执行当前作业步骤。如果与 COND=ONLY 一起编码了任何其他 RC 条件,则如果没有任何 RC 条件为真并且任何先前的作业步骤异常失败,则作业步骤将执行。
//CNDSAMP JOB CLASS=6,NOTIFY=&SYSUID //* //STP01 EXEC PGM=SORT //* Assuming STP01 ends with RC0. //STP02 EXEC PGM=MYCOBB,COND=(4,EQ,STP01) //* In STP02, condition evaluates to FALSE, step is executed //* and assume the step abends. //STP03 EXEC PGM=IEBGENER,COND=((0,EQ,STP01),ONLY) //* In STP03, though the STP02 abends, the condition //* (0,EQ,STP01) is met. Hence STP03 is bypassed.
IF-THEN-ELSE 结构
控制作业处理的另一种方法是使用 IF-THEN-ELSE 结构。这提供了更灵活且用户友好的条件处理方式。
语法
以下是 JCL IF-THEN-ELSE 结构的基本语法
//name IF condition THEN list of statements //* action to be taken when condition is true //name ELSE list of statements //* action to be taken when condition is false //name ENDIF
以下是上述 IF-THEN-ELSE 结构中所用术语的描述
name:这是可选的,名称可以有 1 到 8 个字母数字字符,以字母、#、$ 或 @ 开头。
Condition:条件将具有以下格式:KEYWORD OPERATOR VALUE,其中KEYWORDS可以是 RC(返回码)、ABENDCC(系统或用户完成码)、ABEND、RUN(步骤已开始执行)。OPERATOR可以是逻辑运算符(AND(&)、OR(|))或关系运算符(<、<=、>、>=、<>)。
示例
以下是一个简单的示例,显示了 IF-THEN-ELSE 的用法
//CNDSAMP JOB CLASS=6,NOTIFY=&SYSUID //* //PRC1 PROC //PST1 EXEC PGM=SORT //PST2 EXEC PGM=IEBGENER // PEND //STP01 EXEC PGM=SORT //IF1 IF STP01.RC = 0 THEN //STP02 EXEC PGM=MYCOBB1,PARM=123 // ENDIF //IF2 IF STP01.RUN THEN //STP03a EXEC PGM=IEBGENER //STP03b EXEC PGM=SORT // ENDIF //IF3 IF STP03b.!ABEND THEN //STP04 EXEC PGM=MYCOBB1,PARM=456 // ELSE // ENDIF //IF4 IF (STP01.RC = 0 & STP02.RC <= 4) THEN //STP05 EXEC PROC=PRC1 // ENDIF //IF5 IF STP05.PRC1.PST1.ABEND THEN //STP06 EXEC PGM=MYABD // ELSE //STP07 EXEC PGM=SORT // ENDIF
让我们尝试深入研究上述程序,以便更详细地了解它。
在 IF1 中测试 STP01 的返回码。如果为 0,则执行 STP02。否则,处理转到下一个 IF 语句 (IF2)。
在 IF2 中,如果 STP01 已开始执行,则执行 STP03a 和 STP03b。
在 IF3 中,如果 STP03b 没有 ABEND,则执行 STP04。在 ELSE 中,没有语句。这称为 NULL ELSE 语句。
在 IF4 中,如果 STP01.RC = 0 且 STP02.RC <=4 为真,则执行 STP05。
在 IF5 中,如果作业步骤 STP05 中 PRC1 中的 proc-step PST1 ABEND,则执行 STP06。否则执行 STP07。
如果 IF4 评估为假,则不会执行 STP05。在这种情况下,不会测试 IF5,并且不会执行步骤 STP06、STP07。
在作业异常终止的情况下(例如用户取消作业、作业时间到期或数据集向后引用被绕过的步骤),IF-THEN-ELSE 不会执行。
设置检查点
您可以使用SYSCKEOV(这是一个 DD 语句)在 JCL 程序中设置检查点数据集。
CHKPT是在 DD 语句中为多卷 QSAM 数据集编码的参数。当 CHKPT 编码为 CHKPT=EOV 时,在每个输入/输出多卷数据集卷的末尾将检查点写入 SYSCKEOV 语句中指定的数据集中。
//CHKSAMP JOB CLASS=6,NOTIFY=&SYSUID //* //STP01 EXEC PGM=MYCOBB //SYSCKEOV DD DSNAME=SAMPLE.CHK,DISP=MOD //IN1 DD DSN=SAMPLE.IN,DISP=SHR //OUT1 DD DSN=SAMPLE.OUT,DISP=(,CATLG,CATLG) // CHKPT=EOV,LRECL=80,RECFM=FB
在上面的示例中,在输出数据集 SAMPLE.OUT 的每个卷的末尾,都会在数据集 SAMPLE.CHK 中写入一个检查点。
重新启动处理
您可以使用RD 参数通过自动方式或使用RESTART 参数通过手动方式重新启动处理。
RD 参数编码在 JOB 或 EXEC 语句中,它有助于自动重新启动 JOB/STEP,并且可以保存四个值之一:R、RNC、NR 或 NC。
RD=R允许自动重新启动,并考虑 DD 语句的 CHKPT 参数中编码的检查点。
RD=RNC允许自动重新启动,但会覆盖(忽略)CHKPT 参数。
RD=NR指定作业/步骤不能自动重新启动。但是,当使用 RESTART 参数手动重新启动时,将考虑 CHKPT 参数(如果有)。
RD=NC不允许自动重新启动和检查点处理。
如果需要仅针对特定异常结束代码执行自动重新启动,则可以在 IBM 系统 parmlib 库的SCHEDxx成员中指定。
RESTART 参数编码在 JOB 或 EXEC 语句中,它有助于在作业失败后手动重新启动 JOB/STEP。RESTART 可以与检查 ID 结合使用,检查 ID 是在 SYSCKEOV DD 语句中编码的数据集中写入的检查点。当编码检查 ID 时,应编码 SYSCHK DD 语句以引用 JOBLIB 语句(如果有)之后的检查点数据集,否则在 JOB 语句之后引用。
//CHKSAMP JOB CLASS=6,NOTIFY=&SYSUID,RESTART=(STP01,chk5) //* //SYSCHK DD DSN=SAMPLE.CHK,DISP=OLD //STP01 EXEC PGM=MYCOBB //*SYSCKEOV DD DSNAME=SAMPLE.CHK,DISP=MOD //IN1 DD DSN=SAMPLE.IN,DISP=SHR //OUT1 DD DSN=SAMPLE.OUT,DISP=(,CATLG,CATLG) // CHKPT=EOV,LRECL=80,RECFM=FB
在上面的示例中,chk5 是检查 ID,即 STP01 从检查点 5 重新启动。请注意,已添加 SYSCHK 语句,并且在“设置检查点”部分中解释的先前程序中已注释掉 SYSCKEOV 语句。
JCL - 定义数据集
数据集名称指定文件名称,并在 JCL 中用 DSN 表示。DSN 参数指的是新创建或现有数据集的物理数据集名称。DSN 值可以由每个长度为 1 到 8 个字符的子名称组成,用句点分隔,总长度为 44 个字符(字母数字)。以下是语法
DSN=&name | *.stepname.ddname
临时数据集仅在作业持续时间内需要存储空间,并在作业完成后删除。此类数据集表示为DSN=&name或根本没有指定 DSN。
如果作业步骤创建的临时数据集要在下一个作业步骤中使用,则将其引用为DSN=*.stepname.ddname。这称为向后引用。
连接数据集
如果有多个相同格式的数据集,则可以将它们连接起来,并作为单个 DD 名称传递给程序作为输入。
//CONCATEX JOB CLASS=6,NOTIFY=&SYSUID //* //STEP10 EXEC PGM=SORT //SORTIN DD DSN=SAMPLE.INPUT1,DISP=SHR // DD DSN=SAMPLE.INPUT2,DISP=SHR // DD DSN=SAMPLE.INPUT3,DISP=SHR //SORTOUT DD DSN=SAMPLE.OUTPUT,DISP=(,CATLG,DELETE), // LRECL=50,RECFM=FB
在上面的示例中,将三个数据集连接起来,并作为输入传递给 SORTIN DD 名称中的 SORT 程序。文件将被合并,根据指定的键字段排序,然后写入 SORTOUT DD 名称中的单个输出文件 SAMPLE.OUTPUT。
覆盖数据集
在标准化的 JCL 中,要执行的程序及其相关数据集将放置在已编目过程中,该过程在 JCL 中被调用。通常,出于测试目的或为了解决事件修复,可能需要使用与已编目过程中指定的数据集不同的数据集。在这种情况下,可以在 JCL 中覆盖过程中的数据集。
//SAMPINST JOB 1,CLASS=6,MSGCLASS=Y,NOTIFY=&SYSUID //* //JSTEP1 EXEC CATLPROC,PROG=CATPRC1,DSNME=MYDATA.URMI.INPUT // DATAC=MYDATA.BASE.LIB1(DATA1) //STEP1.IN1 DD DSN=MYDATA.OVER.INPUT,DISP=SHR //* //* The cataloged procedure is as below: //* //CATLPROC PROC PROG=,BASELB=MYCOBOL.BASE.LIB1 //* //STEP1 EXEC PGM=&PROG //STEPLIB DD DSN=&BASELB,DISP=SHR //IN1 DD DSN=MYDATA.URMI.INPUT,DISP=SHR //OUT1 DD SYSOUT=* //SYSOUT DD SYSOUT=* //SYSIN DD MYDATA.BASE.LIB1(DATA1),DISP=SHR //* //STEP2 EXEC PGM=SORT
在上面的示例中,数据集 IN1 在 PROC 中使用文件 MYDATA.URMI.INPUT,该文件在 JCL 中被覆盖。因此,执行中使用的输入文件为 MYDATA.OVER.INPUT。请注意,数据集称为 STEP1.IN1。如果 JCL/PROC 中只有一个步骤,则可以使用 DD 名称引用数据集。类似地,如果 JCL 中有多个步骤,则数据集需要覆盖为 JSTEP1.STEP1.IN1。
//SAMPINST JOB 1,CLASS=6,MSGCLASS=Y,NOTIFY=&SYSUID //* //STEP EXEC CATLPROC,PROG=CATPRC1,DSNME=MYDATA.URMI.INPUT // DATAC=MYDATA.BASE.LIB1(DATA1) //STEP1.IN1 DD DSN=MYDATA.OVER.INPUT,DISP=SHR // DD DUMMY // DD DUMMY //*
在上面的示例中,在 IN1 中连接的三个数据集中,第一个在 JCL 中被覆盖,其余保留为 PROC 中存在的数据集。
在 JCL 中定义 GDG
生成数据组 (GDG) 是由一个通用名称关联的一组数据集。通用名称称为 GDG 基名称,与基名称关联的每个数据集称为 GDG 版本。
例如,MYDATA.URMI.SAMPLE.GDG 是 GDG 基名称。数据集的名称为 MYDATA.URMI.SAMPLE.GDG.G0001V00、MYDATA.URMI.SAMPLE.GDG.G0002V00 等。GDG 的最新版本称为 MYDATA.URMI.SAMPLE.GDG(0),先前版本称为 (-1)、(-2) 等。在程序中要创建的下一个版本在 JCL 中称为 MYDATA.URMI.SAMPLE.GDG(+1)。
在 JCL 中创建/更改 GDG
GDG 版本可以具有相同或不同的 DCB 参数。可以定义一个初始模型 DCB 供所有版本使用,但在创建新版本时可以覆盖它。
//GDGSTEP1 EXEC PGM=IDCAMS
//SYSPRINT DD SYSOUT=*
//SYSIN DD *
DEFINE GDG(NAME(MYDATA.URMI.SAMPLE.GDG) -
LIMIT(7) -
NOEMPTY -
SCRATCH)
/*
//GDGSTEP2 EXEC PGM=IEFBR14
//GDGMODLD DD DSN=MYDATA.URMI.SAMPLE.GDG,
// DISP=(NEW,CATLG,DELETE),
// UNIT=SYSDA,
// SPACE=(CYL,10,20),
// DCB=(LRECL=50,RECFM=FB)
//
在上面的示例中,IDCAMS 实用程序在 GDGSTEP1 中定义了 GDG 基名称,并在 SYSIN DD 语句中传递了以下参数
NAME指定 GDG 基名称的物理数据集名称。
LIMIT指定 GDG 基名称可以保存的最大版本数。
EMPTY在达到 LIMIT 时取消编目所有世代。
NOEMPTY取消编目最近的世代。
SCRATCH在取消编目时物理删除世代。
NOSCRATCH不删除数据集,即可以使用 UNIT 和 VOL 参数引用它。
在 GDGSTEP2 中,IEFBR14 实用程序指定所有版本要使用的模型 DD 参数。
可以使用 IDCAMS 更改 GDG 的定义参数,例如增加 LIMIT、将 EMPTY 更改为 NOEMPTY 等,以及使用 SYSIN 命令更改其相关版本,例如 **ALTER MYDATA.URMI.SAMPLE.GDG LIMIT(15) EMPTY**。
在 JCL 中删除 GDG
使用 IEFBR14 实用程序,我们可以删除 GDG 的单个版本。
//GDGSTEP3 EXEC PGM=IEFBR14 //GDGDEL DD DSN=MYDATA.URMI.SAMPLE.GDG(0), // DISP=(OLD,DELETE,DELETE)
在上面的示例中,删除了 MYDATA.URMI.SAMPLE.GDG 的最新版本。请注意,正常作业完成时的 DISP 参数编码为 DELETE。因此,作业执行完成后将删除数据集。
可以使用 IDCAMS 删除 GDG 及其相关版本,使用 SYSIN 命令 **DELETE(MYDATA.URMI.SAMPLE.GDG) GDG FORCE/PURGE**。
**FORCE** 删除 GDG 版本和 GDG 基座。如果任何 GDG 版本设置了尚未过期的失效日期,则不会删除这些版本,因此将保留 GDG 基座。
**PURGE** 删除 GDG 版本和 GDG 基座,无论失效日期如何。
在 JCL 中使用 GDG
在以下示例中,将 MYDATA.URMI.SAMPLE.GDG 的最新版本用作程序的输入,并创建一个 MYDATA.URMI.SAMPLE.GDG 的新版本作为输出。
//CNDSAMP JOB CLASS=6,NOTIFY=&SYSUID //* //STP01 EXEC PGM=MYCOBB //IN1 DD DSN=MYDATA.URMI.SAMPLE.GDG(0),DISP=SHR //OUT1 DD DSN=MYDATA.URMI.SAMPLE.GDG(+1),DISP=(,CALTG,DELETE) // LRECL=100,RECFM=FB
这里,如果 GDG 通过实际名称(如 MYDATA.URMI.SAMPLE.GDG.G0001V00)引用,则每次执行前都需要更改 JCL。使用 (0) 和 (+1) 使其动态替换 GDG 版本以进行执行。
输入/输出方法
任何通过 JCL 执行的批处理程序都需要数据输入,对其进行处理并创建输出。有多种方法可以将输入提供给程序并写入从 JCL 收到的输出。在批处理模式下,不需要用户交互,但在 JCL 中定义了输入和输出设备以及所需的组织并提交。
JCL 中的数据输入
有多种方法可以使用 JCL 将数据提供给程序,下面将解释这些方法。
内联数据
可以使用 SYSIN DD 语句为程序指定内联数据。
//CONCATEX JOB CLASS=6,NOTIFY=&SYSUID //* Example 1: //STEP10 EXEC PGM=MYPROG //IN1 DD DSN=SAMPLE.INPUT1,DISP=SHR //OUT1 DD DSN=SAMPLE.OUTPUT1,DISP=(,CATLG,DELETE), // LRECL=50,RECFM=FB //SYSIN DD * //CUST1 1000 //CUST2 1001 /* //* //* Example 2: //STEP20 EXEC PGM=MYPROG //OUT1 DD DSN=SAMPLE.OUTPUT2,DISP=(,CATLG,DELETE), // LRECL=50,RECFM=FB //SYSIN DD DSN=SAMPLE.SYSIN.DATA,DISP=SHR //*
在示例 1 中,通过 SYSIN 将输入传递给 MYPROG。数据在 JCL 中提供。两条数据记录传递给程序。请注意,/* 标记内联 SYSIN 数据的结束。
"CUST1 1000" 是记录 1,"CUST2 1001" 是记录 2。当读取数据时遇到符号 /* 时,将满足数据结束条件。
在示例 2 中,SYSIN 数据保存在数据集内,其中 SAMPLE.SYSIN.DATA 是一个 PS 文件,可以保存一条或多条数据记录。
通过文件输入数据
如前几章的大多数示例中所述,可以通过 PS、VSAM 或 GDG 文件将数据输入提供给程序,并使用相关的 DSN 名称和 DISP 参数以及 DD 语句。
在示例 1 中,SAMPLE.INPUT1 是通过其将数据传递给 MYPROG 的输入文件。它在程序中被引用为 IN1。
JCL 中的数据输出
JCL 中的输出可以编目到数据集中或传递到 SYSOUT。如 DD 语句章节中所述,**SYSOUT=*** 将输出重定向到与 JOB 语句的 MSGCLASS 参数中指定的类相同的类。
保存作业日志
指定 **MSGCLASS=Y** 将作业日志保存在 JMR(作业日志管理和检索)中。整个作业日志可以重定向到 SPOOL,并可以通过在 SPOOL 中针对作业名称发出 XDC 命令将其保存到数据集中。当在 SPOOL 中发出 XDC 命令时,将打开一个数据集创建屏幕。然后,可以通过提供适当的 PS 或 PDS 定义来保存作业日志。
作业日志也可以通过为 SYSOUT 和 SYSPRINT 指定一个已创建的数据集来保存到数据集中。但无法通过这种方式捕获整个作业日志(即 JESMSG 将不会被编目),如在 JMR 或 XDC 中所做的那样。
//SAMPINST JOB 1,CLASS=6,MSGCLASS=Y,NOTIFY=&SYSUID //* //STEP1 EXEC PGM=MYPROG //IN1 DD DSN=MYDATA.URMI.INPUT,DISP=SHR //OUT1 DD SYSOUT=* //SYSOUT DD DSN=MYDATA.URMI.SYSOUT,DISP=SHR //SYSPRINT DD DSN=MYDATA.URMI.SYSPRINT,DISP=SHR //SYSIN DD MYDATA.BASE.LIB1(DATA1),DISP=SHR //* //STEP2 EXEC PGM=SORT
在上面的示例中,SYSOUT 编目在 MYDATA.URMI.SYSOUT 中,SYSPRINT 编目在 MYDATA.URMI.SYSPRINT 中。
使用 JCL 运行 COBOL 程序
编译 COBOL 程序
为了使用 JCL 在批处理模式下执行 COBOL 程序,需要编译程序并创建一个包含所有子程序的加载模块。JCL 在执行时使用加载模块而不是实际程序。加载库被连接起来,并在执行时使用 **JCLLIB** 或 **STEPLIB** 提供给 JCL。
有许多可用的主机编译器实用程序可以编译 COBOL 程序。一些公司使用 Change Management 工具(如 **Endevor**),它编译并存储程序的每个版本。这有助于跟踪对程序所做的更改。
//COMPILE JOB ,CLASS=6,MSGCLASS=X,NOTIFY=&SYSUID //* //STEP1 EXEC IGYCRCTL,PARM=RMODE,DYNAM,SSRANGE //SYSIN DD DSN=MYDATA.URMI.SOURCES(MYCOBB),DISP=SHR //SYSLIB DD DSN=MYDATA.URMI.COPYBOOK(MYCOPY),DISP=SHR //SYSLMOD DD DSN=MYDATA.URMI.LOAD(MYCOBB),DISP=SHR //SYSPRINT DD SYSOUT=* //*
IGYCRCTL 是一个 IBM COBOL 编译器实用程序。编译器选项通过 PARM 参数传递。在上面的示例中,RMODE 指示编译器在程序中使用相对寻址模式。COBOL 程序通过 SYSIN 参数传递,副本库是程序在 SYSLIB 中使用的库。
此 JCL 生成程序的加载模块作为输出,该输出用作执行 JCL 的输入。
运行 COBOL 程序
下面是一个 JCL 示例,其中使用输入文件 MYDATA.URMI.INPUT 执行程序 MYPROG,并生成两个写入卷轴的输出文件。
//COBBSTEP JOB CLASS=6,NOTIFY=&SYSUID // //STEP10 EXEC PGM=MYPROG,PARM=ACCT5000 //STEPLIB DD DSN=MYDATA.URMI.LOADLIB,DISP=SHR //INPUT1 DD DSN=MYDATA.URMI.INPUT,DISP=SHR //OUT1 DD SYSOUT=* //OUT2 DD SYSOUT=* //SYSIN DD * //CUST1 1000 //CUST2 1001 /*
MYPROG 的加载模块位于 MYDATA.URMI.LOADLIB 中。需要注意的是,上述 JCL 只能用于非 DB2 COBOL 模块。
将数据传递给 COBOL 程序
COBOL 批处理程序的数据输入可以通过文件、PARAM 参数和 SYSIN DD 语句进行。在上面的例子中
数据记录通过文件 MYDATA.URMI.INPUT 传递给 MYPROG。此文件将在程序中使用 DD 名称 INPUT1 引用。可以在程序中打开、读取和关闭该文件。
程序 MYPROG 的 LINKAGE 部分接收 PARM 参数数据 ACCT5000,该数据在该部分内定义的变量中。
SYSIN 语句中的数据通过程序的 PROCEDURE 部分中的 ACCEPT 语句接收。每个 ACCEPT 语句将一条完整记录(即 CUST1 1000)读入程序中定义的工作存储变量。
运行 COBOL-DB2 程序
为了运行 COBOL DB2 程序,JCL 和程序中使用了专门的 IBM 实用程序;DB2 区域和所需参数作为输入传递给实用程序。
运行 COBOL-DB2 程序遵循以下步骤
当编译 COBOL-DB2 程序时,除了加载模块之外,还会创建一个 DBRM(数据库请求模块)。DBRM 包含 COBOL 程序的 SQL 语句,并对其语法进行了检查以确保其正确性。
DBRM 绑定到 COBOL 将在其中运行的 DB2 区域(环境)。这可以通过 JCL 中的 IKJEFT01 实用程序来完成。
绑定步骤完成后,使用 IKJEFT01(再次)运行 COBOL-DB2 程序,并将加载库和 DBRM 库作为输入提供给 JCL。
//STEP001 EXEC PGM=IKJEFT01
//*
//STEPLIB DD DSN=MYDATA.URMI.DBRMLIB,DISP=SHR
//*
//input files
//output files
//SYSPRINT DD SYSOUT=*
//SYSABOUT DD SYSOUT=*
//SYSDBOUT DD SYSOUT=*
//SYSUDUMP DD SYSOUT=*
//DISPLAY DD SYSOUT=*
//SYSOUT DD SYSOUT=*
//SYSTSPRT DD SYSOUT=*
//SYSTSIN DD *
DSN SYSTEM(SSID)
RUN PROGRAM(MYCOBB) PLAN(PLANNAME) PARM(parameters to cobol program) -
LIB('MYDATA.URMI.LOADLIB')
END
/*
在上面的示例中,MYCOBB 是使用 IKJEFT01 运行的 COBOL-DB2 程序。请注意,程序名称、DB2 子系统 ID (SSID) 和 DB2 计划名称都传递在 SYSTSIN DD 语句中。DBRM 库在 STEPLIB 中指定。
JCL - 实用程序
IBM 数据集实用程序
实用程序是预先编写的程序,系统程序员和应用程序开发人员广泛用于主机中,以实现日常需求、组织和维护数据。下面列出了一些及其功能。
| 实用程序名称 | 功能 |
|---|---|
| IEHMOVE | 移动或复制顺序数据集。 |
| IEHPROGM | 删除和重命名数据集;编目或取消编目除 VSAM 之外的其他数据集。 |
| IEHCOMPR | 比较顺序数据集中数据。 |
| IEBCOPY | 复制、合并、压缩、备份或恢复 PDS。 |
| IEFBR14 | 无操作实用程序。用于将控制权返回给用户并终止。它通常用于创建空数据集或删除现有数据集。 例如,如果将数据集作为输入传递给具有 DISP=(OLD,DELETE,DELETE) 的 IEFBR14 程序,则在作业完成后将删除该数据集。 |
| IEBEDIT | 用于复制 JCL 的选定部分。例如,如果 JCL 有 5 个步骤,而我们只需要执行步骤 1 和 3,则可以使用包含要执行的实际 JCL 的数据集编码 IEBEDIT JCL。在 IEBEDIT 的 SYSIN 中,我们可以指定 STEP1 和 STEP3 作为参数。当执行此 JCL 时,它将执行实际 JCL 的 STEP1 和 STEP3。 |
| IDCAMS | 创建、删除、重命名、编目、取消编目数据集(除 PDS 之外)。通常用于管理 VSAM 数据集。 |
为了实现指定的功能,这些实用程序需要与 JCL 中的适当 DD 语句一起使用。
DFSORT 概述
DFSORT 是一个功能强大的 IBM 实用程序,用于复制、排序或合并数据集。SORTIN 和 SORTINnn DD 语句用于指定输入数据集。SORTOUT 和 OUTFIL 语句用于指定输出数据。
SYSIN DD 语句用于指定排序和合并条件。DFSORT 通常用于实现以下功能
按文件中指定字段位置的顺序对输入文件进行排序。
根据指定的条件包含或省略输入文件中的记录。
按文件中指定字段位置的顺序对输入文件进行排序合并。
根据指定的 JOIN KEY(每个输入文件中的字段)对两个或多个输入文件进行排序连接。
当需要对输入文件进行额外处理时,可以从 SORT 程序中调用 USER EXIT 程序。例如,如果需要在输出文件中添加标题/尾部,则可以从 SORT 程序中调用用户编写的 COBOL 程序来执行此功能。可以使用控制卡将数据传递给 COBOL 程序。
反过来,可以从 COBOL 程序内部调用 SORT 以在处理前按特定顺序排列输入文件。通常,对于大型文件,不建议这样做,因为这会影响性能。
ICETOOL 概述
ICETOOL 是一个多功能 DFSORT 实用程序,用于对数据集执行各种操作。可以使用用户定义的 DD 名称定义输入和输出数据集。文件操作在 TOOLIN DD 语句中指定。可以在用户定义的“CTL”DD 语句中指定其他条件。
下面列出了一些 ICETOOL 的实用程序
ICETOOL 可以在一项或多项条件下实现 DFSORT 的所有功能。
SPLICE 是 ICETOOL 的一个强大操作,类似于 SORT JOIN,但具有其他功能。它可以根据指定的字段比较两个或多个文件,并创建一或多个输出文件,例如包含匹配记录的文件、包含不匹配记录的文件等。
可以将一个文件中特定位置的数据覆盖到同一文件或不同文件中另一个位置。
一个文件可以根据指定条件拆分为n个文件。例如,包含员工姓名列表的文件可以拆分为26个文件,每个文件包含以A、B、C等字母开头的姓名。
通过对ICETOOL进行一些探索,可以实现多种文件操作的组合。
SYNCSORT概述
SYNCSORT用于以高性能复制、合并或排序数据集。它能够最佳利用系统资源,并在31位和64位地址空间中高效运行。
它可以在与DFSORT相同的行中使用,并且可以实现相同的功能。它可以通过JCL调用,也可以从用COBOL、PL/1或汇编语言编写的程序中调用。它还支持从SYNCSORT程序中调用的用户出口程序。
下一章将解释使用这些实用程序的常用排序技巧。复杂的需要在COBOL/ASSEMBLER中进行大量编程才能实现的需求,可以使用上述实用程序以简单的步骤实现。
JCL - 基本排序技巧
下面说明了企业界中可以使用实用程序实现的日常应用程序需求
1. 一个文件有100条记录。需要将前10条记录写入输出文件。
//JSTEP020 EXEC PGM=ICETOOL //TOOLMSG DD SYSOUT=* //DFSMSG DD SYSOUT=* //IN1 DD DSN=MYDATA.URMI.STOPAFT,DISP=SHR //OUT1 DD SYSOUT=* //TOOLIN DD * COPY FROM(IN1) TO(OUT1) USING(CTL1) /* //CTL1CNTL DD * OPTION STOPAFT=10 /*
STOPAFT选项将在读取第10条记录后停止读取输入文件并终止程序。因此,10条记录被写入输出。
2. 输入文件对同一个员工号有一条或多条记录。将唯一记录写入输出。
//STEP010 EXEC PGM=SORT //SYSOUT DD SYSOUT=* //SORTIN DD DSN=MYDATA.URMI.DUPIN,DISP=SHR //SORTOUT DD SYSOUT=* //SYSIN DD * SORT FIELDS=(1,15,ZD,A) SUM FIELDS=NONE /*
SUM FIELDS=NONE删除在SORT FIELDS中指定的字段中的重复项。在上面的示例中,员工号位于字段位置1,15。输出文件将包含按升序排序的唯一员工号。
3. 覆盖输入记录内容。
//JSTEP010 EXEC PGM=SORT //SORTIN DD DSN= MYDATA.URMI.SAMPLE.MAIN,DISP=SHR //SORTOUT DD SYSOUT=* //SYSPRINT DD SYSOUT=* //SYSOUT DD SYSOUT=* //SYSIN DD * OPTION COPY INREC OVERLAY=(47:1,6) /*
在输入文件中,位置1,6中的内容被覆盖到位置47,6,然后复制到输出文件。为了在复制到输出之前重写输入文件中的数据,使用了INREC OVERLAY操作。
4. 向输出文件添加序列号。
//JSTEP010 EXEC PGM=SORT //SORTIN DD * data1 data2 data3 /* //SORTOUT DD SYSOUT=* //SYSPRINT DD SYSOUT=* //SYSOUT DD SYSOUT=* //SYSIN DD * OPTION COPY BUILD=(1:1,5,10:SEQNUM,4,ZD,START=1000,INCR=2) /*
输出将是
data1 1000 data2 1002 data3 1004
在输出的第10个位置添加4位序列号,从1000开始,每条记录递增2。
5. 向输出文件添加报头/报尾。
//JSTEP010 EXEC PGM=SORT //SORTIN DD * data1 data2 data3 /* //SORTOUT DD SYSOUT=* //SYSPRINT DD SYSOUT=* //SYSOUT DD SYSOUT=* //SYSIN DD * SORT FIELDS=COPY OUTFIL REMOVECC, HEADER1=(1:C'HDR',10:X'020110131C'), TRAILER1=(1:C'TRL',TOT=(10,9,PD,TO=PD,LENGTH=9)) /*
输出将是
HDR 20110131 data1 data2 data3 TRL 000000003
TOT计算输入文件中的记录数。HDR和TRL作为报头/报尾的标识符添加,它们是用户定义的,可以根据用户的需求自定义。
6. 条件处理
//JSTEP010 EXEC PGM=SORT
//SORTIN DD *
data1select
data2
data3select
/*
//SORTOUT DD SYSOUT=*
//SYSPRINT DD SYSOUT=*
//SYSOUT DD SYSOUT=*
//SYSIN DD *
INREC IFTHEN=(WHEN=(6,1,CH,NE,C' '),BUILD=(1:1,15),
IFTHEN=(WHEN=(6,1,CH,EQ,C' '),BUILD=(1:1,5,7:C'EMPTY ')
OPTION COPY
/*
输出将是
data1select data2 EMPTY data3select
根据文件的第6个位置,输出文件的BUILD会发生变化。如果第6个位置为空格,则将文本“EMPTY”附加到输入记录。否则,按原样将输入记录写入输出。
7. 备份文件
//JSTEP001 EXEC PGM=IEBGENER //SYSPRINT DD SYSOUT=* //SYSIN DD * //SYSOUT DD SYSOUT=* //SORTOUT DD DUMMY //SYSUT1 DD DSN=MYDATA.URMI.ORIG,DISP=SHR //SYSUT2 DD DSN=MYDATA.URMI.BACKUP,DISP=(NEW,CATLG,DELETE), // DCB=*.SYSUT1,SPACE=(CYL,(50,1),RLSE)
IEBGENER将SYSUT1中的文件复制到SYSUT2中的文件。请注意,在上面的示例中,SYSUT2中的文件采用与SYSUT1相同的DCB。
8. 文件比较
//STEP010 EXEC PGM=SORT //MAIN DD * 1000 1001 1003 1005 //LOOKUP DD * 1000 1002 1003 //MATCH DD DSN=MYDATA.URMI.SAMPLE.MATCH,DISP=OLD //NOMATCH1 DD DSN=MYDATA.URMI.SAMPLE.NOMATCH1,DISP=OLD //NOMATCH2 DD DSN=MYDATA.URMI.SAMPLE.NOMATCH2,DISP=OLD //SYSOUT DD SYSOUT=* //SYSIN DD * JOINKEYS F1=MAIN,FIELDS=(1,4,A) JOINKEYS F2=LOOKUP,FIELDS=(1,4,A) JOIN UNPAIRED,F1,F2 REFORMAT FIELDS=(?,F1:1,4,F2:1,4) OPTION COPY OUTFIL FNAMES=MATCH,INCLUDE=(1,1,CH,EQ,C'B'),BUILD=(1:2,4) OUTFIL FNAMES=NOMATCH1,INCLUDE=(1,1,CH,EQ,C'1'),BUILD=(1:2,4) OUTFIL FNAMES=NOMATCH2,INCLUDE=(1,1,CH,EQ,C'2'),BUILD=(1:2,4) /*
JOINKEYS指定比较两个文件的字段。
REFORMAT FIELDS=?将'B'(匹配的记录)、'1'(存在于文件1中,但不存在于文件2中)或'2'(存在于文件2中,但不存在于文件1中)放置在输出BUILD的第1个位置。
JOIN UNPAIRED对两个文件进行全外部联接。
输出将是
MATCH File 1000 1003 NOMATCH1 File 1001 1005 NOMATCH2 File 1002
使用ICETOOL也可以实现相同的功能。